
# 机器学习算法总结-第六天(Adaboost算法)
SKlearn中的Adaboost使用









主要调的参数:第一部分是对我们的Adaboost的框架进行调参, 第二部分是对我们选择的弱分类器进行调参。
使用 Adaboost 进行手写数字识别
导入库,载入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import cross_val_predict
from sklearn.model_selection import train_test_split
from sklearn.model_selection import learning_curve
from sklearn.datasets import load_digits
dataset = load_digits()
X = dataset['data']
y = dataset['target']
看下图像:
使用深度为 1 的决策树分类器,准确率是0.2641850696745583
reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=1))
scores_ada = cross_val_score(reg_ada, X, y, cv=6)
scores_ada.mean()
通过调节决策树的深度,提高识别准确率
score = []
for depth in [1,2,10] :
reg_ada = AdaBoostClassifier(DecisionTreeClassifier(max_depth=depth))
scores_ada = cross_val_score(reg_ada, X, y, cv=6)
score.append(scores_ada.mean())
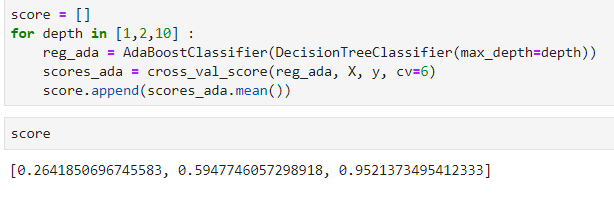
当决策树的深度为 10 时,分类器得到了最高的分类准确率 95%
详细参数参考下面这篇链接:
https://www.cnblogs.com/pinard/p/6136914.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号