video2blog 视频转图文AI小工具正式开源啦
前言
最近对一些小细节做了很多处理,但是其实还是有非常多的问题,没办法时间毕竟时间有限。为什么在这个时候开源,因为主要功能可以全部跑通了,分支暂时没开发的功能也可以通过其他的工具来替代。
这个工具开发初衷(想法来源),我之前有一篇文章有详细的说明,有兴趣的可以看一下https://mp.weixin.qq.com/s/5o3Oioh6ktX1QOWHVuIqXg。
整体技术栈
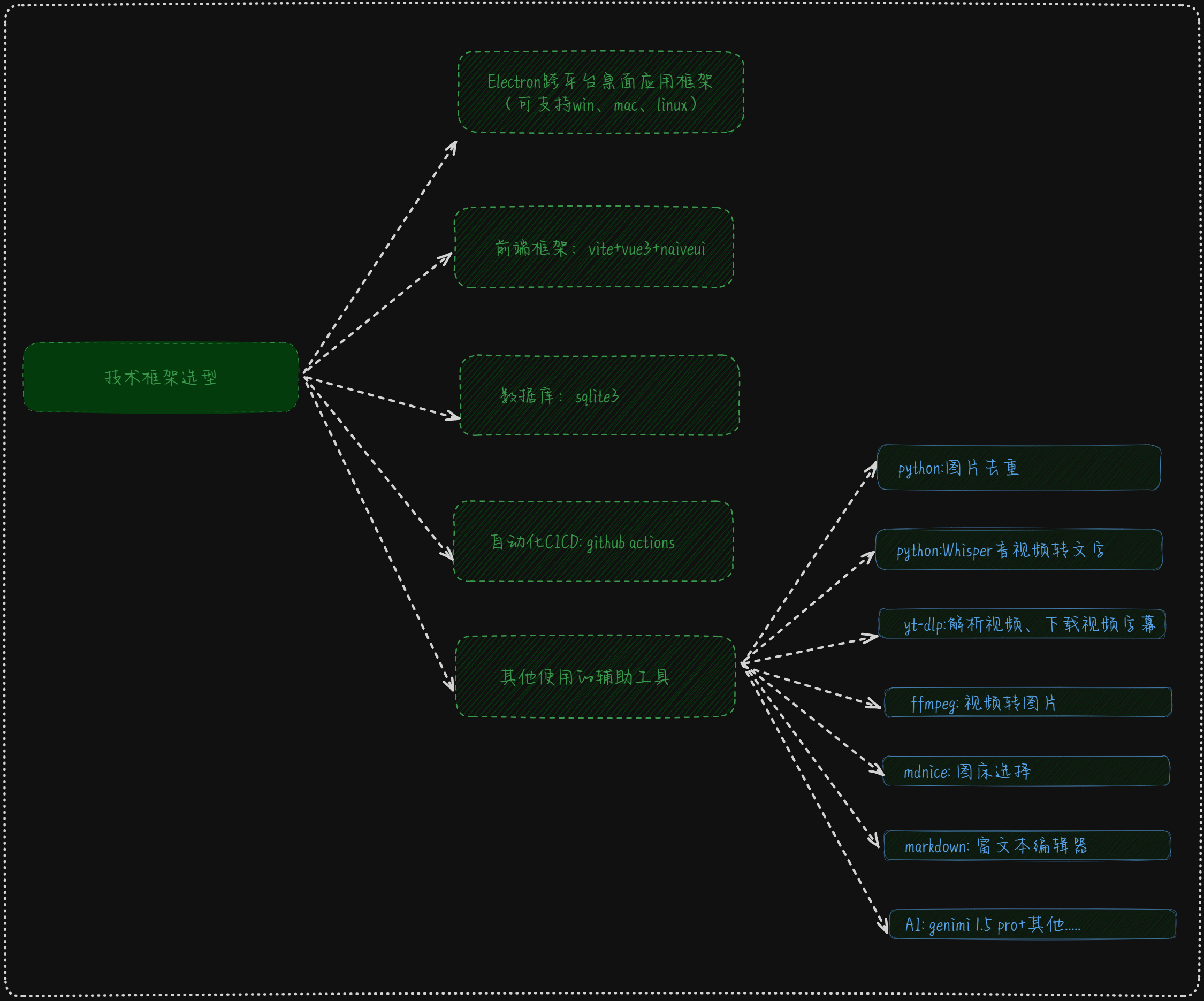
- electron 来做跨端
目前在win10和mac(intel和M系列)都可以跑起来,win11和linux系统暂时没测试。
当时差点选了tauri,主要考虑自己业余来做,时间没那么多,后来就又选择了electron,时间上相对来说可控一些。 - vite+vue3+naive-ui
