

1.系统架构设计师-计算机组成与操作系统
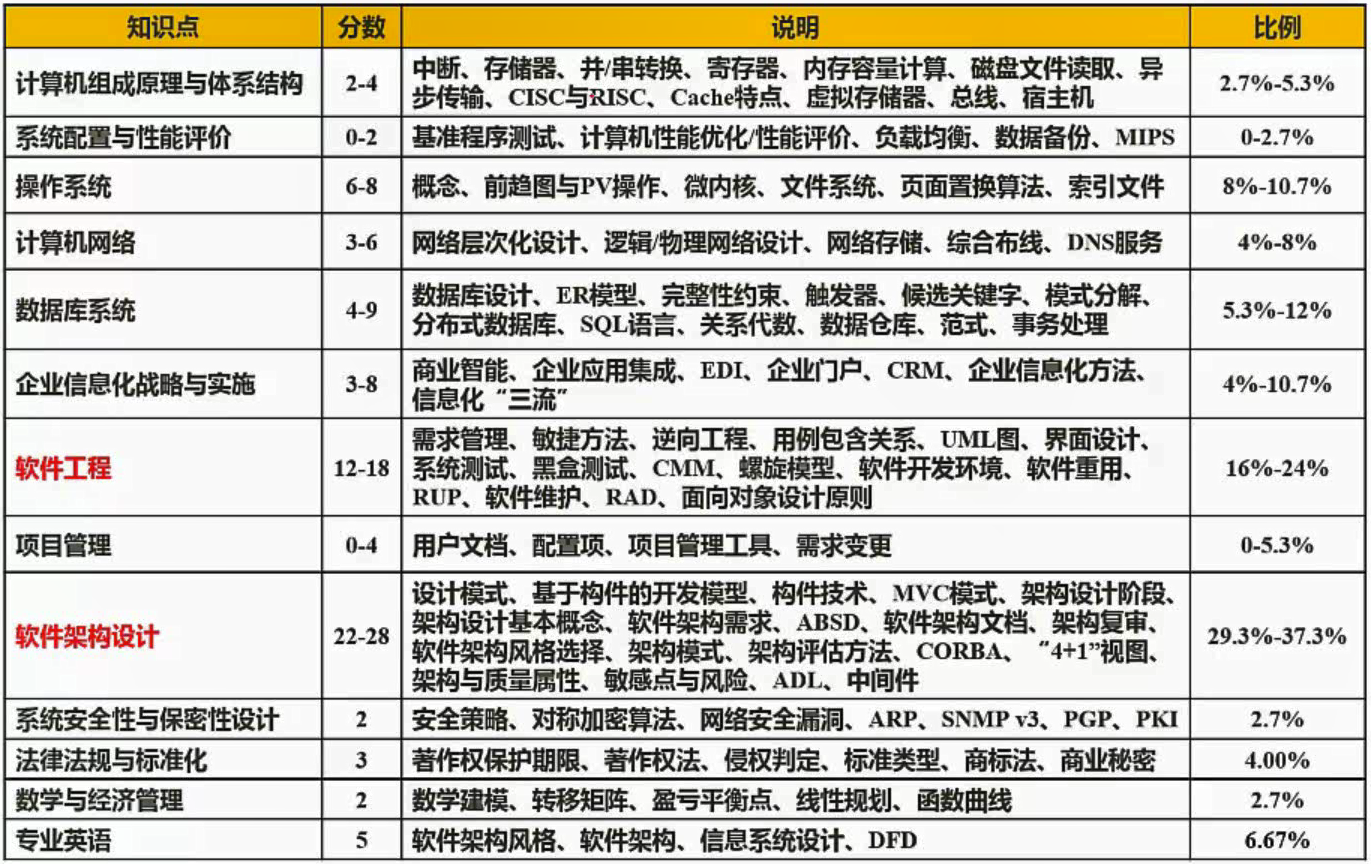
一、分值分布
计算机组成与体系结构

Flynn体系结构分类
计算机系统结构的分类方法之一,1966年M.J.Flynn提出了如下定义:
指令流(Instruction Stream):机器执行的指令序列。
数据流(Data Stream):指令调用的数据序列,包括输入数据和中间结果。
多倍性(Multiplicity):在系统最受限制的元件上同时处于同一执行阶段指令或数据执行的最大可能个数。
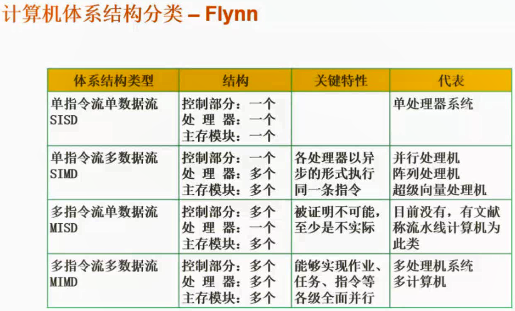
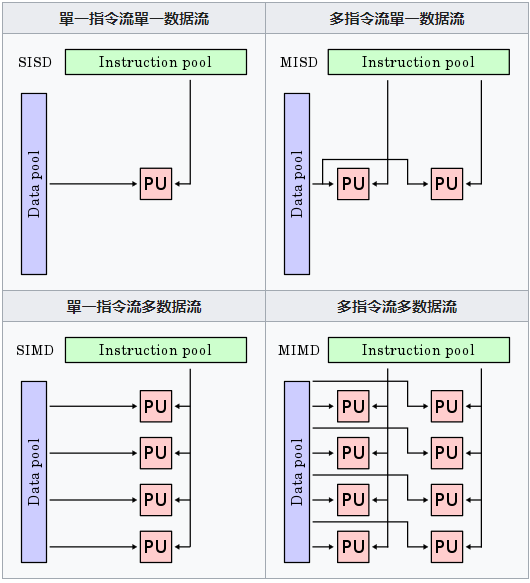
SISD:早期的计算机都是SISD机器,如冯诺.依曼架构,如IBM PC机,早期的巨型机和许多8位的家用机等。
SIMD:我们用的单核计算机基本上都属于SIMD机器。
MISD:只是作为理论模型出现,没有投入到实际应用之中。
MIMD:机器可以同时执行多个指令流,这些指令流分别对不同数据流进行操作。最新的多核计算平台就属于MIMD的范畴,例如Intel和AMD的双核处理器等都属于MIMD。

主要考点
阵列处理器(array processor)又称为并行处理机、SIMD计算机。其核心是一个由多个处理单元构成的阵列,用单一的控制部件来控制多个处理单元对各自的数据进行相同的运算和操作。
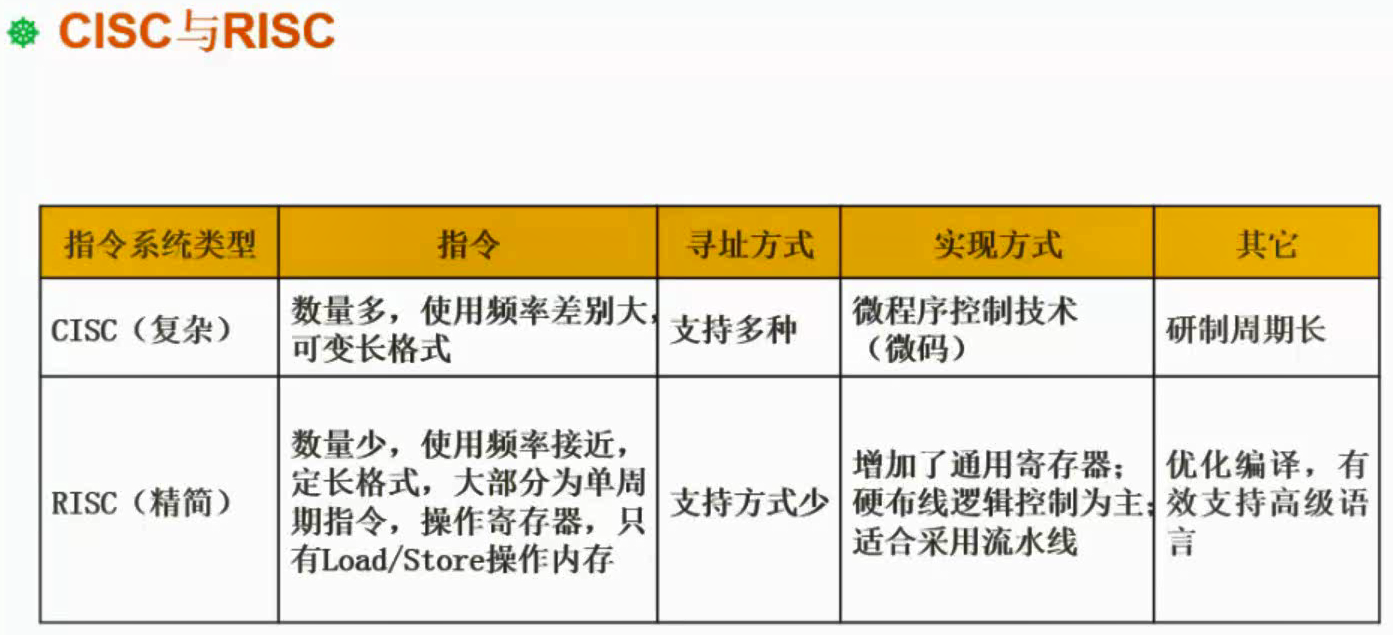
CISC与RISC
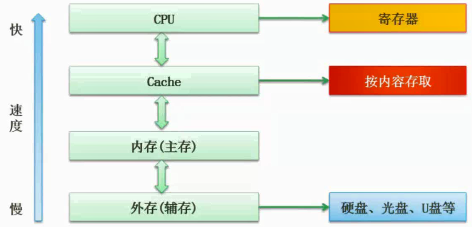
