分布式ID生成方案
分布式ID策略
为什么要用分布式ID?
在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个 MySQL 主从同步读写分离也能对付。
但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;特别一点的如订单、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
分布式ID要满足什么特性?
唯一性:必须保证ID是全局性唯一的,这是基本要求;
高性能:高可用低延时,ID生成响应要块,否则反倒会成为业务瓶颈;
高可用:需要保证高并发下的可用性。除了对 ID 号码自身的要求,业务还对 ID 生成系统的可用性要求极高;
递增性:生成的 ID 需要按照某种规则有序,便于数据库的写入和排序操作;
安全性:
- id的规律性太明显,用户就会知晓该店铺每天的订单量,暴露隐私;
- 受单表数据量的限制,订单的数据量较大,订单量随着时间会不断增大,如果订单量已经达到了上亿,那单张表保存不了这么庞大的数据。如果分为多张表来保存订单数据,多张表订单ID都是从1开始增长,那ID一定会出现重复。
分布式ID生成方式有哪些?
1、UUID
UUID,它有着全球唯一的特性。UUID可以做分布式ID,但并不推荐使用。
UUID 的标准形式为 32 个十六进制数组成的字符串,且分割为五个部分
String uuid = UUID.randomUUID().toString().replaceAll("-","");;
UUID的生成简单到只有一行代码,输出结果 2fedcf5e38ac4bf78f6ab6035005eea2,但UUID却并不适用于实际的业务需求。像用作订单号UUID这样的字符串没有丝毫的意义,看不出和订单相关的有用信息;而对于数据库来说,用作业务主键ID,它不仅太长而且还是字符串,存储性能差,查询也很耗时,所以不推荐用作分布式ID。
优点:
生成足够简单,本地生成无网络消耗,具有唯一性;
缺点:
- 无序的字符串;
- 没有具体的业务含义;
- 长度过长,16 字节128位,36位长度的字符串(加上四个“-”),存储以及查询对MySQL的性能消耗较大。(MySQL官方明确建议主键尽量越短越好,作为数据库主键
UUID的无序性会导致数据位置频繁变动,严重影响性能);
2、数据库自增ID
基于数据库的auto_increment自增ID完全可以充当分布式ID,在数据库内可以保证唯一。
优点:
实现简单,ID单调自增,数值类型查询速度快;
缺点:
DB单点存在宕机风险,无法扛住高并发场景,因为数据库要承载每秒几万并发,肯定是不现实的。
3、数据库集群自增ID
上面的单点数据库方式不可取,那对上边的方式做一些高可用优化,换成主从模式集群。害怕一个主节点挂掉没法用,那就做双主模式集群,也就是两个 Mysql 实例都能单独的生产自增ID。
那这样还会有个问题,两个MySQL实例的自增ID都从1开始,会生成重复的ID怎么办?
解决方案:设置不同的起始值和相同的自增步长
举个例子:
# MySQL_1 配置
set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 3; -- 步长
# MySQL_2 配置
set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 3; -- 步长
# MySQL_3 配置
set @@auto_increment_offset = 3; -- 起始值
set @@auto_increment_increment = 3; -- 步长
这样两个MySQL实例的自增ID分别就是:
1、4、7、10...
2、5、8、11...
3、6、9、12...