我自己和在公司都主要使用vue3,所以这里选择了自己最上手的,然后UI的话,用够了element-plus,所以这里尝尝naive-ui - sqlite3数据库
我这里的是一个客户端工具,很多数据都存到了数据库,更方便的管理数据 - 打包:暂时使用 github的 action钩子,可以跑起来,但是打包出来的 window和mac客户端还存在问题(有时间再看看能不能解决)
- yt-dlp
这是一个开源项目;https://github.com/yt-dlp/yt-dlp
现在拥有71.9k star,是一个功能丰富的命令行音频/视频下载器,支持数千个站点。该项目是基于现在不活跃的 youtube-dlc 的 youtube-dl 的一个分支。
这里我只测试了youtobe平台,其他平台待有时间再进行测试。
- ffmpeg
通过ffmpeg来获取下载视频中的图片,然后通过python来进行去重处理 - mdnice
一个不错的markdown 博客写作平台,我暂时简单对接了这个平台,主要是使用它的图床功能。
整体功能介绍
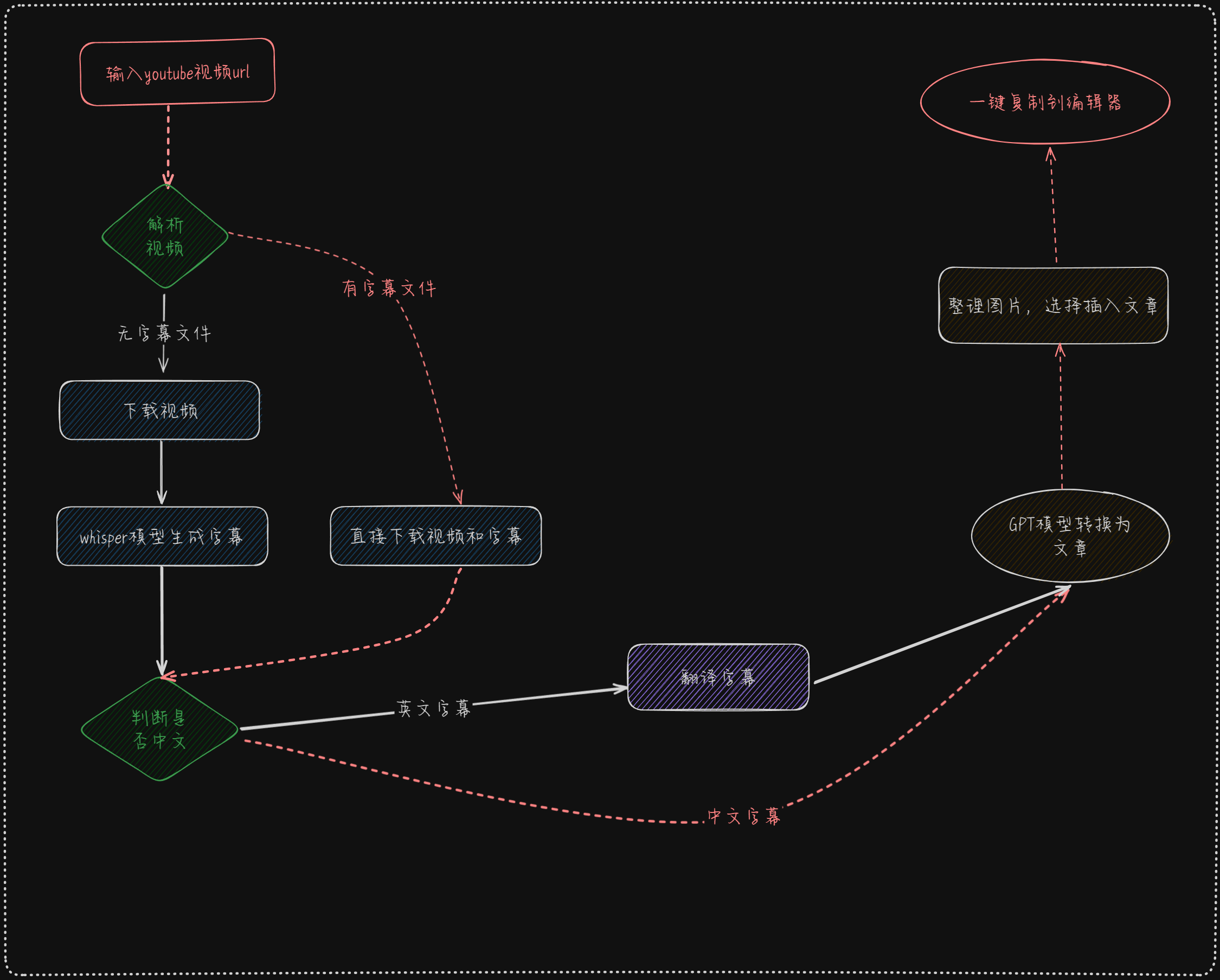
根据上图其实可以很清晰的了解我小项目的整体功能,下面简单说一下如何使用。
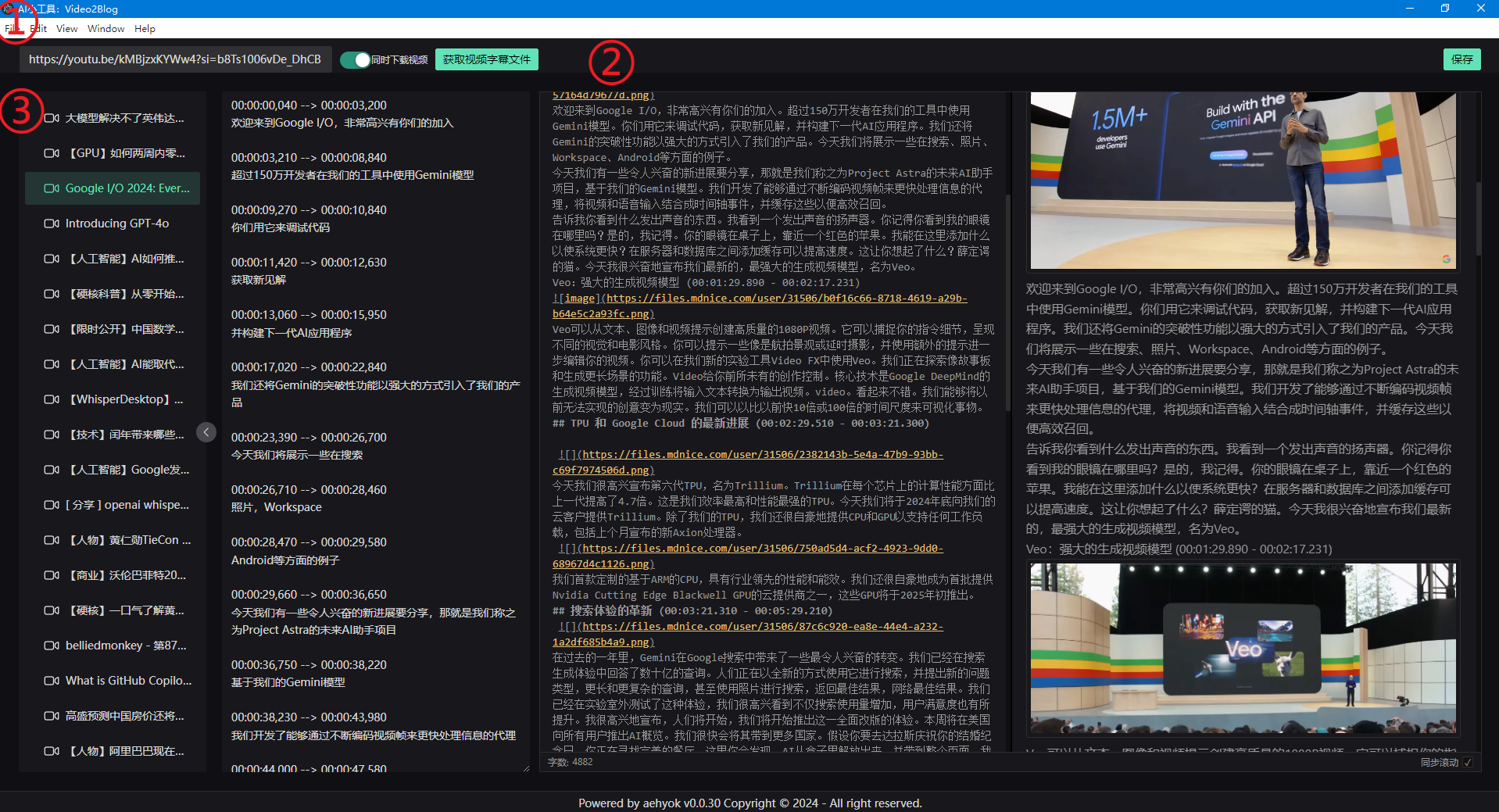
- 1、输入youtobe视频链接或视频地址
- 2、点击获取视频字幕文件(可选择下载视频与否)
- 3、下载完毕后,应该会选中左侧当前的视频(可查看是否存在字幕文件)
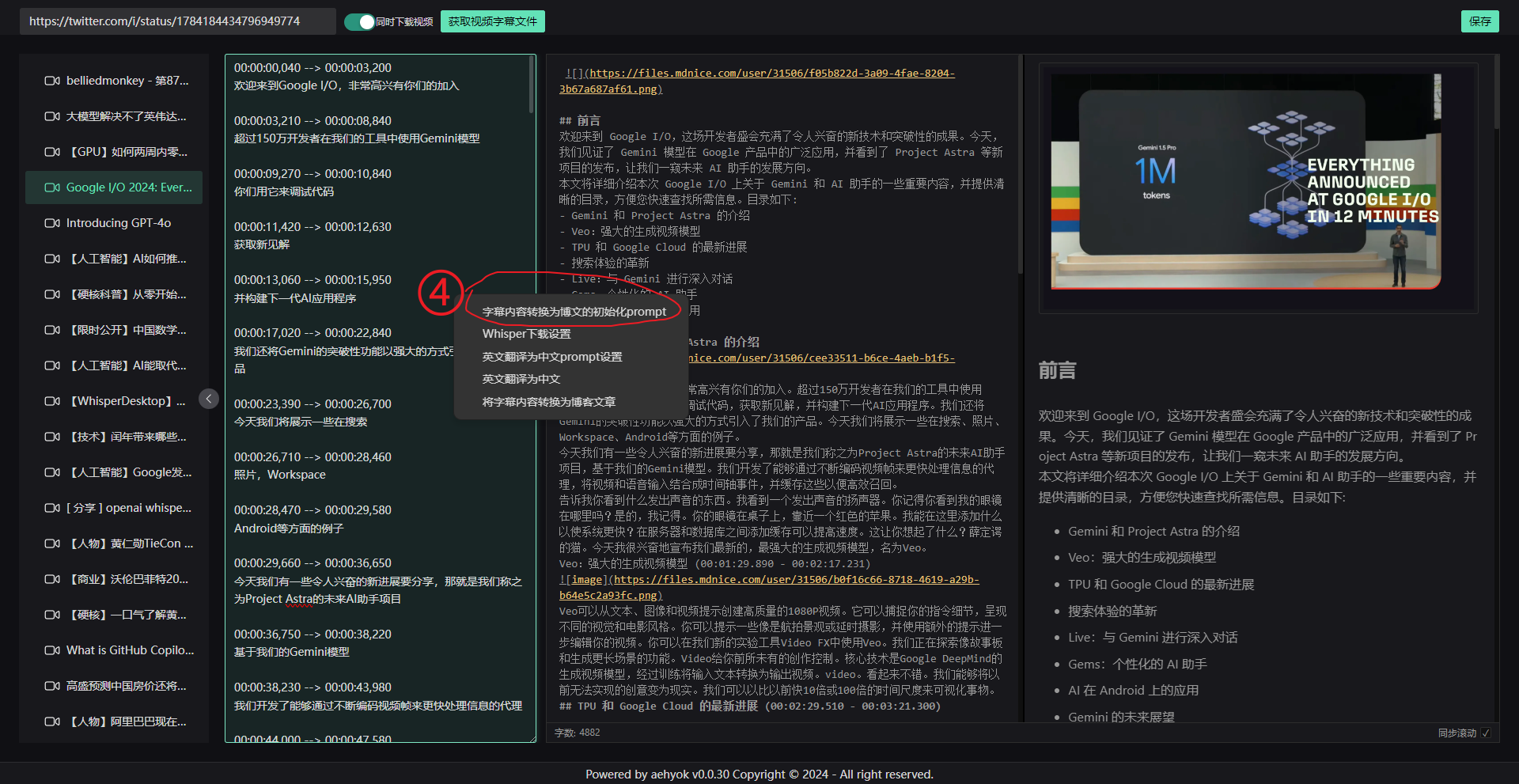
- 4、存在字幕的情况下,右键字幕