层次化存储结构
Cache命中率计算

局部性原理

时间局部性指的是,程序在运行时,最近刚刚被引用过的一个内存位置容易再次被引用,比如在调取一个函数的时候,前不久才调取过的本地参数容易再度被调取使用。
空间局部性指的是,最近引用过的内存位置以及其周边的内存位置容易再次被使用。空间局部性比较常见于循环中,比如在一个数列中,如果第3个元素在上一个循环中使用,则本次循环中极有可能会使用第4个元素。
主存分类
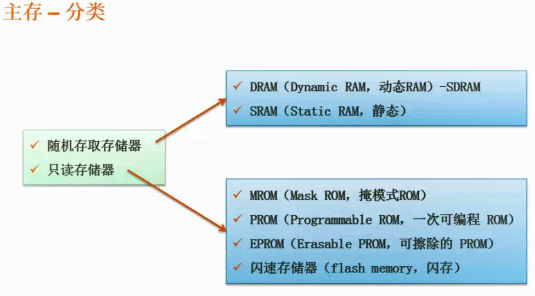
ROM,只读存储器,(顾名思义,只是读取调用,不能更改) 一旦储存资料就无法再将之改变或删除,也就是断电之后不会丢失。
RAM,随机存储器,存储单元的内容可按需随意取出或存入, 断电后数据就丢失。
主存的编址
编址的意思是把内存内存分成一个个块,按字节编址的意思就是按每块1B=8bit去分块。
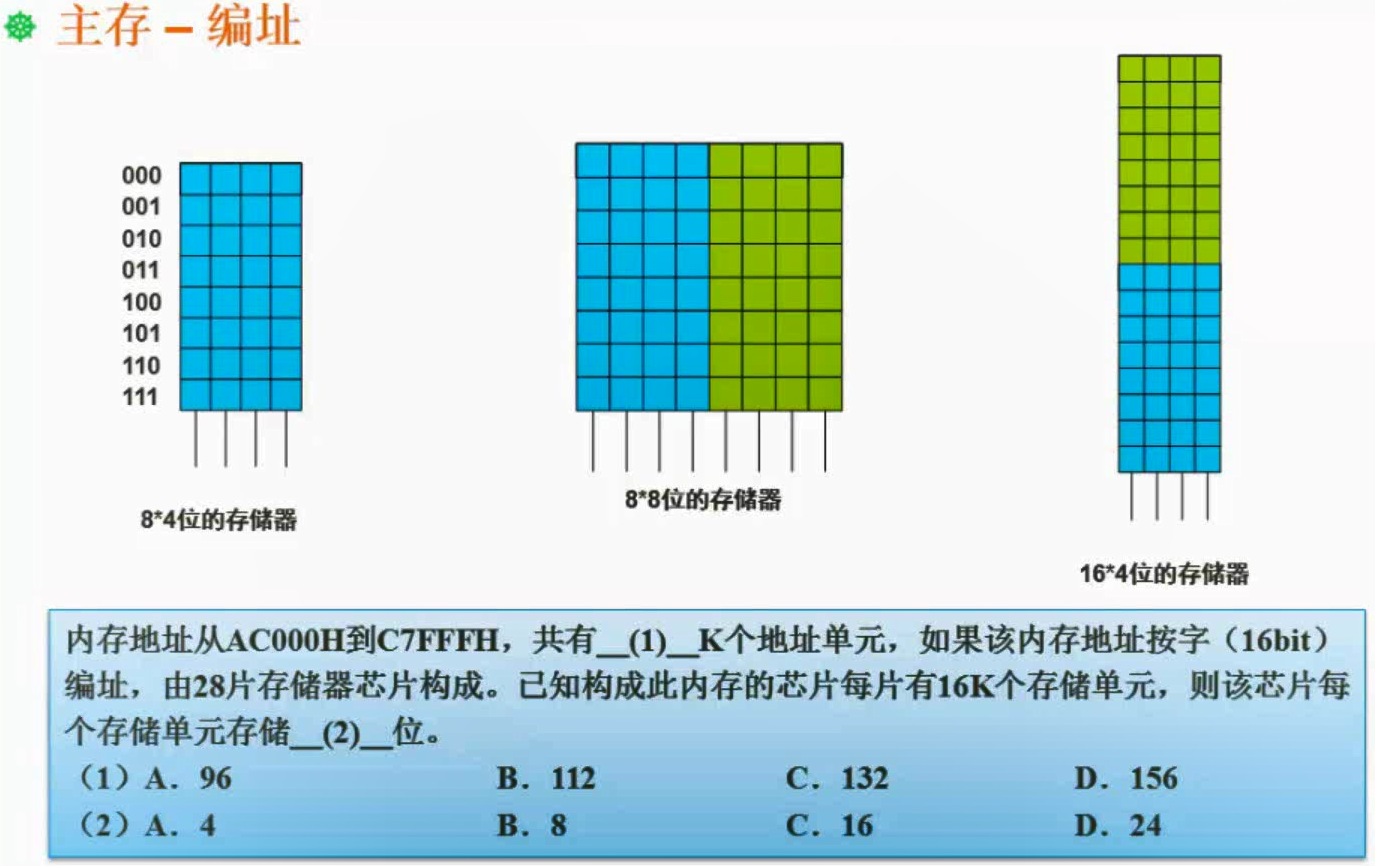
1.先计算有多少个内存地址,并转换成10进制
(C7FFFH + 1) - AC000H = 1C000H = 12 * 16^3 + 1 * 16^4 = 28 * 16^3 = 7 * 2^2 * (24)3 = 7 * 2^14
在计算多少K,用幂运算计算才可以,硬算算不出来。
1K = 1024 = 2^10
7 * 2^14 / 2^10 = 7 * 2^4 = 112个。
2.内存地址编址(16bit) * 地址单元个数 = 内存容量总量 = 28 * 16K * 存储单元位数
总结
地址单元个数 = 内存容量 / 内存编址方式(字节或字)
