

Using join buffer (Block Nested Loop)调优
Mysql5.7 Explain
Using join buffer (Block Nested Loop)
调优前
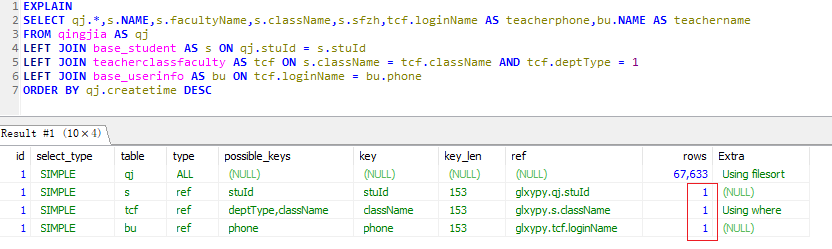
EXPLAIN SELECT qj.*,s.NAME,s.facultyName,s.className,s.sfzh,tcf.loginName AS teacherphone,bu.NAME AS teachername
FROM qingjia AS qj
LEFT JOIN base_student AS s ON qj.stuId = s.stuId
LEFT JOIN teacherclassfaculty AS tcf ON s.className = tcf.className AND tcf.deptType = 1
LEFT JOIN base_userinfo AS bu ON tcf.loginName = bu.phone
ORDER BY qj.createtime DESC
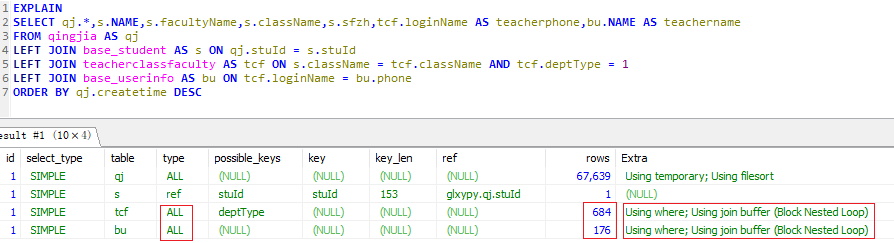
Using join buffer (Block Nested Loop)是因为右表没有在join列上建索引导致嵌套循环。
添加被驱动表索引调优
添加被驱动表(右侧表)索引,当添加组合索引时,要遵从最左匹配原则
ALTER TABLE `base_userinfo` ADD INDEX `phone` (`phone`);
alter table teacherclassfaculty add index className(className);
调优后
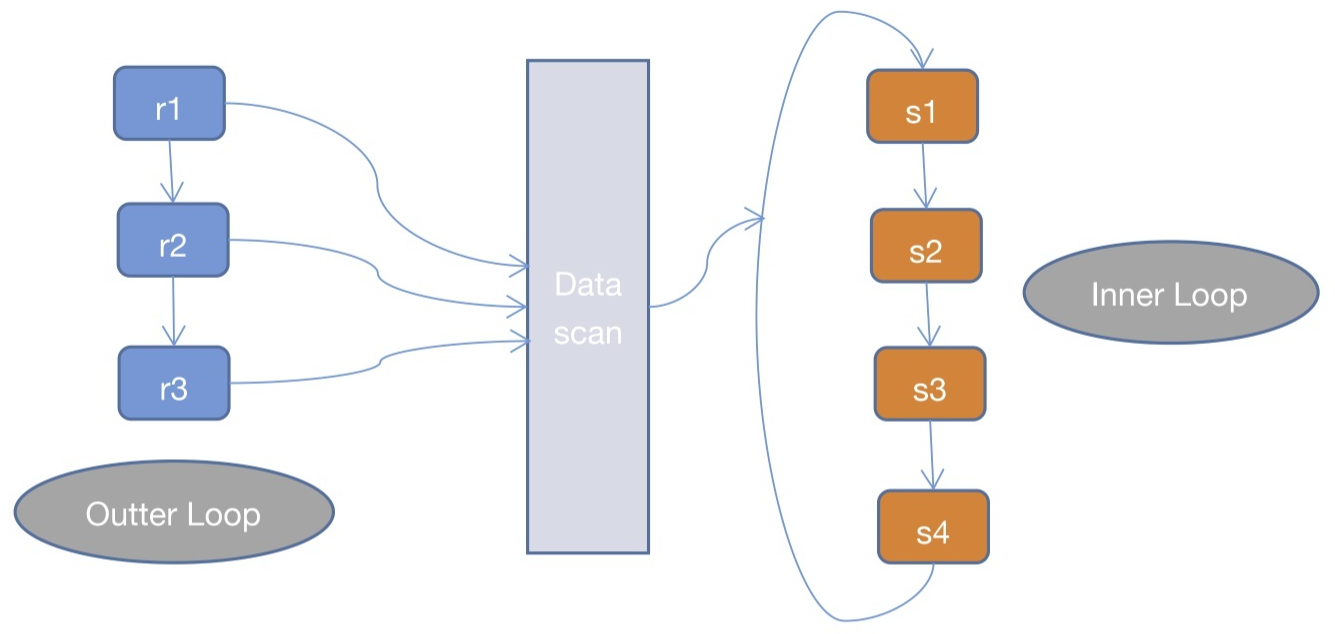
Nested Loop Join原理
1.第一步筛选出驱动表符合条件的记录
驱动表为explain第一条记录,即qj表,如果where条件为驱动表字段,那么从qj表中拿到第一条记录的时候发现是符合where判断的,可以留下,然后该去被驱动表s表中进行匹配。