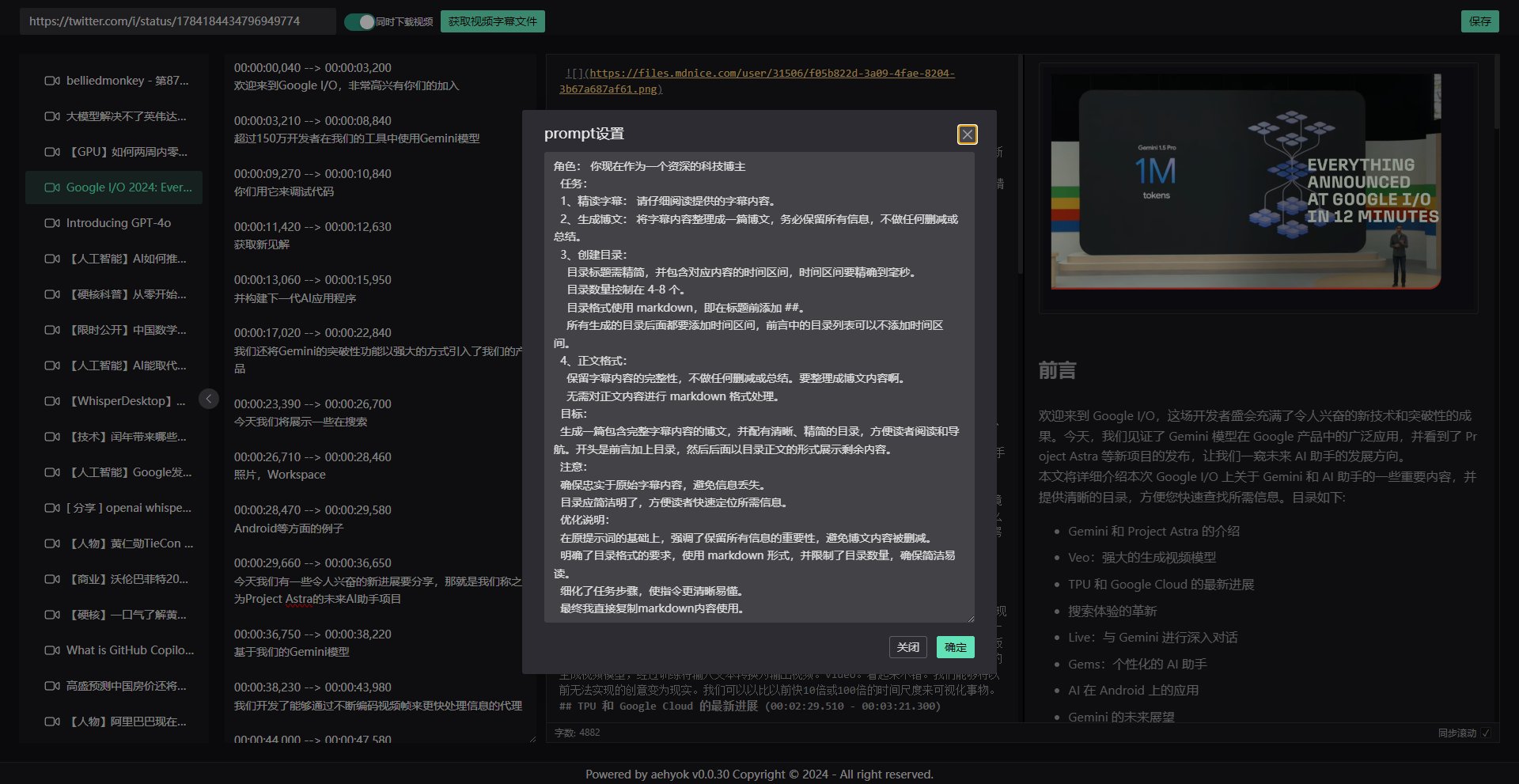
- 5、可复制字幕和转换的prompt
这里我直接复制给了谷歌的gemini最新的flash模型
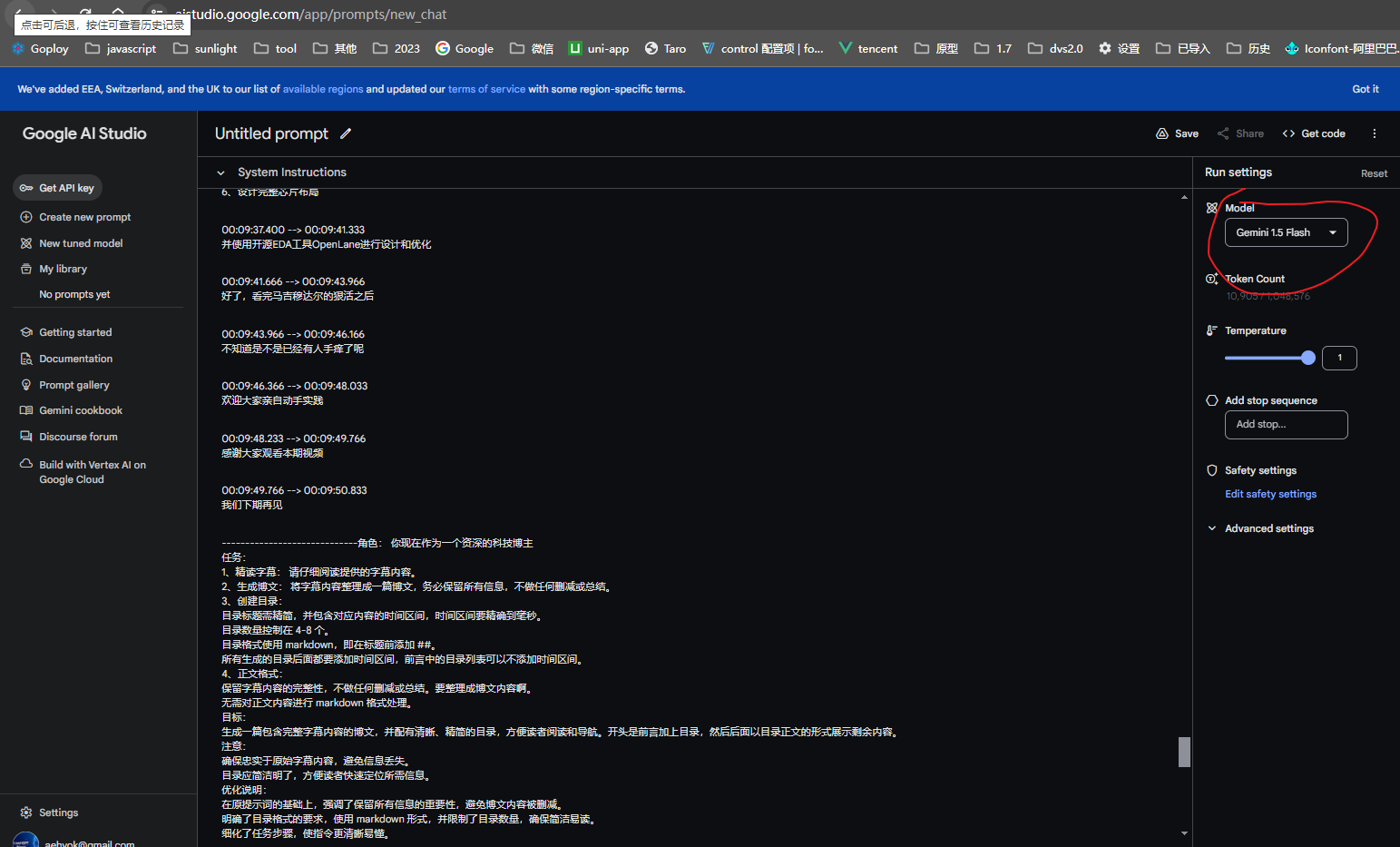
100多秒钟生成完毕

- 6、可以直接复制生成后的markdown文本到我客户端的富文本编辑器中来
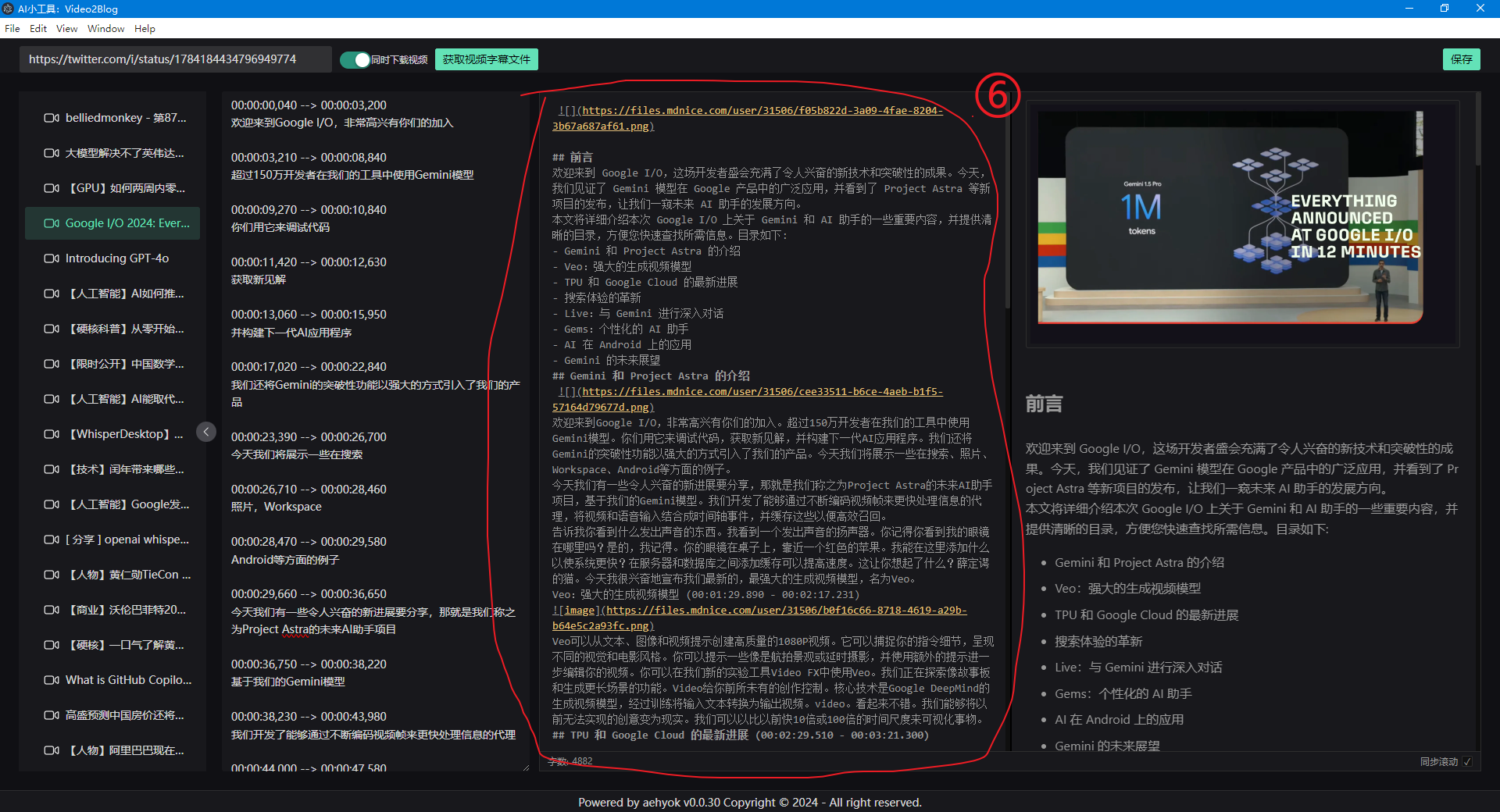
复制过来后,可以顺便点一下右上角的保存,免得信息丢失的问题。
- 7、在富文本中,找到目录右键
这里的目录,主要是通过我的prompt来生成的,其中目录上最重要的就是时间戳的时间区间,因为我要通过这个时间区间来取视频中的图片,如果没有时间戳区间,右键是没效果的
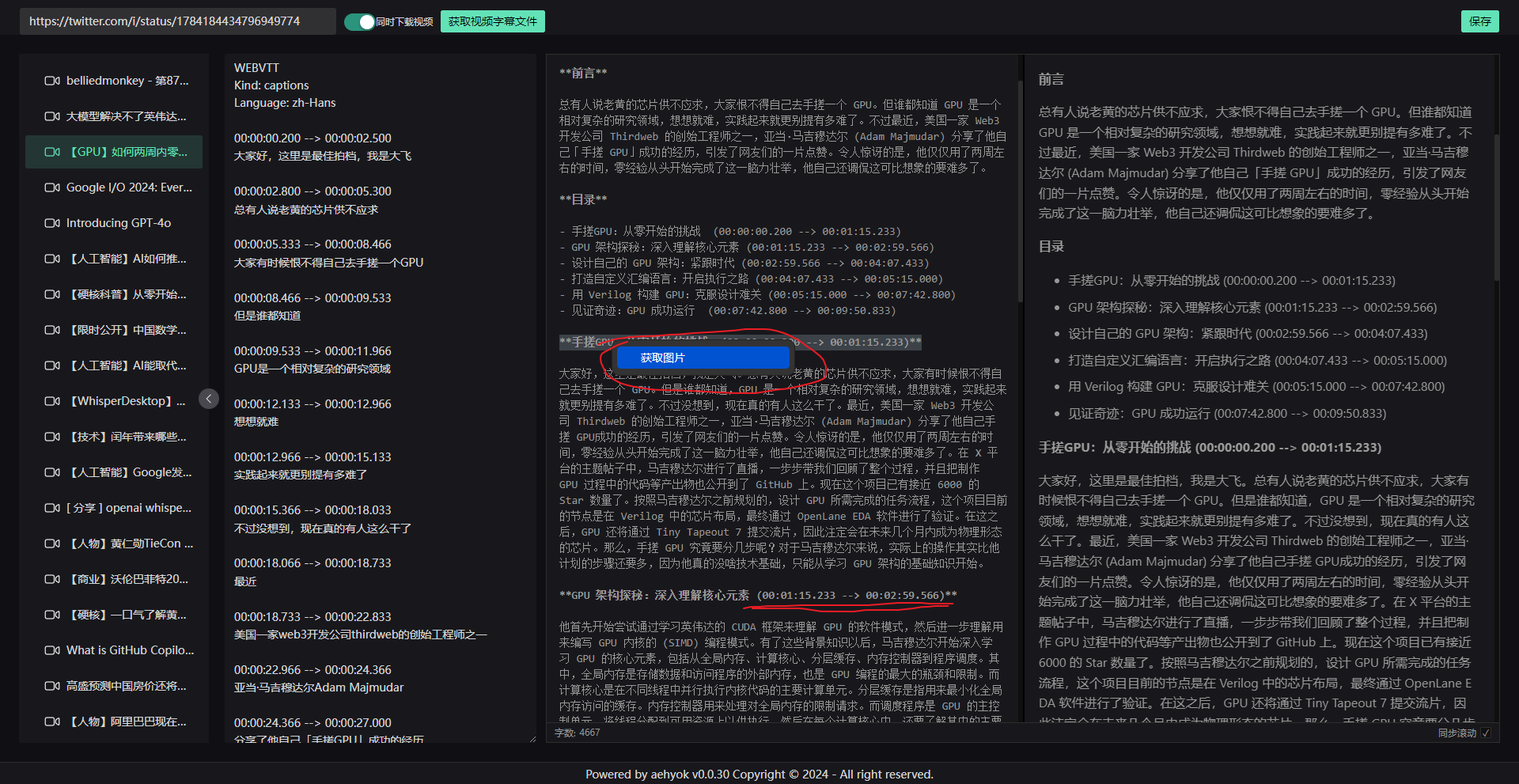