内存容量 = 内存编址(16bit) * 地址单元个数
例: 设有一个1MB容量的存储器,字长32位,问:按字节编址,字编址的寻址范围以及各自的寻址范围大小?
1.如果按字节编址,则
1MB = 2^20B
1字节=1B=8bit
2^20B/1B = 2^20
地址范围为0~(220)-1,也就是说需要二十根地址线才能完成对1MB空间的编码,所以地址寄存器为20位,寻址范围大小为220=1M
2.如果按字编址,则
1MB=2^20B
1字=32bit=4B
2^20B/4B = 2^18
地址范围为0~218-1,也就是说我们至少要用18根地址线才能完成对1MB空间的编码。因此按字编址的寻址范围是218
也可以统一换成bit做运算
总容量1M = 2^20B = 2^20 * 8 bit
按字节编址
2^20 * 8 bit /8 bit
按字编址
2^20 * 8 bit /32 bit
按双字编址
2^20 * 8 bit /32*2 bit
算出来是2^n次方,就需要n根地址线。
磁盘结构与参数
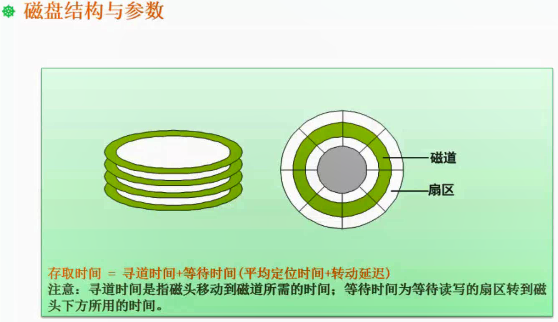
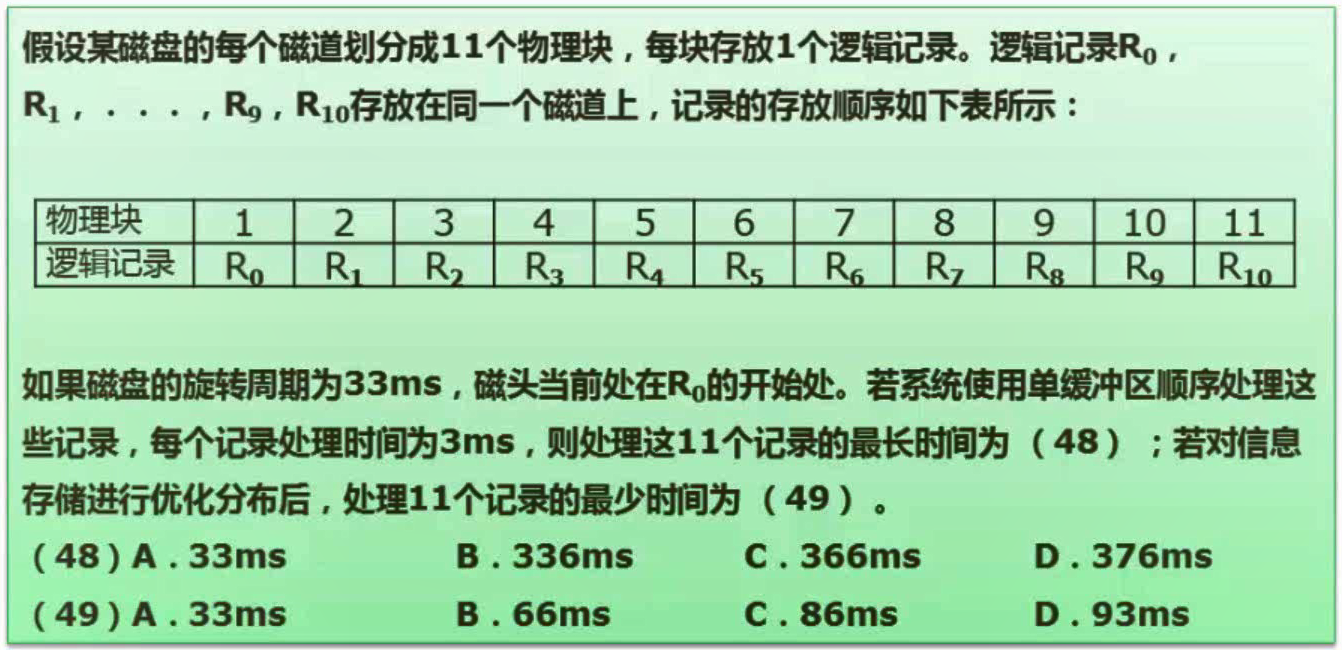
旋转周期为33ms -> 读取每个物理块的时间为3ms
1.前十个为33+3,最后一个为3+3。
(33+3)10 + (3+3) = 366
2.(3+3)11 = 66
系统配置与性能评价
性能指标
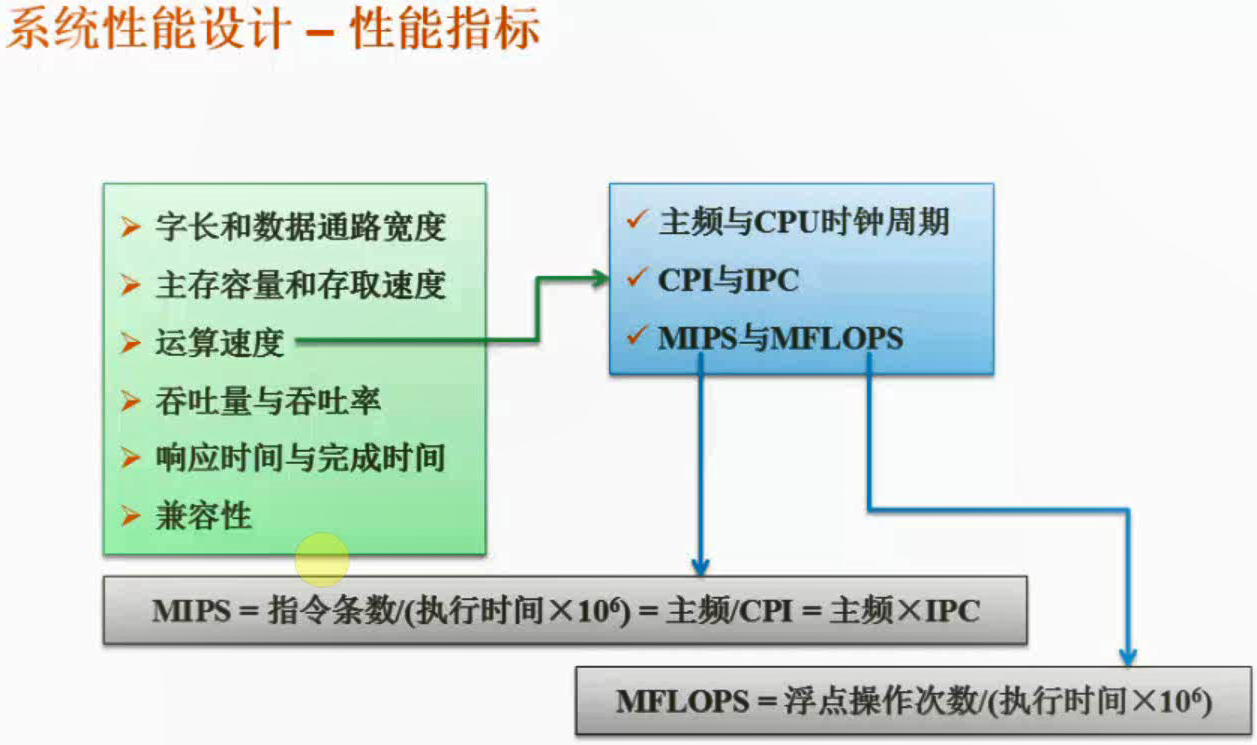
