
机器学习——KNN算法
近邻算法(KNN)属于有监督学习的聚类算法,他可以通过测量不同特征值之间的距离进行分类,一个样本在特征空间中的k个最相似的样本大多数属于某一个类别,则该样本也属于这个类别,算法中所选择的邻居都是正确分类的对象。KNN算法测距离依旧使用的是欧式距离。
算法描述:
计算测试数据与各个训练数据之间的距离;
按照距离的递增关系进行排序;
选取距离最小的K个点;
确定前K个点所在的类别的出现频率;
返回前K个点出现频率最高的类别作为测试数据的预测分类。
Python中的实现
以鸢尾花为例
import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.datasets import load_iris if __name__ == '__main__': datas=load_iris() print(datas) #准备一个乱数的下标序列号 index=np.arange(150) np.random.shuffle(index) #根据给定的乱序的下标到对应的数组中提取对应的数据 train,test=datas.data[index[:100]],datas.data[index[100:]] #训练集和测试集 train_target,real_target=datas.target[index[:100]],datas.target[index[100:]] #训练模型 knn=KNeighborsClassifier(n_neighbors=5) knn.fit(train,train_target) #模型评估 res=knn.predict(test) print(res) print('-------------------') print(real_target) print('--------------') print(1-abs(res-real_target).sum()/len(res))
通过对比预测值res和实际值,可以得到准确度为:0.98
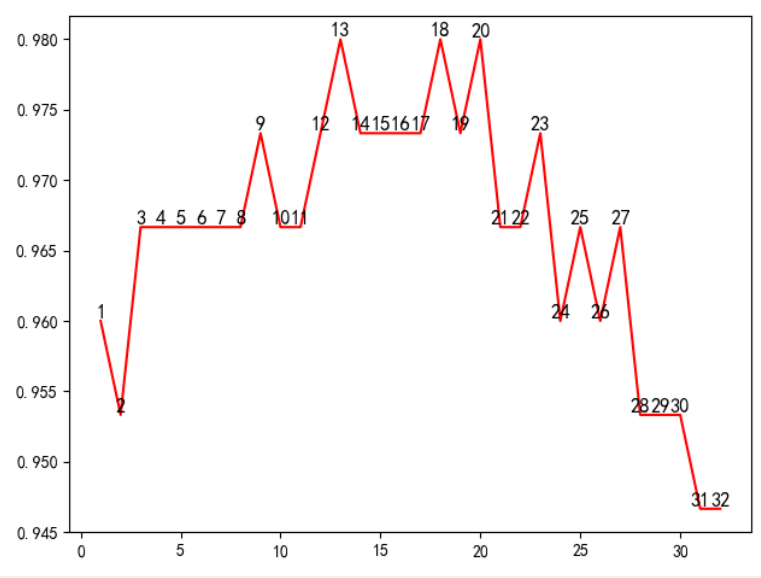
而K值是自己定的,而不能确定是否是最优的情况,可以使用matplotlib进行作图调优,给定K的范围为(1,33)
import numpy as np from sklearn.neighbors import KNeighborsClassifier from sklearn.datasets import load_iris from sklearn.model_selection import cross_val_score import matplotlib import matplotlib.pyplot as plt if __name__ == '__main__': matplotlib.rcParams['font.sans-serif'] = ['SimHei'] datas=load_iris() train,target=datas.data,datas.target neigh=np.arange(1,33) y=[] for i in neigh: knn=KNeighborsClassifier(n_neighbors=i) #cross_val_score 交叉验证模型 提高精确度 ms=cross_val_score(knn,train,target,cv=10,scoring='accuracy').mean() #平均值 y.append(ms) plt.plot(neigh,y,'r') for x1,y1 in zip(neigh,y): plt.text(x1,y1,str(x1),ha='center',va='bottom',fontsize=12,rotation=0) plt.show()
得到一个精确度的折线图如下,由图选取最佳的K值再参与计算,提高KNN算法的准确性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号