-- 驱动表
select * from 驱动表 where sql中where字段 = ''
2.通过连接条件on后的条件对被驱动表的数据筛选
驱动表qj第一条记录stuId和被驱动表s相等stuId,且满足on的其他条件,则该条记录留下。
-- 被驱动表
select * from 被驱动表 where 被驱动表on关联字段 = '逐行驱动表记录字段数值' and 其他on条件;
-- 被驱动表s
select * from base_student where stuId = 'qj_id';
-- 被驱动表tcf
select * from teacherclassfaculty where className = 's_classname' and depttype = 1;
如果被驱动表s的on字段没有添加索引,则会查询被驱动表中的所有记录。
3.将查询的结果与驱动表进行连接并返回给客户端
连接就要根据左连接还是右连接进行匹配了,没有的加null值,等等。
Nested Loop Join三种算法
NLJ是通过两层循环,用第一张表做Outter Loop,第二张表做Inner Loop,Outter Loop的每一条记录跟Inner Loop的记录作比较,符合条件的就输出。而NLJ又有3种细分的算法
1、Simple Nested Loop Join(SNLJ)
for each row in t1 matching range {
for each row in t2 matching reference key {
for each row in t3 {
if row satisfies join conditions, send to client
}
}
}
SNLJ就是两层循环全量扫描连接的两张表,得到符合条件的两条记录则输出,这也就是让两张表做笛卡尔积,比较次数是R * S,是比较暴力的算法,会比较耗时,所以mysql查询优化器。
Index Nested Loop Join(INLJ)
