
RDD——弹性分布式数据集
RDD是将数据项拆分为多个分区的集合,储存在集群的工作节点上的内存和磁盘上,RDD是用于数据转换的接口,其不存实际数据内容
RDD的特点:
弹性:RDD默认存放在内存中,当内存不足时,Spark自动将RDD写入磁盘
容错性:根据数据血统,可以自动从节点失败中恢复分区
分布式数据集:RDD为只读的分区记录集合,每个分区分布在不同节点上
RDD的分区特点决定它属于分布式数据集
分区越多,则得到的并行性就越强;
每个分区都是被分发到不同的worker node的候选者
每一个分区对应一个task
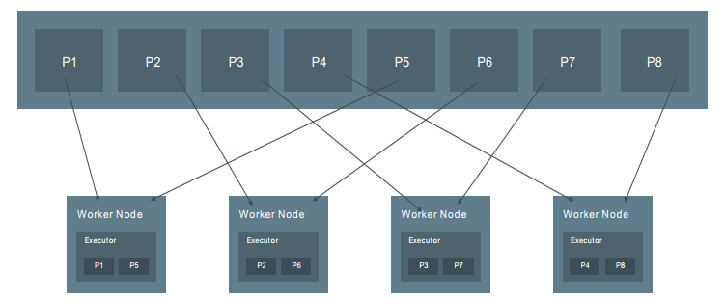
关于RDD的分区方式,可以分为以下三种:
默认的情况下,为范围分区
val conf = new SparkConf().setMaster("local[8]").setAppName("job") val sc = new SparkContext(conf) val rdd = sc.parallelize(List(1,2,3,4,5,6,7,8),2) //范围分区 rdd.foreachPartition(x=>println(x.toList)) //List(1, 2, 3, 4) List(5, 6, 7, 8)
当需要使用Hash分区时,RDD内的数据类型必须为键值对,同时需要调用grouyBy或reduceByKey方法
//类型为键值对,但仍属于范围分区 rdd.map((_,1)).foreachPartition(x=>println(x.toList)) //List((5,1), (6,1), (7,1), (8,1)) List((1,1), (2,1), (3,1), (4,1)) //Hash分区 rdd.map((_,1)).groupByKey(2).foreachPartition(x=>println(x.toList)) //List((1,CompactBuffer(1)), (3,CompactBuffer(1)), (7,CompactBuffer(1)), (5,CompactBuffer(1))) List((4,CompactBuffer(1)), (6,CompactBuffer(1)), (8,CompactBuffer(1)), (2,CompactBuffer(1)))
自定义分区方式
//对于自定义的分区,需要继承Partitioner //自定义方法如下: class MyPartition(numPartition:Int) extends Partitioner{ override def numPartitions: Int = { numPartition } override def getPartition(key: Any): Int = { if (key.asInstanceOf[Int]<3) 0 else if (key.asInstanceOf[Int]>=6) 1 else 2 } } //自定义分区 rdd.map((_,1)).partitionBy(new MyPartition(3)).foreachPartition(x=>println(x.toList)) //List((6,1), (7,1), (8,1)) List((3,1), (4,1), (5,1)) List((1,1), (2,1))
对于已经定义了分区方式的RDD,也可以重新进行分区,调用方法 repartition()或coalesce(),其中repartition是coalesce接口中shuffle为true的实现
假设源RDD分区为N,现在重新分区需要M
当N<M时,即重新定义的分区数变多,通常使用方法repartition,因为其默认为shuffle为true的实现,若是调用coalesce(N,false),不经过shuffle,是无法将RDD的分区数变多
当N>M时且数量级相近,可以将N个分区的若干分区合并为一个新的分区,最终为M个,这时可以将shuffle设置为false,能有效提高效率
当N>M且数量级相差较大时,当进程数<=分区数,coalesce效率高,为了有更好的并行度,可以将shuffle设置为true

 浙公网安备 33010602011771号
浙公网安备 33010602011771号