机器学习常用指标
一、机器学习常用指标
对于一个分类任务,我们预测情况大致如下面混淆矩阵所示:
| 预测为正样本 | 预测为负样本 | |
|---|---|---|
| 标签为正样本 | TP | FN |
| 标签为负样本 | FP | TN |
1、accuracy
accuracy指的是正确预测的样本数占总预测样本数的比值,它不考虑预测的样本是正例还是负例,考虑的是全部样本。

2、precision(查准率)
precision指的是正确预测的正样本数占所有预测为正样本的数量的比值,也就是说所有预测为正样本的样本中有多少是真正的正样本。从这我们可以看出,precision只关注预测为正样本的部分。(第一列)
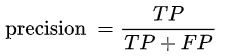
3、recall(召回率)
recall指的是正确预测的正样本数占真实正样本总数的比值,也就是我能从这些真实正样本中能够正确预测出多少个正样本。(第一行)
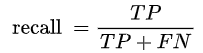
4、F-score
F-score相当于precision和recall的调和平均,用意是要参考两个指标。从公式我们可以看出,recall和precision任何一个数值减小,F-score都会减小,反之,亦然。
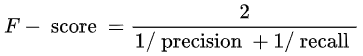
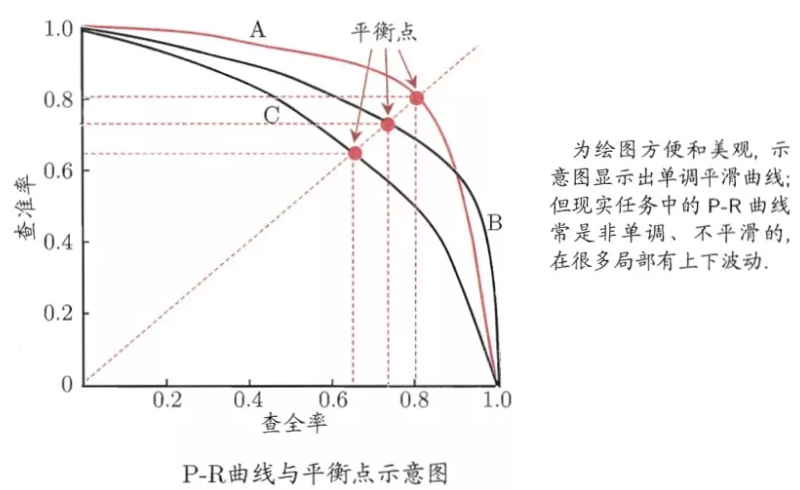
5、P-R曲线
将纵轴设置为precison,横轴设置成recall,改变阈值就能获得一系列的pair并绘制出曲线。对于不同的模型在相同数据集上的预测效果,我们可以画出一系列的PR曲线。一般来说如果一个曲线完全“包围”另一个曲线,我们可以认为该模型的分类效果要好于对比模型。
二、目标检测指标汇总
目标检测常用指标如下:

1、计算某个类的AP
- 要计算某个类别的AP值,首先需要计算TP、FP(实际为负例但预测为正例,即误检)、FN(实际为正例但预测为负例,即漏检)。
- 拿单张图片来说,首先遍历该图片中的gt目标,提取我们要计算的某个类别(如自行车)的gt objects,然后读取我们通过检测器预测出的这种类别(如自行车)的检测框(其他类别的先不管)。
- 接着过滤掉前背景置信度低于设置的置信度阈值的预测框。将剩下的预测框按照置信度分数从高到低排序,最先判断置信度分数最高的预测框与GT box的IoU值是否大于预设的IoU阈值。
- 若大于IoU阈值,则设定当前预测框为TP,将此GT box(如自行车)标记为已检测(后续的同一个GT的多余预测框都视为FP,这就是为什么先要按照置信度分数从高到低排序,置信度分数最高的检测框最先去与IoU阈值比较,若大于IoU阈值,视为TP,后续的同一个GT对象的预测框都视为FP)
- 若小于IoU阈值,则设定当前预测框为FP。
- 一张图片中,某类别一共有多少个GT(如自行车)是固定的,减去TP的个数,剩下的就是FN的个数。
- 当有了TP、FP、FN后,我们就可以计算这一类别(如自行车)的precision与recall,从而计算该类别的AP。
- 在 PASCAL- VOC2010以前,只需要选取当 Recall>=0,0.1,0.2,...0.9,1.0 共11个点时的Precision最大值,然后AP就是这11个Precision的平均值;
- 在 PASCAL- VOC2010以后,需要针对每一个不同的\(Recall\)值(包括0和1),选取其大于等于这些Recall值时的Precision最大值,然后计算PR曲线下面积作为AP值;
- COCO数据集,设定多个IoU阈值(0.5~0.95,0.05为步长),在每一个IoU阈值下都有某一个类别的AP值,然后求不同IoU阈值下的AP平均,就是所求的最终的某类别的AP值。
2、mAP计算
当把所有类别的AP值求出来,取平均值就是mAP.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号