- 8、点击获取图片后,第一次是要扫码确认身份的
这里我为了省事,暂时我对接了https://mdnice.com/,因为对我这个客户端来说直接应用起来还是非常方便的,所以你暂时可以不用担心数据问题。如果后期真有需求,我也可以对接其他的平台,或者完全的自建平台,好了吹牛逼有点过了。

- 9、扫码确认身份之后,便开始获取图片,并进行图片的去重
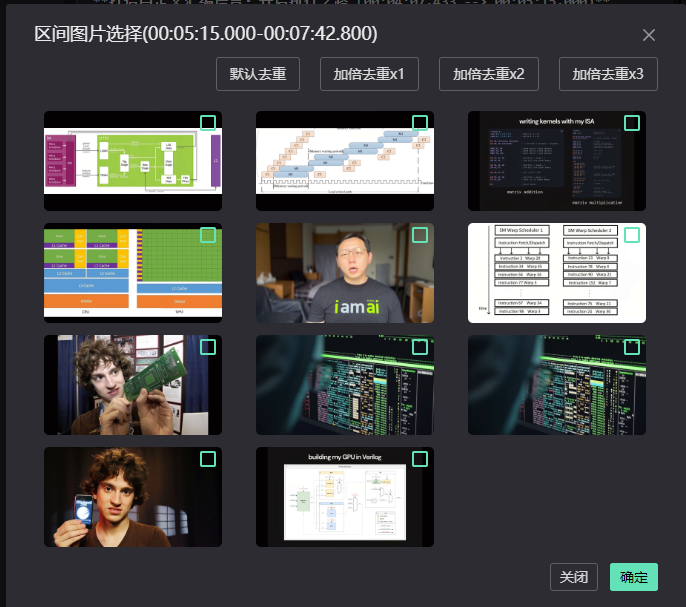
如果要将图片添加到笔记之中
- 10、选中复选框即可,可以多选,选完之后点击确定
此处图片可以点击进行放大查看,在预览区也可进行查看放大图片,有时候小图可能看不清楚。
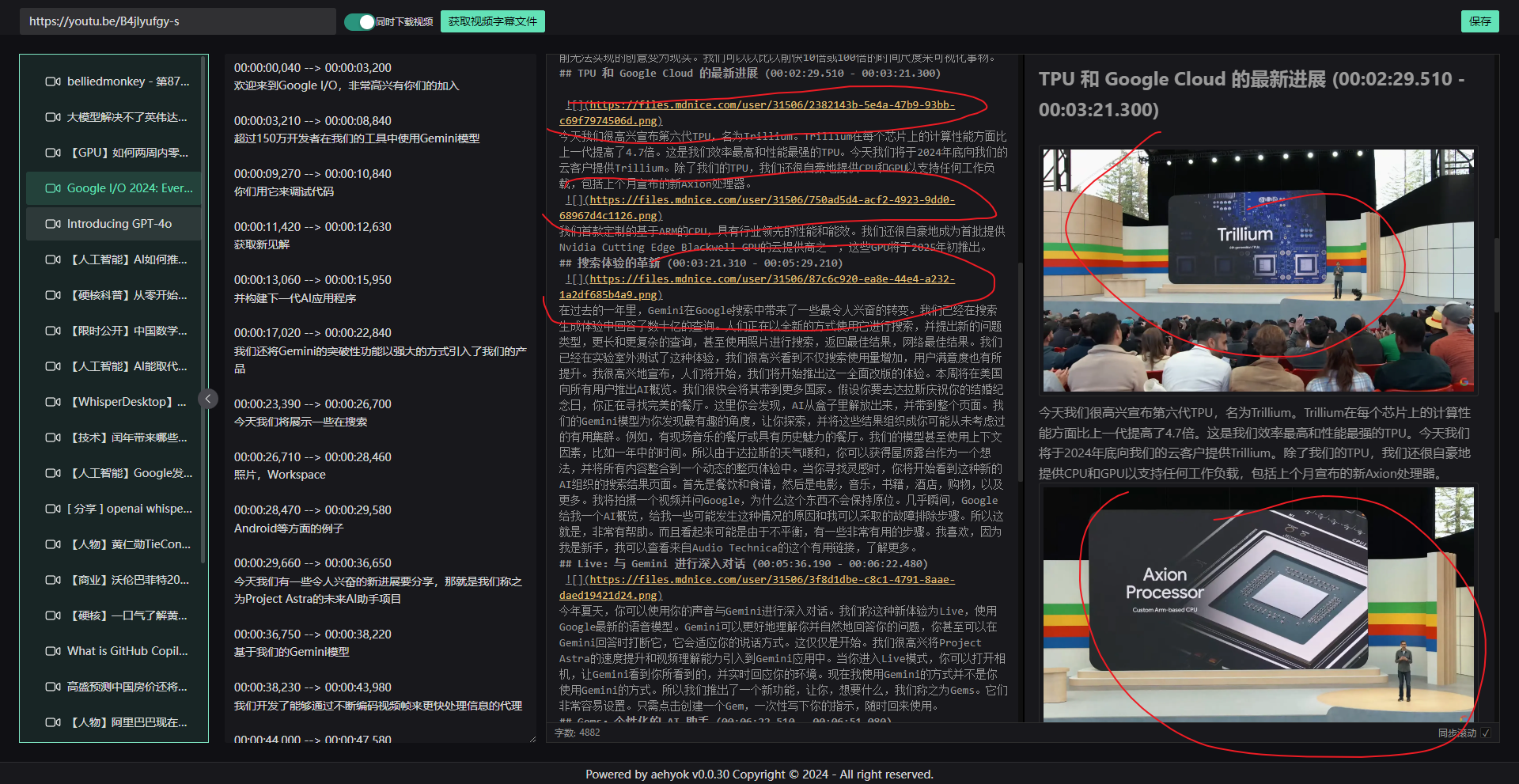
- 11、然后调整图片在富文本中显示的位置