时钟频率f : 又称主频f,它是指CPU内部晶振的频率,常用单位为MHz,它反映了CPU的基本工作节拍,例如3.0GHz主频意思就是每秒晶振310001000*1000次。
时钟周期t : t=1/f; 主频的倒数,计算机中最小的时间单位,每次晶振所用的时间(3GHz主频的时钟周期就是1/3 000 000 000)。
机器周期 : m * t ; 也称为CPU周期,一条指令的执行过程划分为若干个阶段(如取指、译码、执行等),每一阶段所需要的时间称为机器周期,一个机器周期包含若干个(m个)时钟周期,也是时间单位。
指令周期 :m * t * n 执行一条指令所需要的时间(取指、译码、执行等所有机器周期的总和),一般包含若干个(n个)机器周期,也是时间单位。
CPI :(clock per instruction)= m * n; 平均每条指令的平均时钟周期个数。
指令周期 = CPI×时钟周期 = n×m×时钟周期 = n*m/主频f, 注意指令周期单位是s或者ns
IPC:(instruction per clock) 表示每(时钟)周期运行多少个指令.
MIPS = 每秒执行百万条指令数 = 1/(CPI×时钟周期×10的6次方)= 1/(指令周期×10的6次方) = 主频/(CPI×10的6次方) = 频率*IPC/10的6次方
MFLOPS 每秒百万浮点运算次数。代表了CPU处理浮点运算的能力。与MIPS不能相互转换
系统性能设计-阿姆达尔解决方案


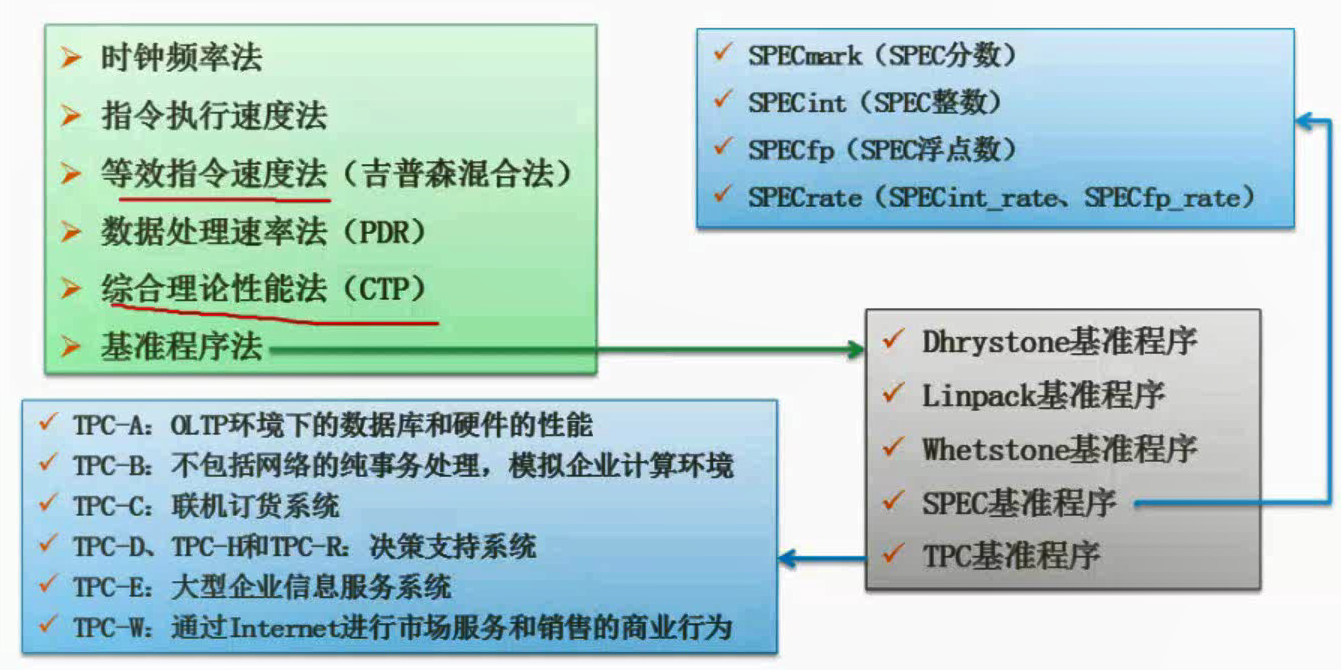
性能评价方法

前三种只考虑CPU的运算能力,其中第三中考虑指令比例不同的问题。
PDR除了运算能力,还考虑数据存储交互的问题,考虑CPU+存储。
