

dotnet体系结构
一.C#与.NET的关系
1.粗略地説,.net是一种在Windows平台上的编程架构————一种API。
2.C#编译器专门用于.net,这表示用C#编写的所有代码总是使用.NET Framework运行。
3.C#的体系结构和方法论反映了.NET基础方法论,许多情况下,C#的特定语言功能取决于.net的功能,或依赖于.net基类。
二.C#概述
1.C#是一门基于现代面向对象设计方法的编程语言,是专门为与Microsoft的.NET Framework一起使用而设计的。
2.C#尽管是用于生成面向.net环境的代码,但它本身不是.net的一部分。.net支持的一些特性,C#并不支持。而C#支持的另一些特性,.net却不支持(如运算符重载)。
3.C#的局限性:不适用于编写时间急迫或性能非常高的代码。比如需要立即清理垃圾。
三..net体系
1.公共语言运行库(CLR)
.NET Framework的核心是运行库执行环境,称为公共语言运行库(CLR)或.NET运行库。通常将在CLR控制下运行的代码称为托管代码(managed code)。
在CLR执行编写好的源代码之前,需要编译源代码。.net中编译需要分为两个阶段:
(1)将源代码编译为Microsoft中间语言(IL)
(2)CLR把IL编译为平台专用的代码
2.中间语言(IL)
这两个阶段的编译过程都很重要,因为IL是提供.net的许多优点的关键。
IL和Java字节码共享是一种理念:他们都是低级语言,语法很简单(使用数字代码,而不是文本代码),可以非常快速地转换为本地机器码。
对于这种精心设计通用语法的优点有:平台无关性,提高性能和语言的互操作行。
(1)平台无关性
包含字节码指令的同一文件可以放在任一平台中,运行时,编译过程的最后阶段很轻松就可以完成,这样代码就可以运行在特定的平台上。换句话説,编译为中间语言就可以获得.net平台无关性。例如Mono。
(2)提高性能
IL是即时编译(JIT),JIT编译器并不是把整个应用程序一次编译完(这样会有很长的启动时间),而是只编译它调用的那部分代码。代码编译过一次后,得到的本地可执行程序就存储起来,这样在下次运行
这部分代码时,就不需要重新编译了。Microsoft认为这个过程要比一开始就编译整个应用程序代码的效率高得多,因为任何应用程序的大部分代码实际上并不是在每次运行都执行。这解释了为什么托管IL代码几乎
和本地代码的执行速度一样快。
为什么Microsoft认为这会提高性能呢?原因是编译过程的最后一部分是在运行时进行的,JIT编译器确切的知道程序运行在什么类型的处理器上,可以利用该处理器提供的任何特性或特定的机器代码指令来优化
最后的可执行代码。传统的编译器也会优化代码,但它的优化过程是独立于运行代码的特定处理器的。因为传统的编译器是在发布软件之前编译为本地机器可执行的代码,即编译器不知道运行代码的处理器的类型。
(3)语言的互操作性
使用IL不仅支持平台无关性,还支持语言的互操作性。简单的说就是能将任何一种语言编译为中间语言,编译为中间语言的代码可以与从其他语言编译过来的代码进行交互操作。(例如VB,C++,F#,COM,COM++,
Windows运行库)
中间语言显然在.net framework中起着很重要的作用,下面讨论一下IL的主要特征:
(1)面向对象和接口的支持
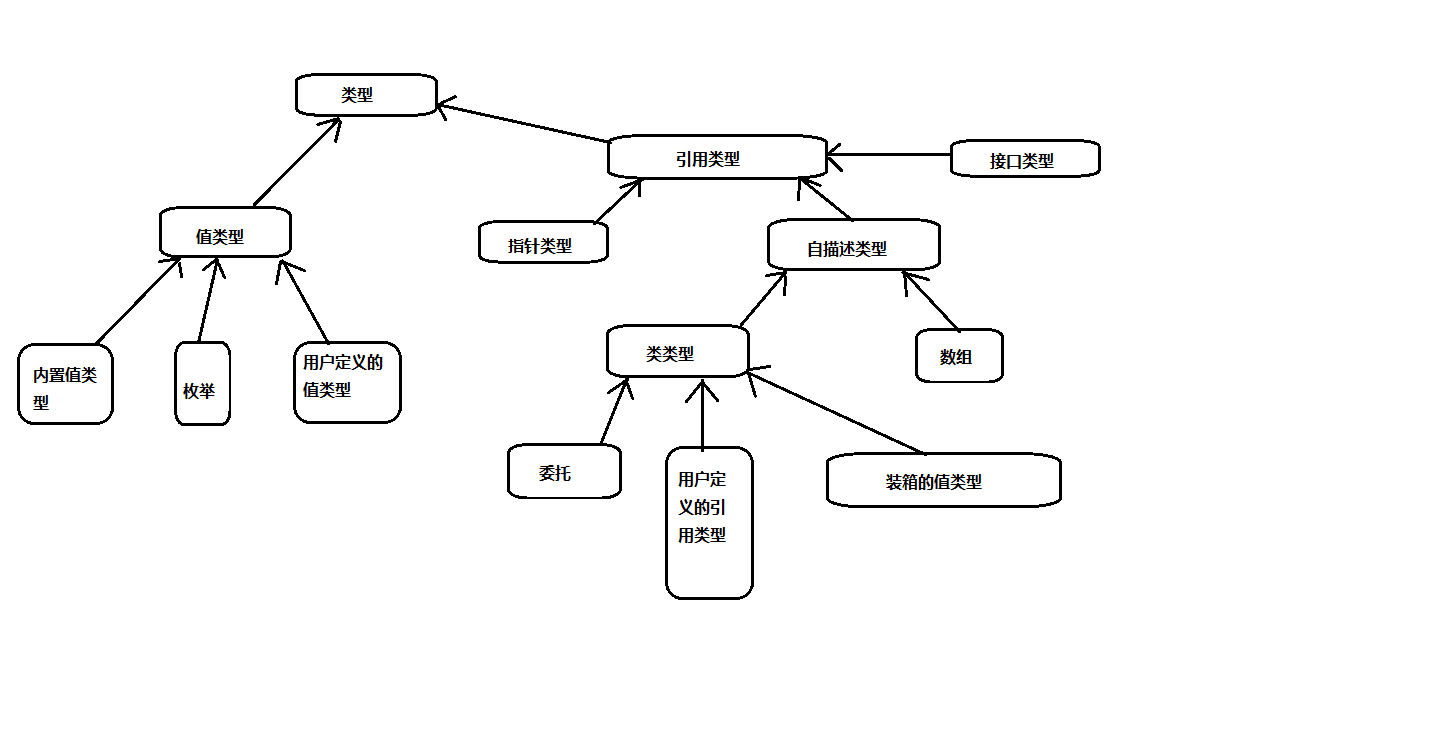
(2)值类型和引用类型之间的显著差异
中间语言提供了许多预定义的基本数据类型。它的一个特性是值类型和引用类型之间有明显的区别。对于值类型(value type),变量直接存储数据,而对于引用类型(reference type),变量仅存储地址,
对应的地址存储数据。