但是存在一个问题,如果后续需要扩展集群,增加一台MySQL机器,就需要修改前3台MySQL实例的起始值和步长。
优点:
解决DB单点问题;
缺点:
不利于后续扩容,而且实际上单个数据库自身压力还是大,依旧无法满足高并发场景。
4、Redis自增ID
string有自增特性,能够确保唯一性,利用redis的 incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF:
RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况;AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
5、雪花算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法。
相比 UUID 无序生成的id而言,雪花算法是有序的,而且都是由数字组成。雪花id最大为64位,符合java中long的长度64位,抛去一位符号位,那么最大为263。
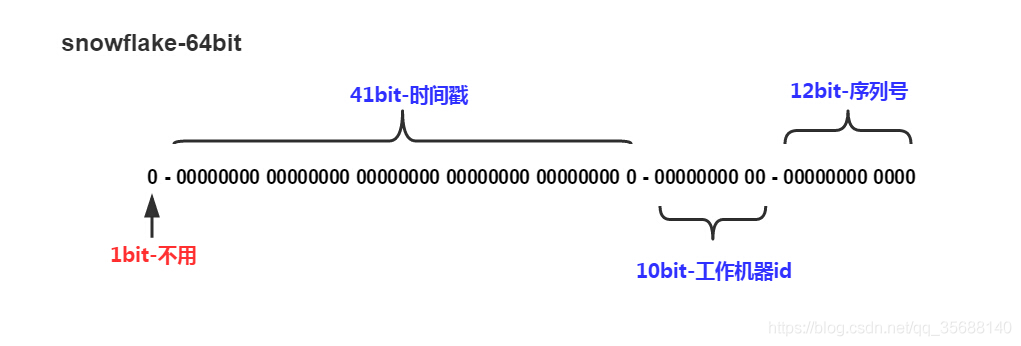
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 数据中心(机房)(占5比特)+ 机器ID(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。
- 第一个bit位(1bit):Java中long的最高位是符号位代表正负,正数是0,负数是1,一般生成ID都为正数,所以默认为0;
- 时间戳部分(41bit):毫秒级的时间,不建议存当前时间戳,而是用(当前时间戳 - 固定开始时间戳)的差值,可以使产生的ID从更小的值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年
- 工作机器id(10bit):也被叫做
workId,这个可以灵活配置,机房或者机器号组合都可以; - 序列号部分(12bit),自增值支持同一毫秒内同一个节点可以生成
2^12 = 4096个ID;
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。
改进:
在生成唯一id的时候,一般都需要指定一个表名,比如说订单表的唯一id。所以上面那64个bit中,代表机房的那5个bit,可以使用业务表名称来替代,比如用00001代表的是订单表。因为其实很多时候,机房并没有那么多(大厂除外),所以前5个bit用做机房id可能意义不是太大。
这样就可以做到,snowflake算法系统的每一台机器,对一个业务表,在某一毫秒内,可以生成一个唯一的id,一毫秒内生成很多id,用最后12个bit来区分序号对待。
Java版本的雪花算法实现:
/**
* Twitter的SnowFlake算法,使用SnowFlake算法生成一个整数,然后转化为62进制变成一个短地址URL
*
* https://github.com/beyondfengyu/SnowFlake
*/
public class SnowFlakeShortUrl {
/**
* 起始的时间戳
*/
private final static long START_TIMESTAMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATA_CENTER_BIT = 5; //数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT);
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);
/**
* 每一部分向左的位移
*/
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
private long dataCenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastTimeStamp = -1L; //上一次时间戳
private long getNextMill() {
long mill = getNewTimeStamp();
while (mill <= lastTimeStamp) {
mill = getNewTimeStamp();
}
return mill;
}
private long getNewTimeStamp() {
return System.currentTimeMillis();
}
/**
* 根据指定的数据中心ID和机器标志ID生成指定的序列号
*
* @param dataCenterId 数据中心ID
* @param machineId 机器标志ID
*/
public SnowFlakeShortUrl(long dataCenterId, long machineId) {
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0) {
throw new IllegalArgumentException("DtaCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0!");
}
if (machineId > MAX_MACHINE_NUM || machineId < 0) {
throw new IllegalArgumentException("MachineId can't be greater than MAX_MACHINE_NUM or less than 0!");
}
this.dataCenterId = dataCenterId;
this.machineId = machineId;
}
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId() {
long currTimeStamp = getNewTimeStamp();
if (currTimeStamp < lastTimeStamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (currTimeStamp == lastTimeStamp) {
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L) {
currTimeStamp = getNextMill();
}
} else {
//不同毫秒内,序列号置为0
sequence = 0L;
}
lastTimeStamp = currTimeStamp;
return (currTimeStamp - START_TIMESTAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
}
public static void main(String[] args) {
SnowFlakeShortUrl snowFlake = new SnowFlakeShortUrl(2, 3);
for (int i = 0; i < (1 << 4); i++) {
//10进制
System.out.println(snowFlake.nextId());
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号