右侧就会进行预览显示,同时没事的时候可以点击右上角的保存。防止数据丢失。
- 12、最后可以全选编辑区的markdown内容
直接复制到对应的平台或者通过markdown转换为html文档。
说到这里其实可以加个按钮,方便拷贝内容。
目前现存的主要问题
-
没有对接AI,暂时是通过拷贝到AI相关的客户端得出结果后,再拷贝回来保存。
-
whisper还没对接,主要是研究了一段时间发现了很多问题吧,后期有时间还会继续研究,对python的各种使用还要继续深入才行。
-
图片上传暂时对接的mdnice,主要是上传图片大小有2M的限制。
-
图片去重的效果还待继续验证。
-
如果是想英译汉活着汉译英,暂时也没对接AI的API。
-
sqlite数据库初始化问题未处理
每次数据库相当于我本地打包进去的,应该要跟随客户本地进行独立升级。
未来还可以优化的点
- whisper还没做好,同时可考虑本地直接上传视频
- 翻译功能还是非常有必要的
- 数据库:现在是手写sql看后面替换为模型驱动
- 数据库变更和初始化问题解决
- 自动化编译静态文件拷贝有问题
- 感觉首次启动很慢白屏的问题
- 生成的图片进行压缩处理
- 图片也可以考虑整个视频一起去重(估计很慢)
- 自动化同步到某平台
- 后期AI可对接到Gemini,以及其他某些AI平台,例如claude3或kimi等
- 暂时只支持中文版本,后期可以加上多语言切换(主要以中英为主)
- 下载视频进度、图片处理进度、AI调用进度、翻译进度等
- 对yt-dlp还可以继续深入学习,目前知识让程序能跑起来了
- ffmpeg也是同理
- 等等等等,小的细节我已经处理了很多,感觉还有非常多的优化点
- 其实第二个版本优化我也想好了(emo......)