CTP首先算出处理部件每个计算单元的有效计算率,再按不同字长加以调整,得出该计算单元的理论性能,所有组成该处理部件的计算单元的理论性能之和即为CTP。
基准程序法(即现在的跑分软件): 把应用程序中用得最多、最频繁的那部分核心程序作为评估计算机系统性能的标准程序,称为基准测试程序(benchmark)。基准程序法是目前一致承认的测试系统性能的较好方法。 考虑了诸如IVO结构、操作系统、编译程序的效率对系统性能的影响。
性能检测方法

操作系统基本原理
进程管理
进程的状态
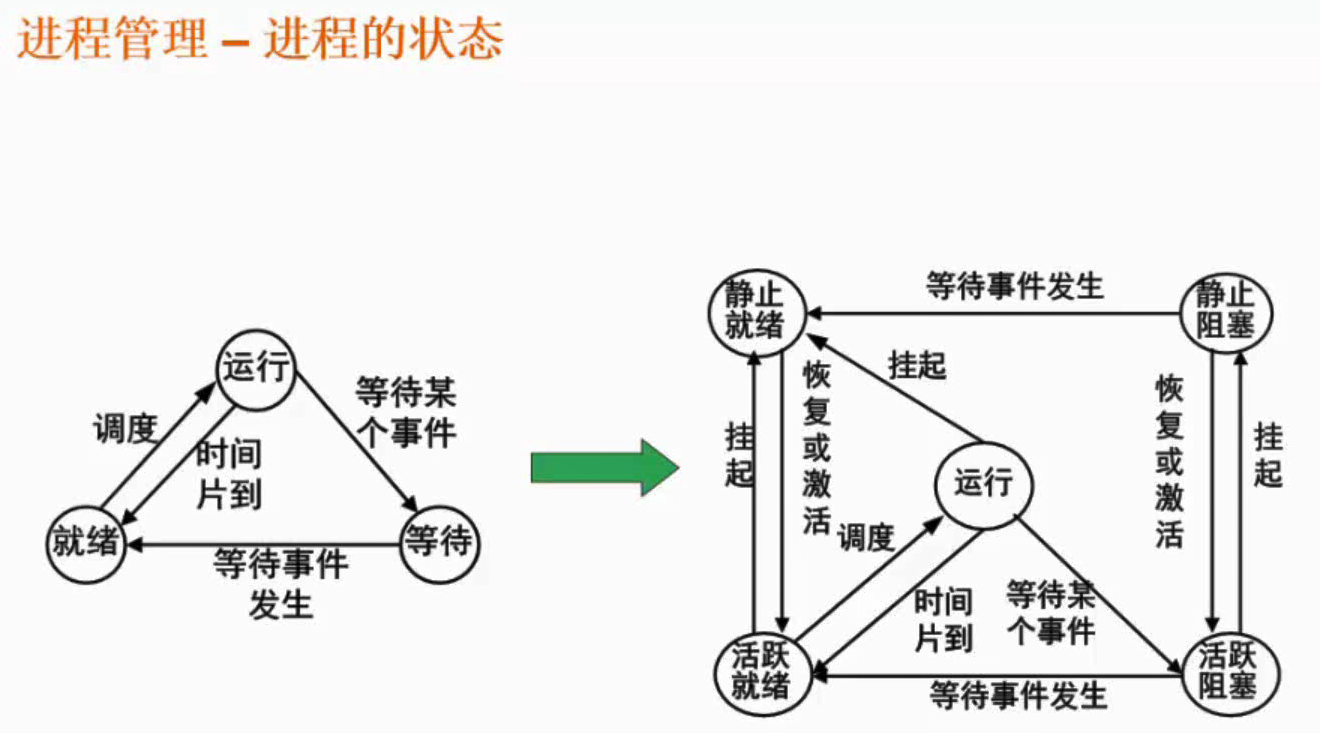
五态模型新增了人为干预的挂起操作(例如听歌时突然有语音,在接听语音时人为挂起歌曲进程),运行、活跃就绪、活跃阻塞对应三态模型中的运行、就绪、等待。
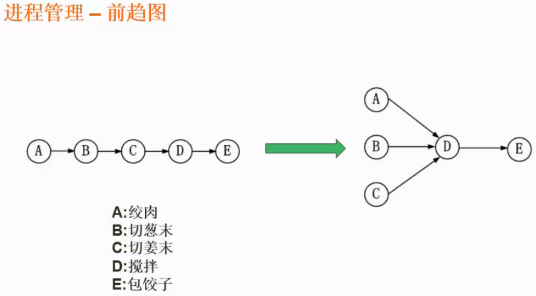
前趋图
precedence graph
进程的同步与互斥
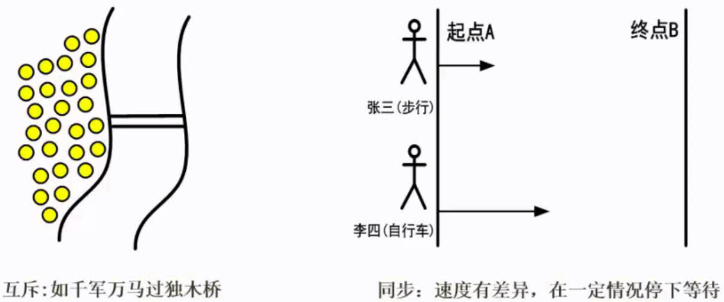
进程同步是一个操作系统级别的概念,是在多道程序的环境下,存在着不同的制约关系,为了协调这种互相制约的关系,实现资源共享和进程协作,从而避免进程之间的冲突,引入了进程同步。同步的反义是异步。
进程互斥是一个进程正在访问临界资源,另一个要访问该资源的进程必须等待。互斥的反义是共享。
消费者生产者问题
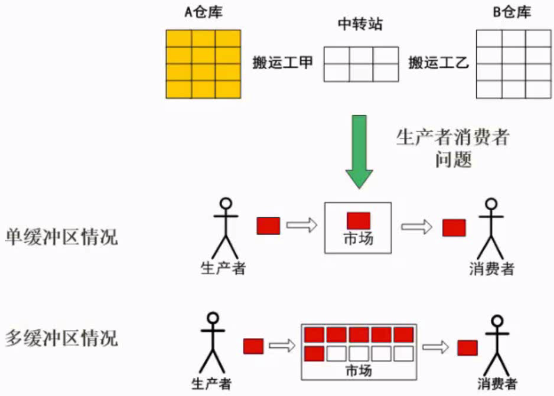
单缓冲区: 互斥:市场为互斥资源,只允许一个人去操作。同步:生产者放满了市场后需要等待消费者把市场里面的商品消费掉,生产者才能继续放入市场。