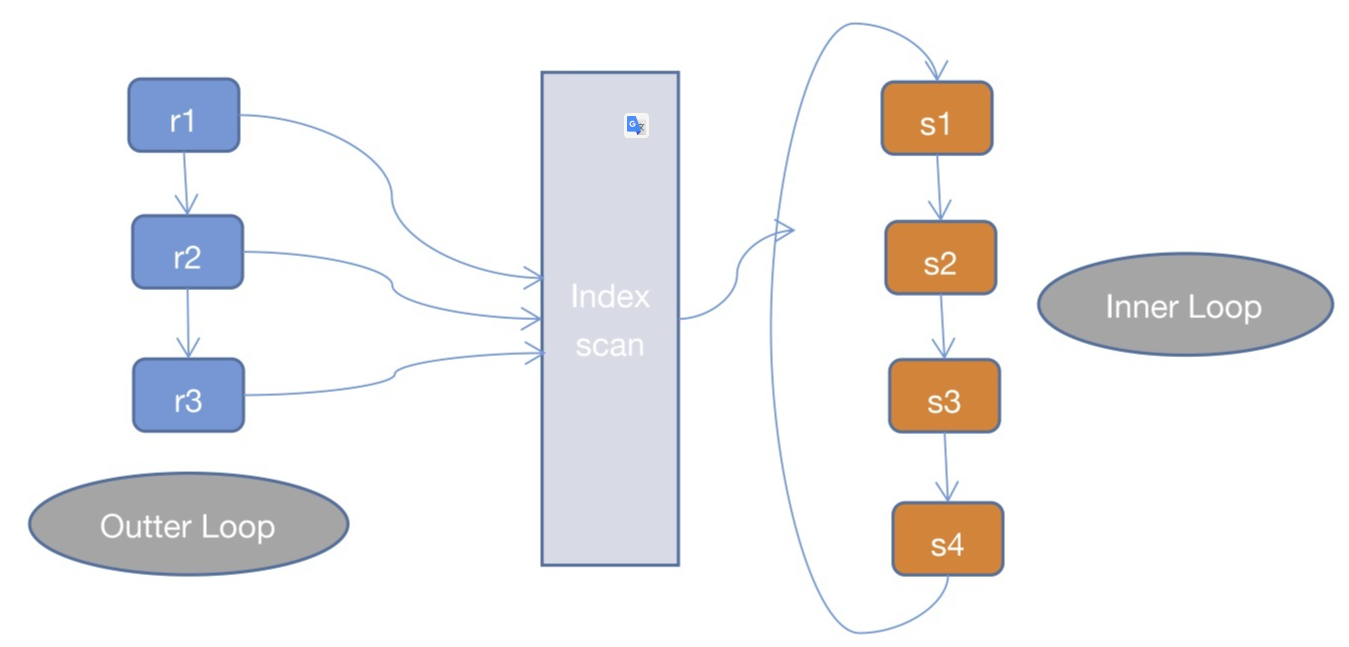
INLJ是在SNLJ的基础上做了优化,通过连接条件确定可用的索引,在Inner Loop中扫描索引而不去扫描数据本身,从而提高Inner Loop的效率。
而INLJ也有缺点,就是如果扫描的索引是非聚簇索引,并且需要访问非索引的数据,会产生一个回表读取数据的操作,这就多了一次随机的I/O操作。
2、Block Nested Loop Join(BNLJ)
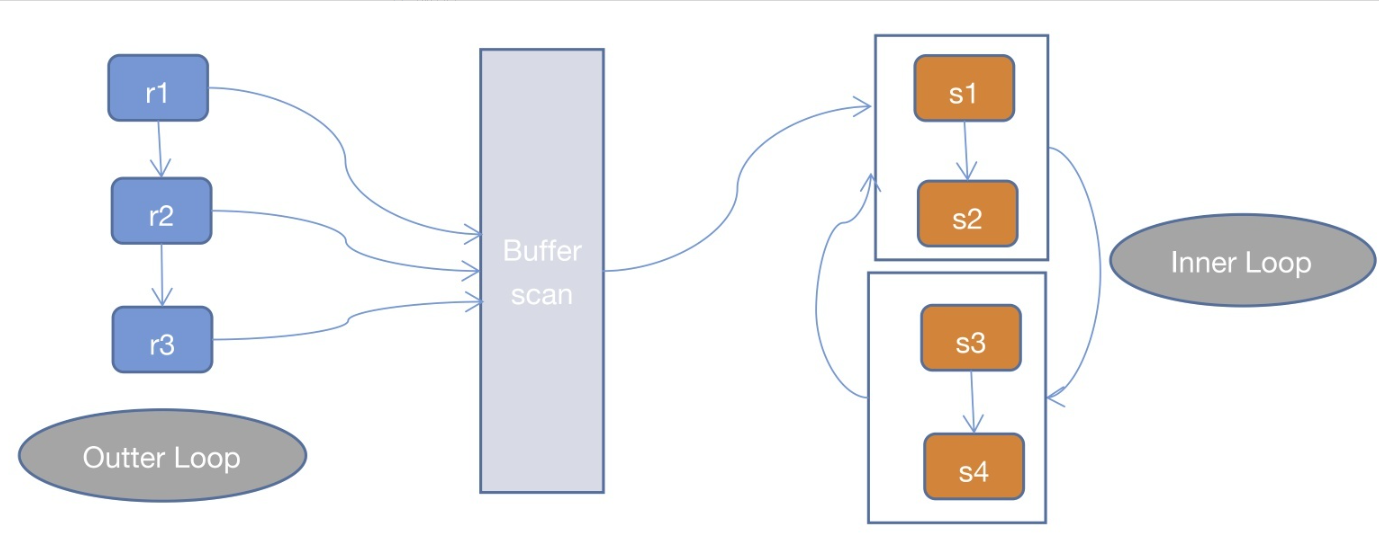
一般情况下,MySQL优化器在索引可用的情况下,会优先选择使用INLJ算法,但是在无索引可用,或者判断full scan可能比使用索引更快的情况下,还是不会选择使用过于粗暴的SNLJ算法。
这里就出现了BNLJ算法了,BNLJ在SNLJ的基础上使用了join buffer,会提前读取之前的表关联记录到buffer中,以提高Inner Loop的效率。
for each row in t1 matching range {
for each row in t2 matching reference key {
store used columns from t1, t2 in join buffer -- 将之前的关联表存入buffer
if buffer is full {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
empty join buffer
}
}
}
-- 当有之前表join的buffer数据,则直接用t3作为outer去loop
if buffer is not empty {
for each row in t3 {
for each t1, t2 combination in join buffer {
if row satisfies join conditions, send to client
}
}
}


 浙公网安备 33010602011771号
浙公网安备 33010602011771号