


DDR地址、容量计算、Bank理解
DDR3 地址线
DDR3为减少地址线,把地址线分为行地址线和列地址线,在硬件上是同一组地址线;
地址线和列地址线是分时复用的,即地址要分两次送出,先送出行地址,再送出列地址。
一般来说列地址线是10位,及A0...A9;行地址线数量根据内存大小,BANK数目,数据线位宽等决定(感觉也应该是行地址决定其他) ;BANK
bank是存储库的意思,也就是说,一块内存内部划分出了多个存储库,访问的时候指定存储库编号,就可以访问指定的存储库,内存中划分了多少个bank,要看地址线中有几位BA地址,如果有两位,说明有4个bank,如果有3位,说明有8个bankDDR3 容量计算
下面这张图是芯片k4t1g164qf资料中截取的;以1Gb容量的DDR2颗粒为例(其他的类似);假设数据线位宽为16位,则看64Mb x 16这一列:bank地址线位宽为3,及bank数目为 2^3=8;
行地址线位宽位13,及A0…A12;
列地址线位宽为10,及A0…A9;
有 2^3 * 2^13 * 2^10 = 2^26 =2^6Mb = 64Mb
再加上数据线,则容量为 64Mb x 16 = 128M Byte = =1G bit
对于4Gb的16bit DDR3,
bank address有三个bit,所以单个16bit DDR3内部有8个bank.
表示行的有A0~A14,共15个bit,说明一个bank中有2^15个行。
表示列的有A0~A9,共10个bit,说明一个bank中有2^10个行。
来看看单块16bit DDR3容量:
2^3*2^15*2^10=2^28=256M
我们的内存是512M,到这儿怎么变成256M了?被骗了?
呵呵,当然没有。
忘了我们前面一直提到的16bit。
16bit是2个byte对吧。
访问一个地址,内存认为是访问16bit的数据,也就是两个字节的数据。
256M个地址,也就是对应512M的数据了。
再来看看两个16bit是如何组成一个32bit的。
有一个概念一定要清楚,这儿所说的两个16bit组成一个32bit,指的是数据,与地址没有关系。
我开始这一块没搞清楚,一直认为是两个16bit的地址组成了一个32bit的地址。然后高位地址,地位地址,七七八八。。。
之后没一点头绪。
将16bit/32bit指的是数据宽度之后,就非常明了了。
每一块16bit DDR3中有8个bank,2^15个row,2^10个column。也就是有256M个地址。
看前面的连线可知,两块16bit DDR3的BA0~BA2和D0~D14其实是并行连接到CPU。
也就是说,CPU其实认为只有一块内存,访问的时候按照BA0~BA2和D0~D14给出地址。
两块16bit DDR3都收到了该地址。
它们是怎么响应的呢?
两块内存都是16bit,它们收到地址之后,给出的反应是要么将给定地址上2个字节送到数据线上,要么是将数据线上的两个字节写入到指定的地址。
再看数据线的连接,第一片的D0~D15连接到了CPU的D0~D15,第二片的D0~D15连接到了CPU的D16~D31。
CPU认为自己访问的是一块32bit的内存,所以CPU每给出一个地址,将访问4个字节的数据,读取/写入。
这4字节数据对应到CPU的D0~D31,又分别被连接到两片内存的D0~D15,这样一个32bit就被拆成了两个16bit.
反过来,也就是两个16bit组成了一个32bit.