中间语言也有数据存储的规范:引用类型实例总是存储在一个名为“托管堆”的内存区域中,值类型一般存储在堆栈中(但如果值类型在引用类型中声明为字段,它们就内联存储在堆中,后面会详细讨论)
(3)强数据类型化
IL是基于强数据类型化,所有的变量都清洗的标记为属于某个特定数据类型。特别是中间语言一般不允许对模糊的数据类型执行任何操作。VB开发人员习惯于传递变量而无需考虑它们的类型。因为VB会进行所需的
类型转换。C++开发人员习惯在不同类型之间转换指针类型。执行这类操作将极大的提高性能,但破坏了类型安全。因此在某些编译为托管代码的语言中,这类操作只能在特殊情况下进行。指针只能在标记了的C#
代码中使用。
尽管强迫实现类型的安全性似乎会降低性能,但从.NET提供的依赖于类型安全的服务中获得的好处更多。包括:
*语言的互操作性
如果类派生自其它类,或包含其他类的实例,就需要知道其他类使用的所有数据类型,这就是强数据类型化重要的原因。过去由于缺少用于指定这类信息的一致的系统,从而成为语言继承和交互操作的真正障碍。
加入VB2013类中的一个方法定义返回一个Integer,但C#没有该名称的数据类型。显然只有只有编译器知道怎么把VB2013的Integer类型映射为C#定义的某种已知类型,才能使用这个方法,并在C#代码中使用返回
的类型。这在.NET 中是怎么解决的呢?!!!通用类型系统(CTS),公共语言规范(CLS)
通用类型系统(CTS)定义了可以在中间语言中使用的预定义数据类型,所有面向.NET Framework的语言都可以生成最终基于这些类型的编译代码。对于上面的例子,VB2013的Integer实际上是一个32位符号的整数,
它映射为中间语言类型Int32.因此在中间语言代码中就指定这种数据类型。这样C#用关键字int来表示Int32,所以编译器就认为VB2013方法返回一个int类型的值。
CTS不仅指定了基本数据类型,还定义了一个内容丰富的类型层次结构,其中包含设计合理位置,在这些位置上,代码允许定义它自己的类型。CTS的层次结构反映了中间语言的单一继承的面向对象方法。
后面会介绍内置的所有值类型。在C#中,编译器识别的每个预定义类型都映射为一个IL内置类型。
公共语言规范(CLS)和通用类型系统一起确保了语言的互操作性。CLS是一个最低标准集,所有面向.NET的编译器都必须支持它。因为IL是一种内涵非常丰富的语言,大多数编译器的编写人员有可能把给定编译器
的功能限制为只支持IL和CTS提供的一部分功能,只要编译器支持已在CLS中定义的内容就很不错了。
举个例子,IL是区分大小写的语言,使用这些语言的开发人员常常利用区分大小写所提供的灵活性来选择变量名。但VB2013是不区分大小写的。CLS通过指定CLS兼容代码不适应任何只根据大小写来区分的名称,解决
了这个问题。
CLS的两种工作方式:
1.各个编译器的功能不必强大到支持.NET 的所有功能,这将鼓励人们为其它面向.NET 的编程语言开发编译器。
2.如果限制类只能使用CLS兼容的特性,就要保证用其它兼容语言编写的代码可以使用这个类。
因此使用CLS兼容特性的限制只适用于公共和受保护的类成员和公共类。在类的私有实现方式中,可以编写非CLS代码,因为其它程序集中的代码不能访问这部分代码。
一般情况下,CLS对C#代码的影响不会太大,因为C#中的非CLS兼容特性非常少。编写非CLS兼容代码是完全可以接受的,只是在编写了这种代码之后,就不能保证编译好的IL代码完全支持语言的互操作性。
×垃圾回收(后面讨论)
×安全性(后面讨论)
×应用程序域(后面讨论)
使用特性(attribute)(后面讨论)
博客编写中可能存在错误,欢迎读者指正批评,邮箱15734108350@163.com.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具