

Mysql库表无索引查询优化
情况
单表三千万数据量,只有id这一个索引无其他索引,这时候使用无索引的kh字段查询数据
分页查询优化
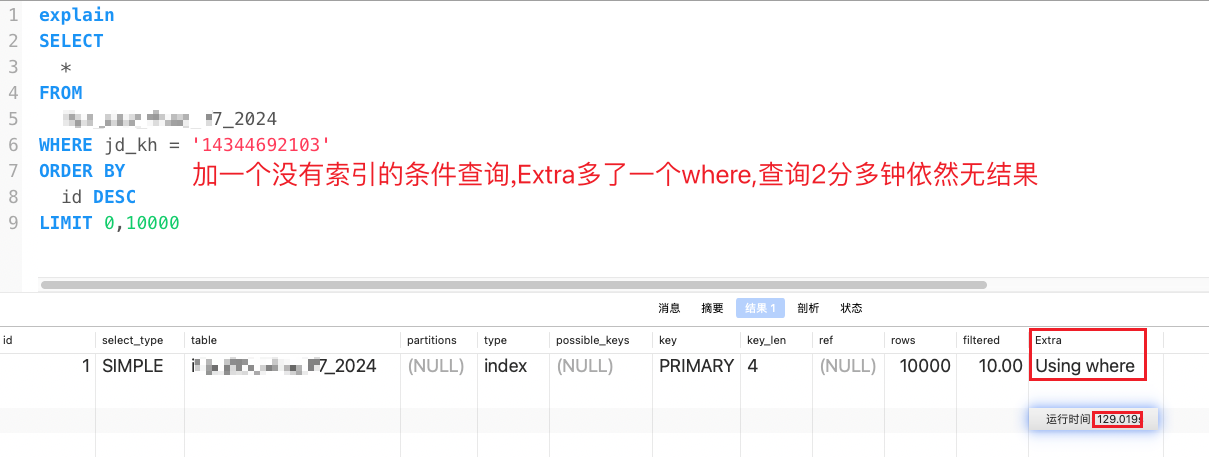
explain
SELECT
*
FROM
dev_log_27_2024
WHERE jd_kh = '14344692103'
ORDER BY
id DESC
LIMIT 0,10000
带where
不带where

sql执行流程
- 全表扫描(Full Table Scan)
由于 jd_kh 列没有索引,MySQL 无法通过索引快速查找符合 jd_kh = '14344692103' 条件的记录,因此必须进行全表扫描。
• 逐行扫描:MySQL 会从表的第一个数据页开始,逐行扫描整个表中的每一条记录。
• 过滤条件:在扫描的过程中,MySQL 会检查 jd_kh 列是否等于 '14344692103'。符合条件的记录将被保存在内存中的一个结果集中。 - 使用主键索引排序(ORDER BY id DESC)
• 主键索引的作用:id 列是主键,并且主键索引在 MySQL 的 InnoDB 存储引擎中是一个聚集索引(Clustered Index),数据实际上按 id 顺序存储。
• 降序排序:由于查询中包含 ORDER BY id DESC,MySQL 需要对符合条件的记录按照 id 进行降序排序。
• 由于 id 是主键,MySQL 可以直接使用扫描过程中已经按主键顺序获取的记录来进行排序,效率相对较高。
• 但是,排序仍然会涉及到对符合 jd_kh 条件的所有记录进行比较。 - 应用 LIMIT 条件
• 截取前 10,000 条记录:MySQL 会根据 LIMIT 0, 10000 截取排序后的前 10,000 条记录,并将这些记录返回给客户端。
• 停止扫描:一旦获取了 10,000 条记录,MySQL 将停止继续扫描和处理后续的行。 - 返回结果
• MySQL 将最终筛选、排序、截取的结果集返回给客户端。
总结
由于 jd_kh 列没有索引,MySQL 必须执行全表扫描来查找符合 jd_kh = '14344692103' 条件的记录。这些记录会在扫描过程中按 id 主键进行排序,然后 MySQL 会根据 LIMIT 返回前 10,000 条记录。
这种执行方式对于大表(如包含数百万或数千万条记录的表)来说效率较低,特别是在 jd_kh 条件筛选出大量记录的情况下。为了提高查询效率,建议在 jd_kh 列上添加索引,或者优化查询策略。
limit 10比limit 1000快很多的原因
limit 10很快,但是limit 1000超级慢就是因为全表扫描找到1000条该记录的数据需要扫描的记录非常大,所以很慢,而10条数据很快就可以找到,但是页码越往后查询越慢就是因为要扫描的记录书变多.
如果这篇文章对你有用,可以关注本人微信公众号获取更多ヽ(^ω^)ノ ~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号