CPU访问的内存地址有256M个,每访问一个地址,将访问4个字节,这样CPU能访问的内存即为1GB。
DDR3的内部是一个存储阵列,将数据“填”进去,你可以它想象成一张表格。和表格的检索原理一样,先指定一个行(Row),再指定一个列(Column),我们就可以准确地找到所需要的单元格,这就是内存芯片寻址的基本原理。对于内存,这个单元格可称为存储单元,那么这个表格(存储阵列)就是逻辑 Bank(Logical Bank,下面简称Bank)。
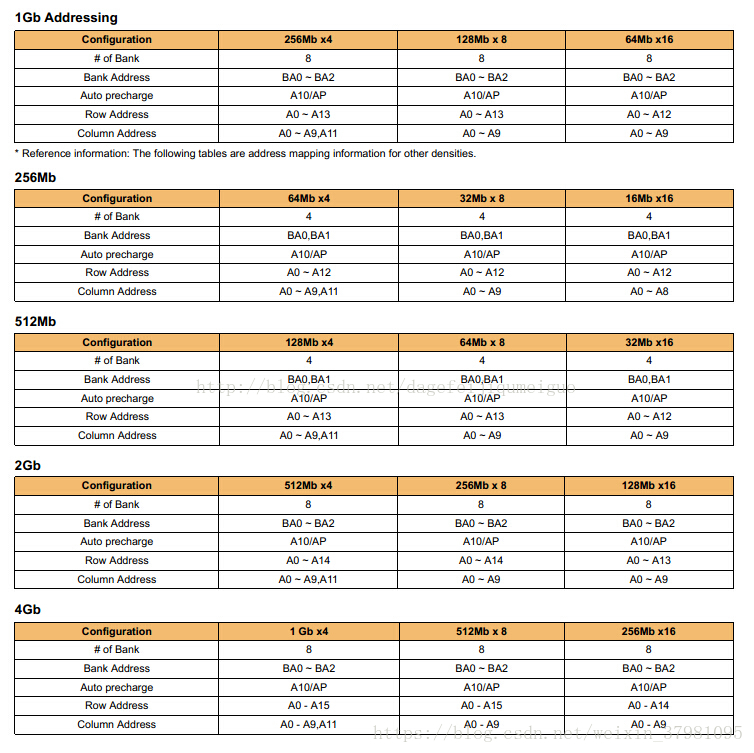
DDR3内部Bank示意图,这是一个NXN的阵列,B代表Bank地址编号,C代表列地址编号,R代表行地址编号。
如果寻址命令是B1、R2、C6,就能确定地址是图中红格的位置
目前DDR3内存芯片基本上都是8个Bank设计,也就是说一共有8个这样的“表格”。
寻址的流程也就是先指定Bank地址,再指定行地址,然后指列地址最终的确寻址单元。
目前DDR3系统而言,还存在物理Bank的概念,这是对内存子系统的一个相关术语,并不针对内存芯片。内存为了保证CPU正常工作,必须一次传输完CPU 在一个传输周期内所需要的数据。
而CPU在一个传输周期能接受的数据容量就是CPU数据总线的位宽,单位是bit(位)。
控制内存与CPU之间数据交换的北桥芯片也因此将内存总线的数据位宽等同于CPU数据总线的位宽,这个位宽就称为物理Bank(Physical Bank,有的资料称之为Rank)的位宽。目前这个位宽基本为64bit。
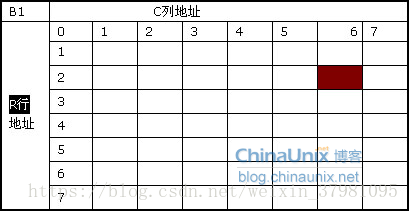
在实际工作中,Bank地址与相应的行地址是同时发出的,此时这个命令称之为“行激活”(Row Active)。在此之后,将发送列地址寻址命令与具体的操作命令(是读还是写),这两个命令也是同时发出的,所以一般都会以“读/写命令”来表示列寻址。根据相关的标准,从行有效到读/写命令发出之间的间隔被定义为tRCD,即RAS to CAS Delay(RAS至CAS延迟,RAS就是行地址选通脉冲,CAS就是列地址选通脉冲),我们可以理解为行选通周期。tRCD是DDR的一个重要时序参数,广义的tRCD以时钟周期(tCK,Clock Time)数为单位,比如tRCD=3,就代表延迟周期为两个时钟周期,具体到确切的时间,则要根据时钟频率而定,DDR3-800,tRCD=3,代表30ns的延迟。