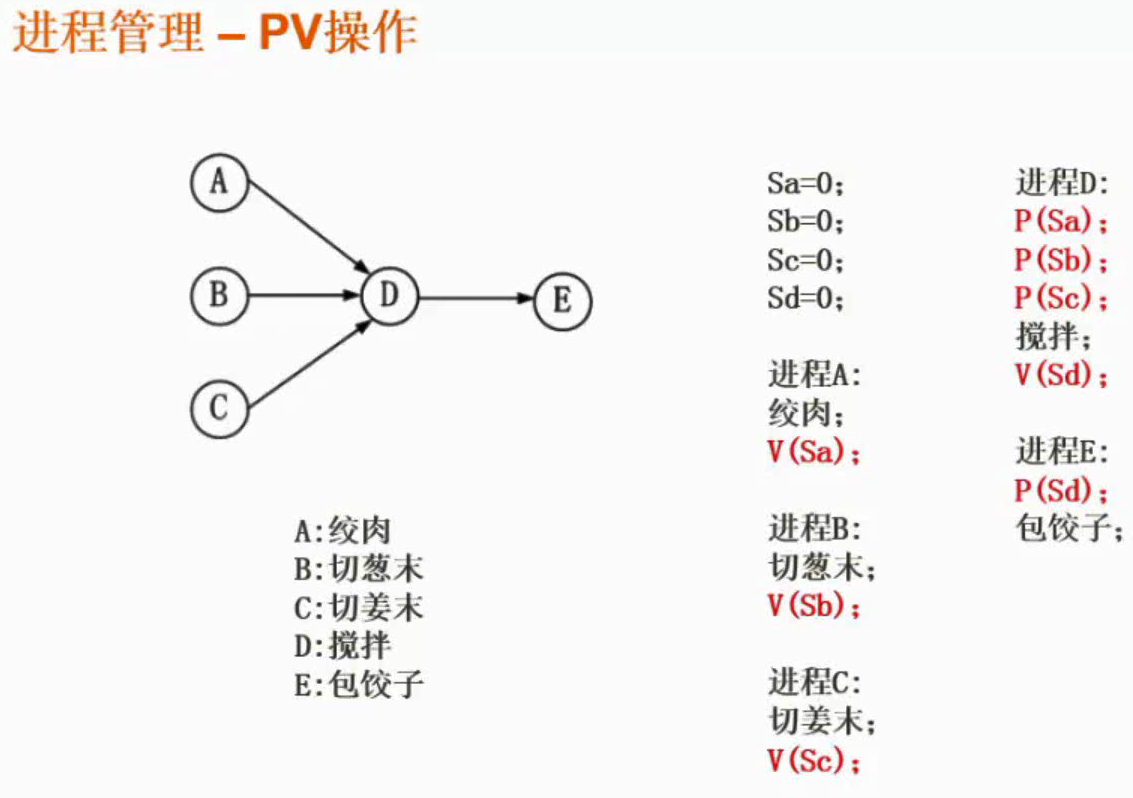
PV操作
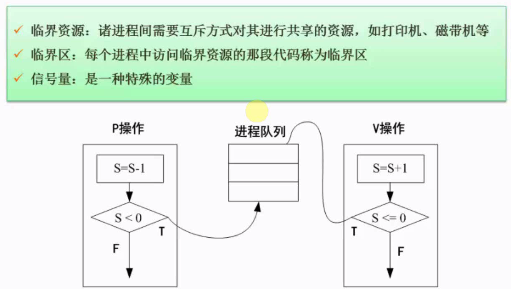
信号量的值表示相应资源的使用情况。信号量S>=0时,S表示可用资源的数量。执行一次P操作意味着请求分配一个资源,因此S的值减1;当S<0时,表示已经没有可用资源,S的绝对值表示当前等待该资源的进程数。
S大于0的确表示有临界资源可供使用,也就是说这个时候没有进程被阻塞在这个资源上,所以不需要唤醒。

S1:可生产数量信号量
S2:可消费数量信号量
PV操作与前趋图
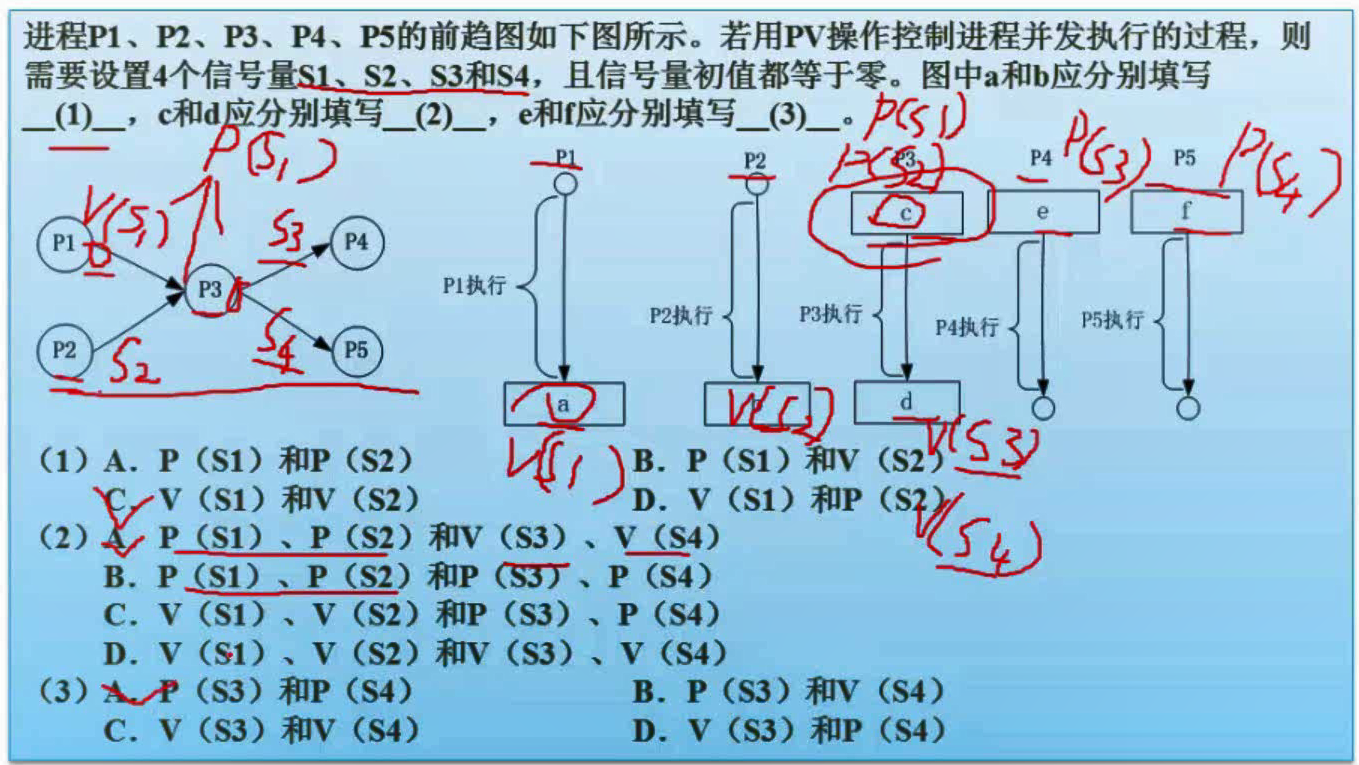
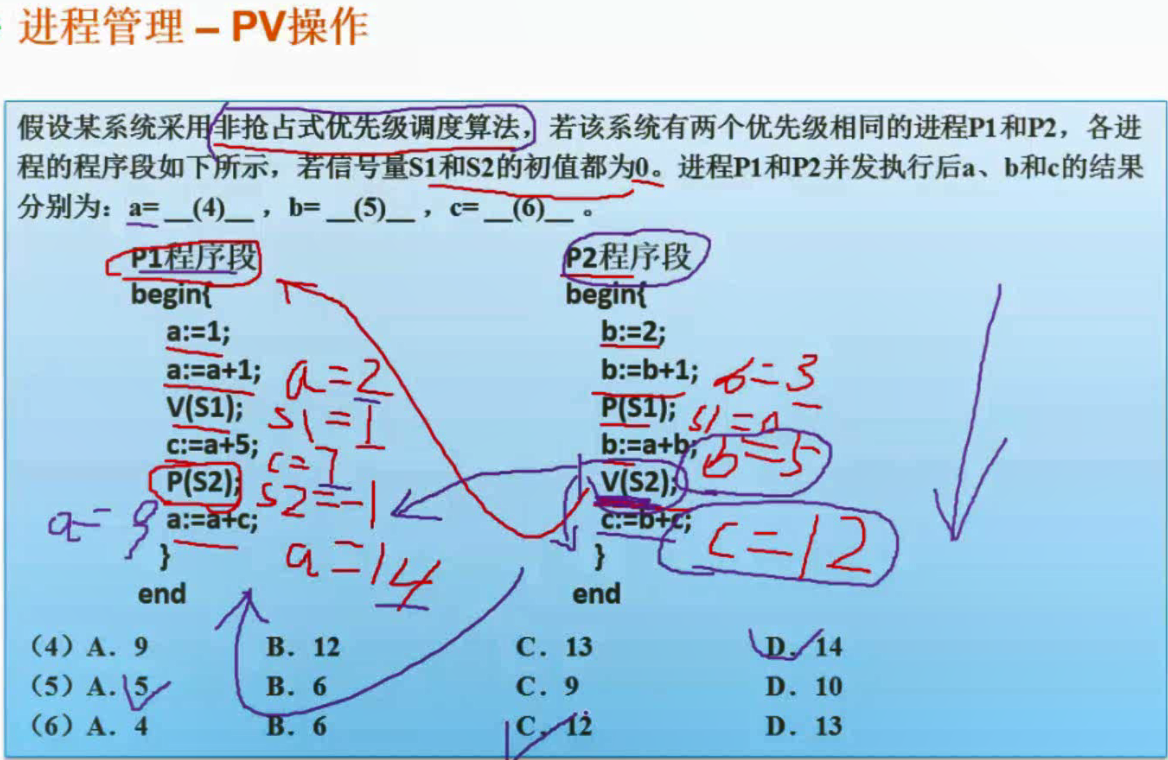
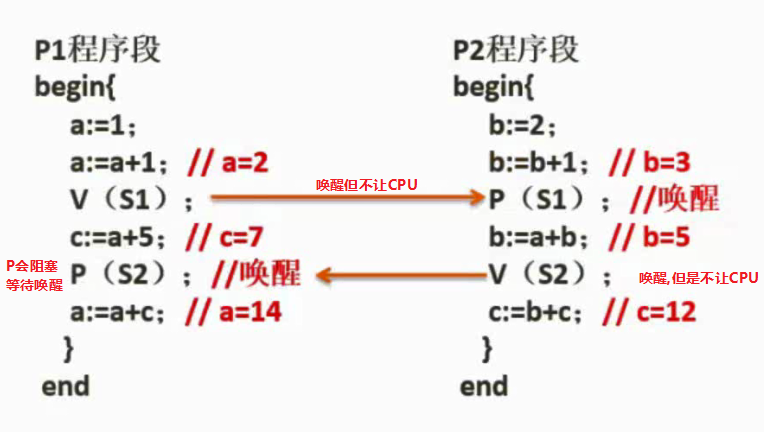
PV操作练习 - 非抢占式优先级调度算法
非抢占式: P操作<0时会阻塞,但是V操作唤醒后不会把CPU让给其他线程依然继续执行下去。
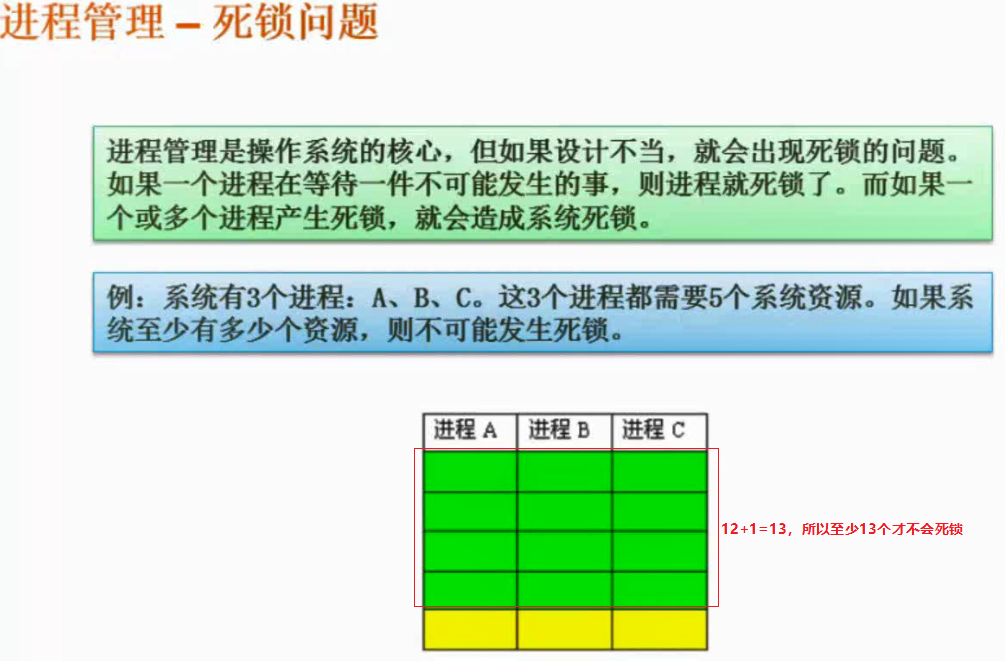
死锁问题
进程管理是操作系统的核心,但如果设计不当,就会出现死锁的问题。如果一个进程在等待一件不可能发生的事,则进程就死锁了。而如果一个或多个进程产生死锁,就会造成系统死锁。
死锁的预防与避免
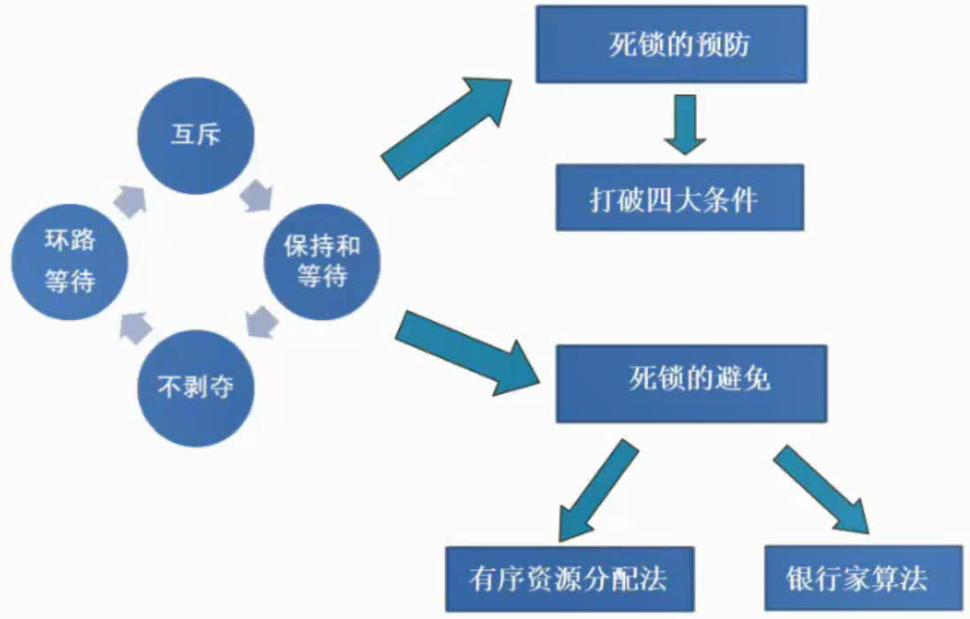
死锁条件:
互斥(互斥使用资源)、保持和等待(持有资源并等待剩下需要的资源)、不剥夺(不会剥夺已持有资源)、环路等待。
死锁的预防: 打破四大条件