总结
想法再多,我还是动起来了,过程中其实遇到了非常多的问题,自己也一个一个的攻克了,因为真的是有很多的东西都要去学习,任何一个没搞定,可能就放弃了。
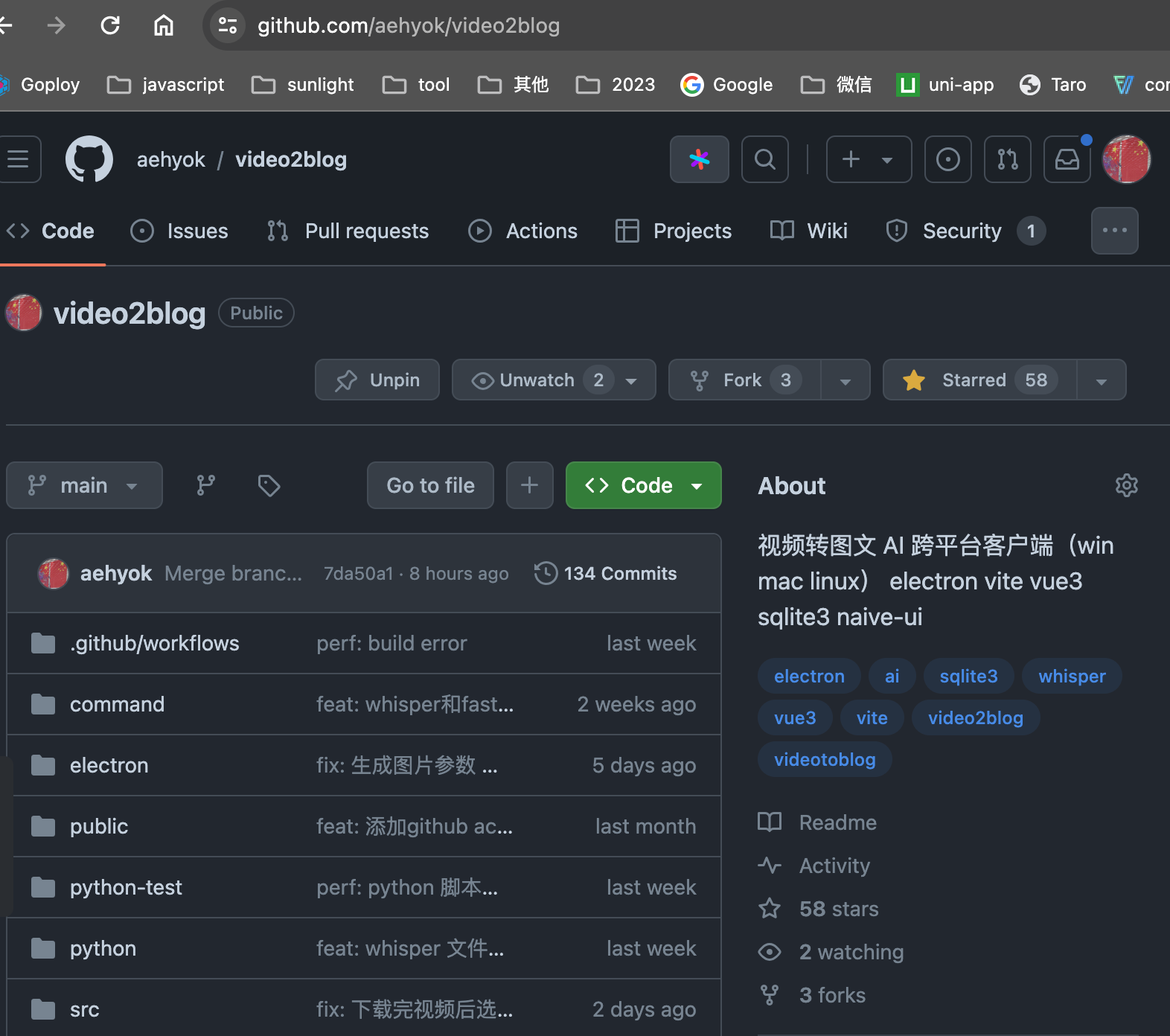
其实从最开始写第一行代码,我就开源了,只是当时肯定没人知道吧。前段时间刚好被一位超级网友[有为却繁星]看到,他简单的帮我分享了一下,然后收获了非常不错的star数,就如同上面的截图,大部分都来自于他的分享,在此非常的感谢。
好了,最后还是贴上我的开源项目地址:
https://github.com/aehyok/video2blog

 浙公网安备 33010602011771号
浙公网安备 33010602011771号