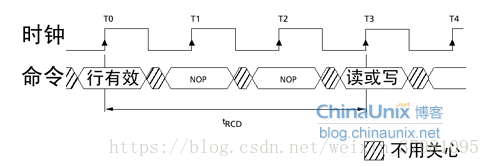
接下来,相关的列地址被选中之后,将会触发数据传输,但从存储单元中输出到真正出现在内存芯片的 I/O 接口之间还需要一定的时间(数据触发本身就有延迟,而且还需要进行信号放大),这段时间就是非常著名的 CL(CAS Latency,列地址脉冲选通潜伏期)。CL 的数值与 tRCD 一样,以时钟周期数表示**。
如 DDR3-800,时钟频率为 100MHz,时钟周期为 10ns,如果 CL=2 就意味着 20ns 的潜伏期。
不过CL只是针对读取操作。
由于芯片体积的原因,存储单元中的电容容量很小,所以信号要经过放大来保证其有效的识别性,这个放大/驱动工作由S-AMP负责,一个存储体对应一个S- AMP通道。但它要有一个准备时间才能保证信号的发送强度(事前还要进行电压比较以进行逻辑电平的判断),因此从数据I/O总线上有数据输出之前的一个时钟上升沿开始,数据即已传向S-AMP,也就是说此时数据已经被触发,经过一定的驱动时间最终传向数据I/O总线进行输出,这段时间我们称之为 tAC(Access Time from CLK,时钟触发后的访问时间)。
目前内存的读写基本都是连续的,因为与CPU交换的数据量以一个Cache Line(即CPU内Cache的存储单位)的容量为准,一般为64字节。而现有的Rank位宽为8字节(64bit),那么就要一次连续传输8次,这就涉及到我们也经常能遇到的突发传输的概念。突发(Burst)是指在同一行中相邻的存储单元连续进行数据传输的方式,连续传输的周期数就是突发长度(Burst Lengths,简称BL)。
在进行突发传输时,只要指定起始列地址与突发长度,内存就会依次地自动对后面相应数量的存储单元进行读/写操作而不再需要控制器连续地提供列地址。这样,除了第一笔数据的传输需要若干个周期(主要是之前的延迟,一般的是tRCD+CL)外,其后每个数据只需一个周期的即可获得。
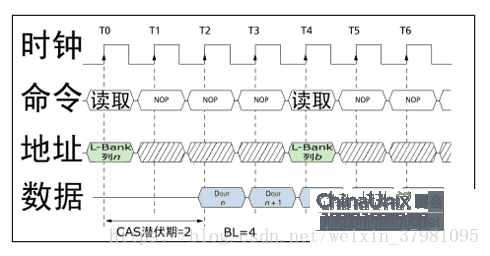
突发连续读取模式:只要指定起始列地址与突发长度,后续的寻址与数据的读取自动进行,而只要控制好两段突发读取命令的间隔周期(与BL相同)即可做到连续的突发传输。
谈到了突发长度时。如果BL=4,那么也就是说一次就传送4×64bit的数据。但是,如果其中的第二笔数据是不需要的,怎么办?还都传输吗?