死锁的避免:有序分配资源、银行家算法
银行家算法

存储管理
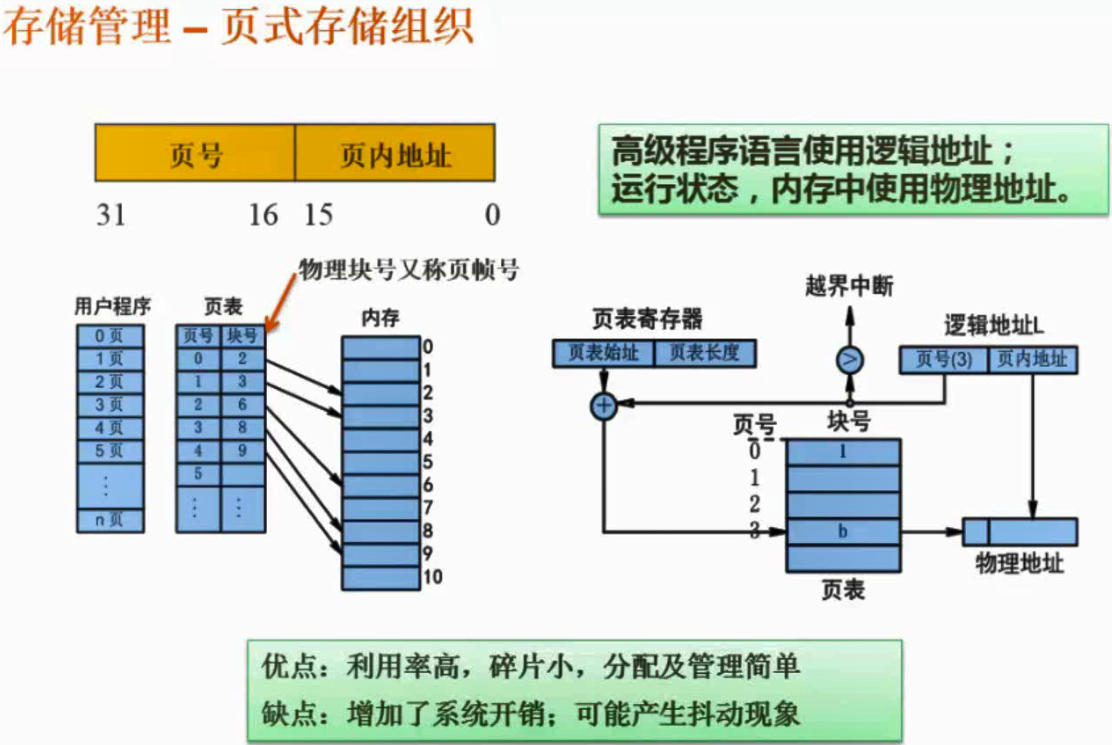
页式存储组织
将程序分成多个大小相同的页,只有最后一个页会浪费少量空间,每次把需要的页根据页表查询块号(页帧号)加载到对应的内存块中去。
逻辑地址=页号+页内地址
物理地址=块号+页内地址
页表:页号 - 内存块号(页帧号)对应关系
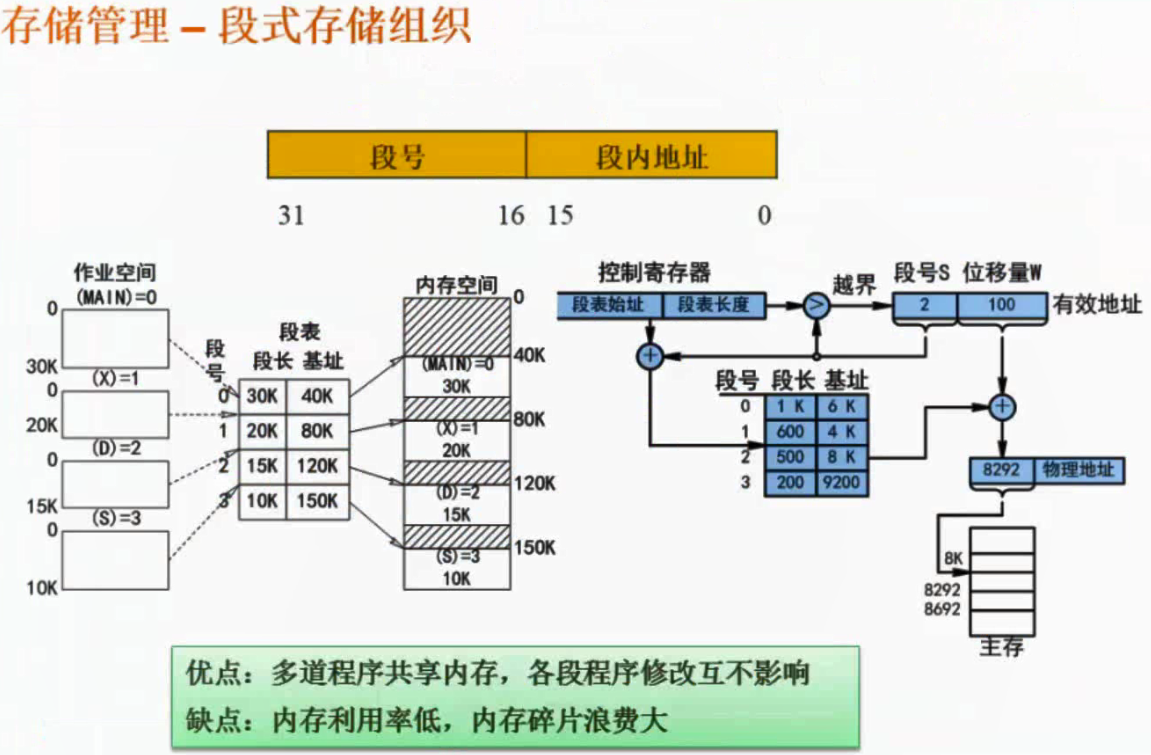
段式存储组织
将程序按逻辑结构(代码结构,按函数去分段,一个函数一个段)去分成多个大小不同的段,内存利用率低,但是便于共享。
段表: 段号 - 段长 - 基址
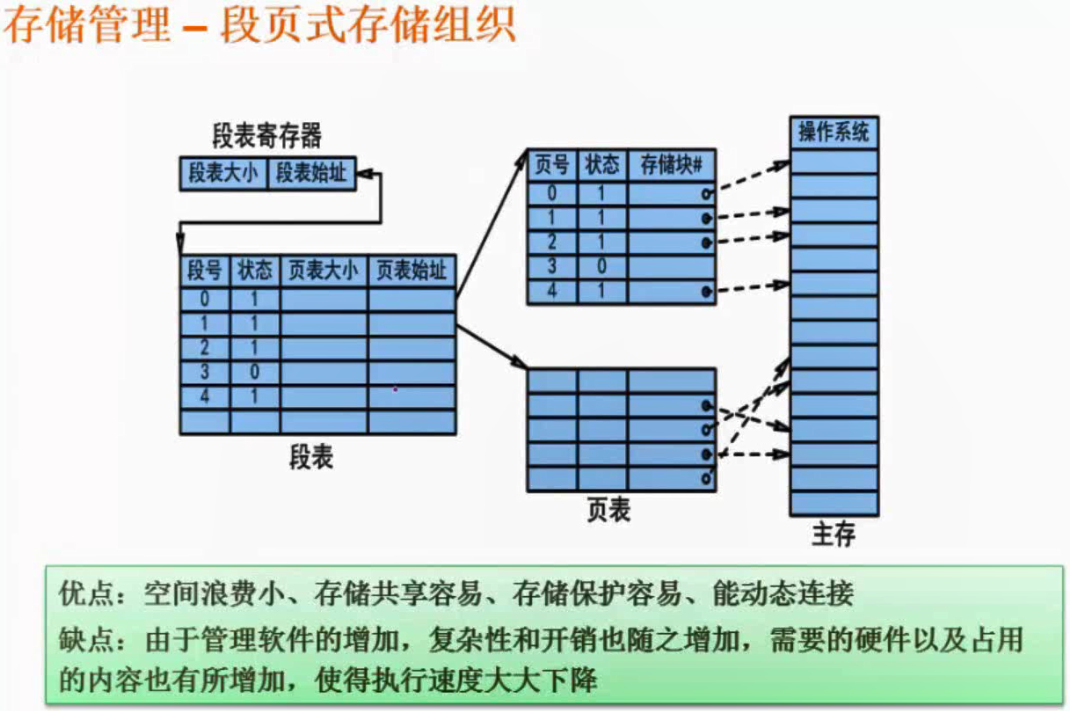
段页式存储组织
先分段再分页,浪费空间小,存储共享容易。
快表
块表是放在Cache中,慢表是放在内存中。

页面淘汰算法

最优算法是在知道程序访问页面顺序后,通过计算出什么时候淘汰什么页面,但是事实是不知道页面访问顺序,所以在实际应用中是没有这种算法的,但是可以在事后作为准线用来判断其他算法的优良。
抖动的意思是分配了更多的资源后反而效果下降的现象,比如FIFO在用3个页面比用4个页面缺页率低。
FIFO抖动现象
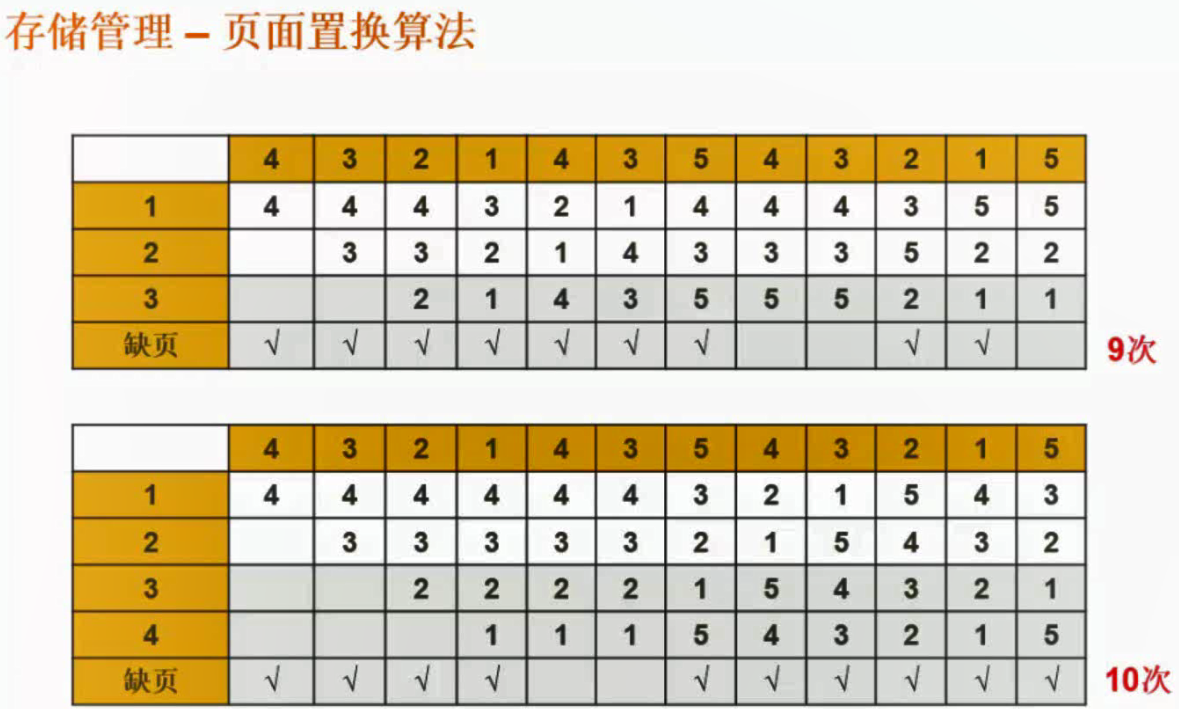
用四个内存块比用三个内存块缺页还多。
FIFO和LRU页面置换算法对比
文件管理
索引文件结构
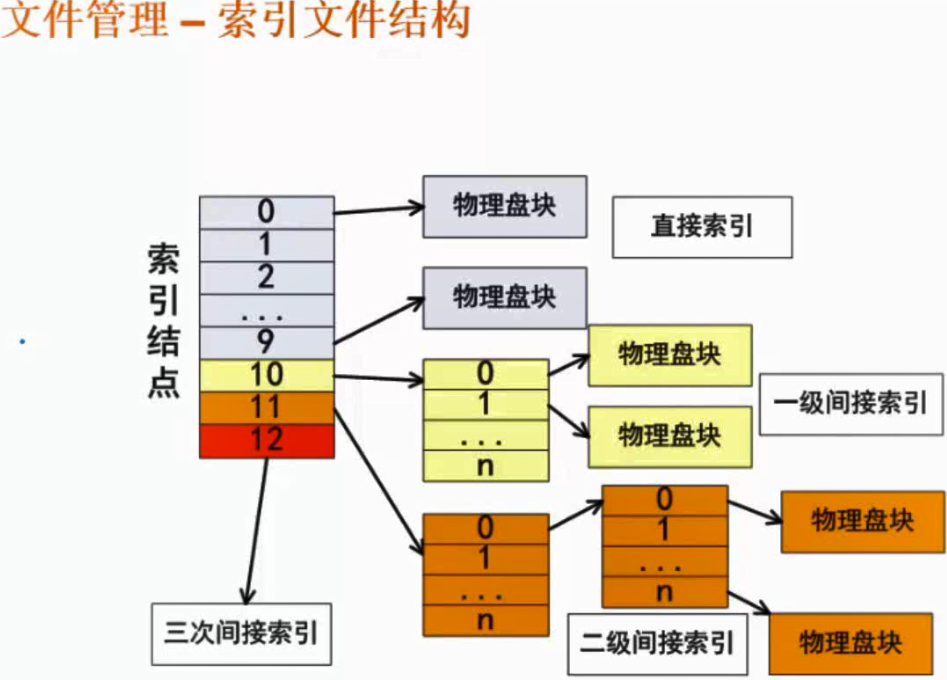
上图中有13个索引结点(考试时默认13个结点),假设盘块大小为4k,每个索引地址占4B,
直接索引:索引结点直接对应物理盘块。上图中有十个是直接索引,存储的大小为4k*10=40k。
一级间接索引:10号盘块有4k/4B=1024块(n的大小),所以一级索引的存储总和为4K * 1024。
二级间接索引:1024 * 1024 * 4K
三级间接索引:1024 * 1024 * 1024 * 4K
空闲存储空间管理 - 位示图法
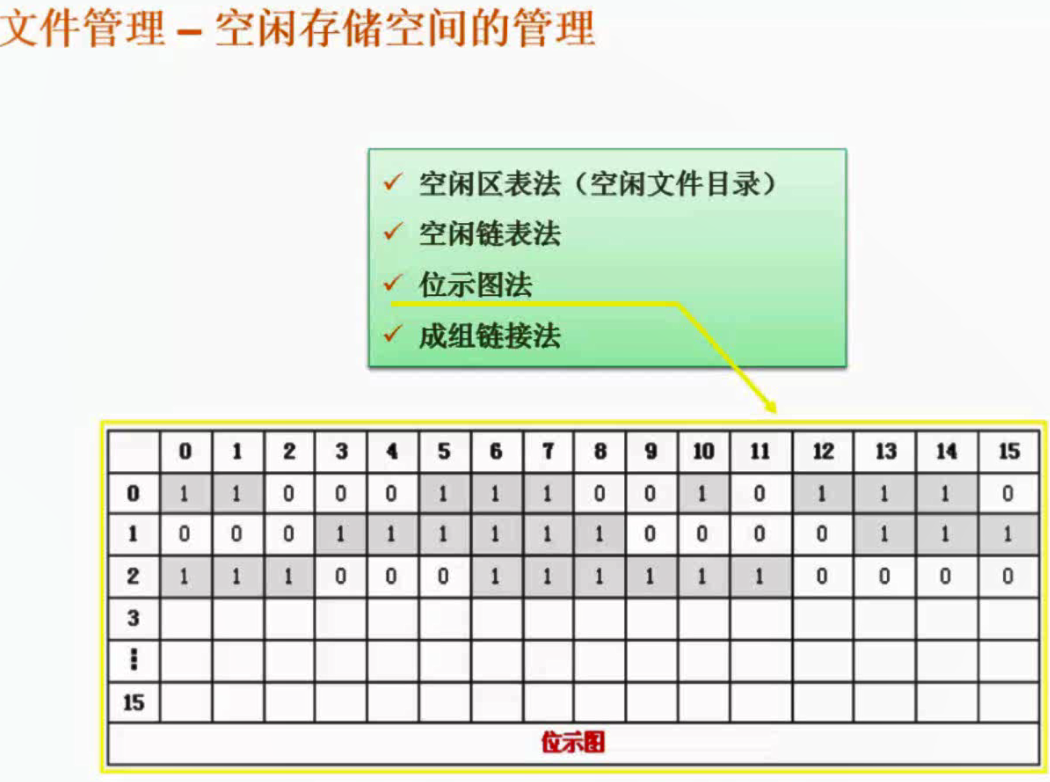
位示图法练习
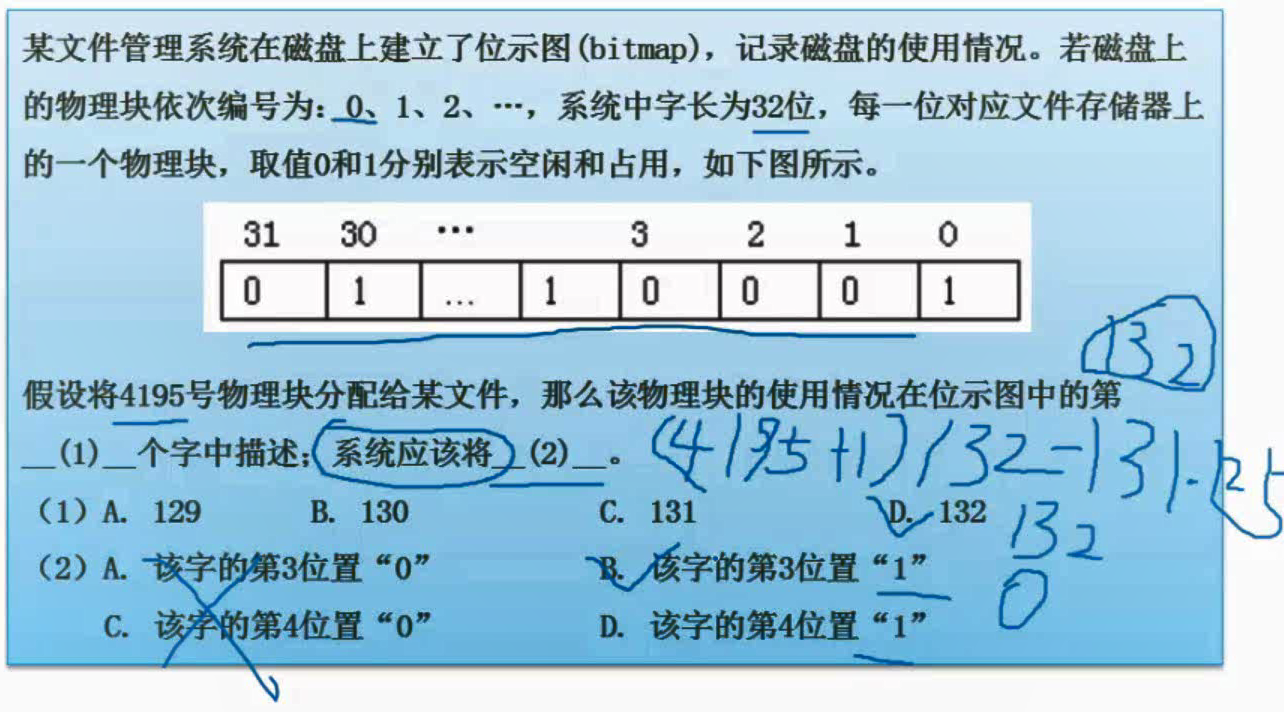
第一空
4195号即为第4196个物理块(因为从0号开始,所以要加一)
(4195+1)/32=131.25
所以是在第132个字中
第二空

前131个字,131*32=4192个,即0~4191号;所以第132字开头是从4192号开始(下标为0)、然后4193号(下标为1)、4194号(下标为2)、4195号(下标为3)
设备管理
数据传输控制方式
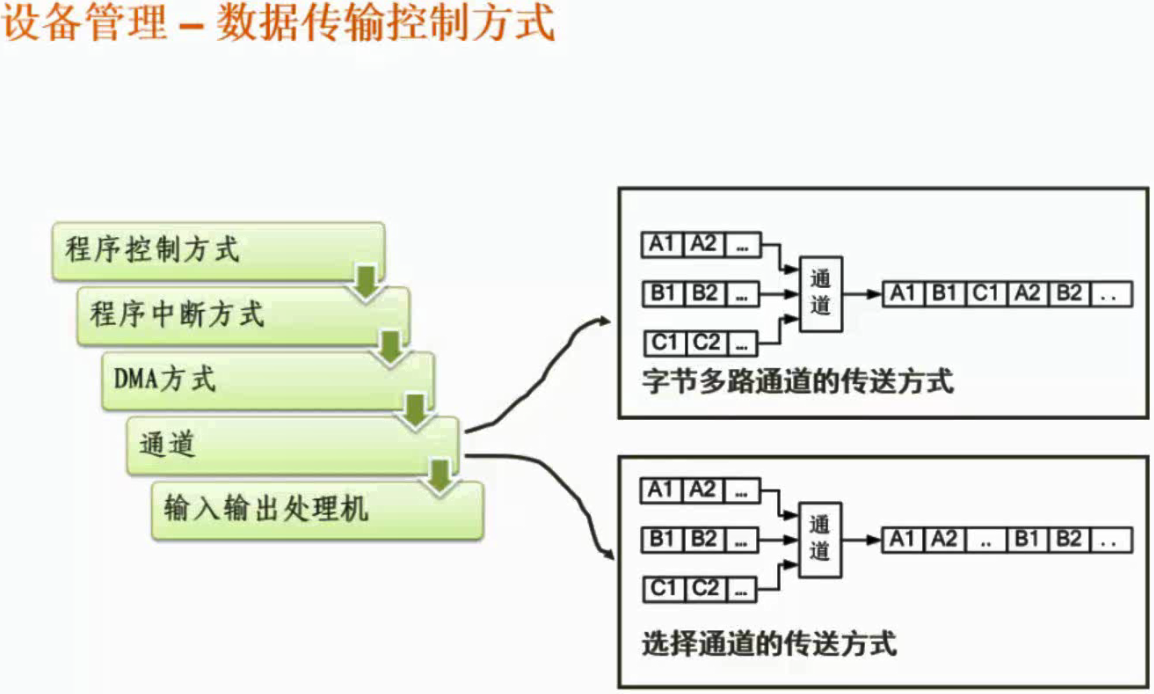
程序控制方式:由cpu介入,没有反馈,外设并不知道是否传输完成,只能由CPU去查询是否传输完成。
程序中断方式:主动性强,有中断机制,外设完成数据的传输后会发一个中断,系统就会做下一步处理。
DMA:直接存取控制方式,DMA控制器,外设和内存的数据交换由这个DMA控制器去完成。
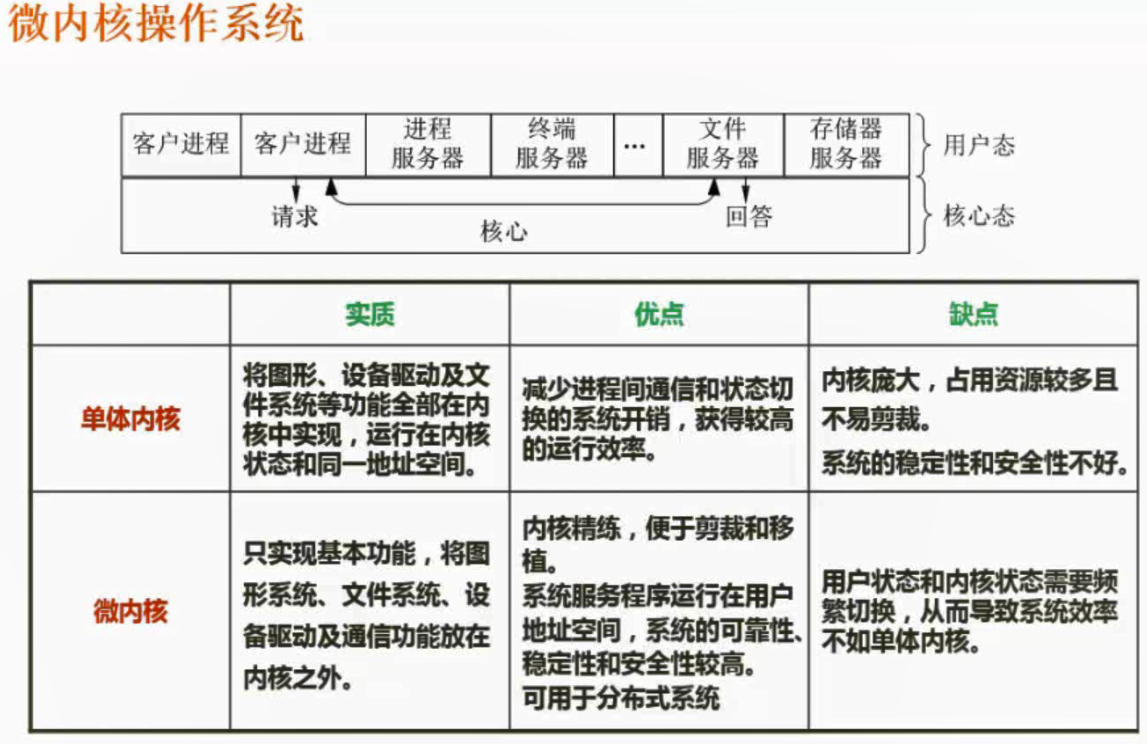
微内核操作系统


 浙公网安备 33010602011771号
浙公网安备 33010602011771号