为了屏蔽不需要的数据,人们采用了数据掩码(Data I/O Mask,简称DQM)技术。通过DQM,内存可以控制I/O端口取消哪些输出或输入的数据。
这里需要强调的是,在读取时,被屏蔽的数据仍然会从存储体传出,只是在“掩码逻辑单元”处被屏蔽。
DQM由北桥控制,为了精确屏蔽一个P-Bank位宽中的每个字节,每个DIMM有8个DQM 信号线,每个信号针对一个字节。这样,对于4bit位宽芯片,两个芯片共用一个DQM信号线,对于8bit位宽芯片,一个芯片占用一个DQM信号,而对于 16bit位宽芯片,则需要两个DQM引脚。
在数据读取完之后,为了腾出读出放大器以供同一Bank内其他行的寻址并传输数据,内存芯片将进行预充电的操作来关闭当前工作行。还是以上面那个Bank示意图为例。当前寻址的存储单元是B1、R2、C6。如果接下来的寻址命令是B1、R2、C4,则不用预充电,因为读出放大器正在为这一行服务。但如果地址命令是B1、R4、C4,由于是同一Bank的不同行,那么就必须要先把R2关闭,才能对R4寻址。从开始关闭现有的工作行,到可以打开新的工作行之间的间隔就是tRP(Row Precharge command Period,行预充电有效周期),单位也是时钟周期数。
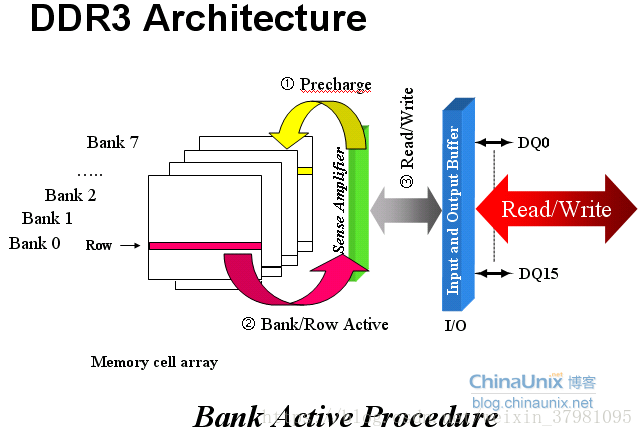
在不同Bank间读写也是这样,先把原来数据写回,再激活新的Bank/Row。
DQS 是DDR中的重要功能,它的功能主要用来在一个时钟周期内准确的区分出每个传输周期,并便于接收方准确接收数据。每一颗芯片都有一个DQS信号线,它是双向的,在写入时它用来传送由北桥发来的DQS信号,读取时,则由芯片生成DQS向北桥发送。完全可以说,它就是数据的同步信号。
在读取时,DQS与数据信号同时生成(也是在CK与CK#的交叉点)。而DDR内存中的CL也就是从CAS发出到DQS生成的间隔,DQS生成时,芯片内部的预取已经完毕了,由于预取的原因,实际的数据传出可能会提前于DQS发生(数据提前于DQS传出)。由于是并行传输,DDR内存对tAC也有一定的要求,对于DDR266,tAC的允许范围是±0.75ns,对于DDR333,则是±0.7ns,有关它们的时序图示见前文,其中CL里包含了一段DQS 的导入期。
DQS 在读取时与数据同步传输,那么接收时也是以DQS的上下沿为准吗?不,如果以DQS的上下沿区分数据周期的危险很大。由于芯片有预取的操作,所以输出时的同步很难控制,只能限制在一定的时间范围内,数据在各I/O端口的出现时间可能有快有慢,会与DQS有一定的间隔,这也就是为什么要有一个tAC规定的原因。而在接收方,一切必须保证同步接收,不能有tAC之类的偏差。这样在写入时,芯片不再自己生成DQS,而以发送方传来的DQS为基准,并相应延后一定的时间,在DQS的中部为数据周期的选取分割点(在读取时分割点就是上下沿),从这里分隔开两个传输周期。这样做的好处是,由于各数据信号都会有一个逻辑电平保持周期,即使发送时不同步,在DQS上下沿时都处于保持周期中,此时数据接收触发的准确性无疑是最高的。
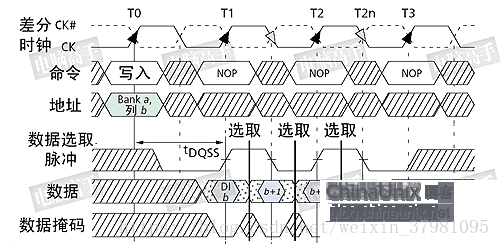
在写入时,以DQS的高/低电平期中部为数据周期分割点,而不是上/下沿,但数据的接收触发仍为DQS的上/下沿

