



关于PostgreSQL空间膨胀的研究
首先,我们先启用一个数据库自带的控件方便对数据情况进行分析
create extension pgstattuple;
然后,还需要一个存储过程方便快速的制造数据
create function f1(looptime numeric) returns void as $$ begin for i in 1..looptime loop insert into t1 values(i); end loop; end; $$ language plpgsql;
我们测试的表为
create table t1(col1 numeric);
以上准备完成后,就开始通过一个实验演示PG的空间膨胀问题,我们对数据库表T1做一些操作:
- 写入10000条数据
- 删除5000条数据
- 再写入5000条数据
那么按我们的理解应该是这样:
10000条数据占据了一定的磁盘空间;删除5000条数据之后,释放了一定的空间;再写入5000条数据,应该填充之前释放的空间。
实际执行情况是:
postgres=# select f1(10000); f1 ---- (1 row) postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 360 kB (1 row) postgres=# delete from t1 where col1<5001; DELETE 5000 postgres=# select f1(5000); f1 ---- (1 row) postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 536 kB (1 row)
我们通过两次查询发现t1表的空间从360KB变成了536KB,536/360=1.49,看起来并不像我们想的那样,新写入的5000条数据并没有使用删除5000条数据后空出的空间,而是重新开辟了存储空间,这就是PostgreSQL的空间膨胀问题。
PG的控件膨胀问题要从他的mvcc机制说起。
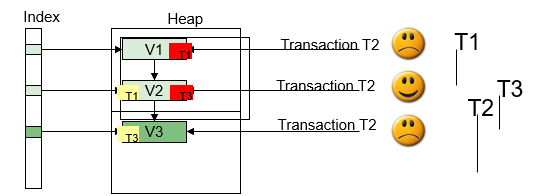
对于任何一个数据库来说多版本控制机制(MVCC)都是保证数据一致性的重要手段。上面图里的3个事务对同一条数据的处理会产生3个不同版本的数据。如果是Oracle数据库,除了最新版本的数据外其他数据都存储在Redo段的前镜像里,对于PG来说,之前版本的数据是存储在表空间内,随着时间和数据操作,表空间内的数据版本会越来越多,而已经不被任何事务需要的数据就会变成死数据(dead_tuple),这些死数据占据了数据库表的空间,又不能被重用,这就造成了表空间膨胀。
PG为了解决这个问题,提供了vacuum机制和autovacuum机制以及HOT机制来清理这些死数据。通过vacuum命令可以手动的发出指令,要求数据库对指定的表清理其死数据,该操作需要锁表。Autovacuum则是数据自动触发的清理操作,来清理死数据,默认1分钟清理1次。
接下来我们把T1表清掉(truncate语句在生产环境请慎用),再执行一次上面的操作,但是在三个位置分别加入1条新的语句
postgres=# truncate table t1; TRUNCATE TABLE postgres=# select f1(10000); f1 ---- (1 row) postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 360 kB (1 row) postgres=# select * from pgstattuple('t1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 368640 | 10000 | 290000 | 78.67 | 0 | 0 | 0 | 7380 | 2 (1 row) postgres=# delete from t1 where col1<5001; DELETE 5000 postgres=# select * from pgstattuple('t1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 368640 | 5000 | 145000 | 39.33 | 5000 | 145000 | 39.33 | 7380 | 2 (1 row) postgres=# select f1(5000); f1 ---- (1 row) postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 536 kB (1 row) postgres=# select * from pgstattuple('t1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 548864 | 10000 | 290000 | 52.84 | 5000 | 145000 | 26.42 | 6988 | 1.27 (1 row)
这里我们就能很清楚的看到T1表内的死数据了,在执行完一次插入后,表空间内有10000条有效数据,且没有死数据的(tuple_count=10000,dead_tuple_count=0),而我们删除数据以后表中有5000条有效数据,死数据5000,再次插入5000条数据后dead_tuple_count依然是5000,表内的有效数据是10000。就是这些死数据占据了空间。
前面说了PG为了解决这个问题,引入了autovacuum机制,默认是60s触发一次。我们什么都不做,过了一段时间以后,再次用语句检查T1表内的数据情况:
postgres=# select * from pgstattuple('t1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 548864 | 10000 | 290000 | 52.84 | 0 | 0 | 0 | 166988 | 30.42 (1 row)
发现dead_tuple_count清零了,而且free_percent变成了30.42%,这说明PG的autovacuum起作用了。
我们再次写入5000条数据,并检查空间:
postgres=# select f1(5000); f1 ---- (1 row) postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 536 kB (1 row) postgres=# select * from pgstattuple('t1'); table_len | tuple_count | tuple_len | tuple_percent | dead_tuple_count | dead_tuple_len | dead_tuple_percent | free_space | free_percent -----------+-------------+-----------+---------------+------------------+----------------+--------------------+------------+-------------- 548864 | 15000 | 435000 | 79.25 | 0 | 0 | 0 | 6988 | 1.27 (1 row)
这次表里的有效数据变成了15000,但表占据的磁盘空间依旧是536KB,这最新的5000条数据利用了autovacuum清理出来的空间,没有新开辟空间了。
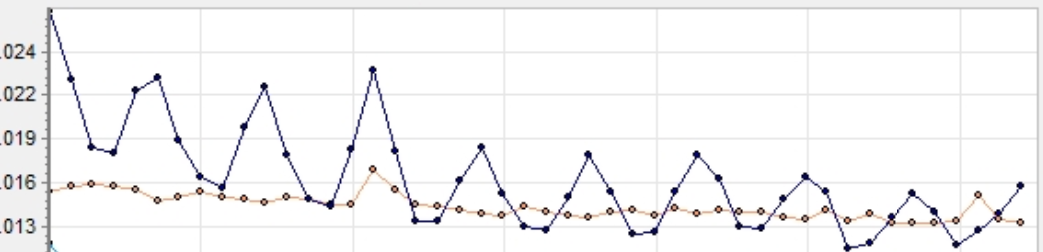
不过PG的autovacuum需要一定的资源开销,所以在做PG的性能测试的时候,你会发现图像经常是类似心电图的有规律性的出现性能毛刺(下图蓝色曲线)。
不仅是数据库表会出现这种空间膨胀,索引也会,而且在PG9.3之前autovacuum和vacuum对索引无效,我们在rebuild索引前,只能眼睁睁看着索引越变越大。所幸这个问题在9.6后的版本中解决掉了。
但是vacuum的回收是面对数据库的,不是面对操作系统的。也就是说被数据库占用的磁盘空间不能通过vacuum回收。如果要回收需要通过vacuum full命令。
postgres=# delete from t1 where col1<5001; postgres=# vacuum full t1; VACUUM postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 184 kB (1 row)
这里可以看到 在删除表内一半的数据,再通过vacuum full命令处理后,t1表占用的磁盘空间缩小了一半。
由于autovacuum进程的工作间隔,一个表或者索引在期间产生的最大死数据数基本就是膨胀的最大值。
我自己写了一个小脚本,每1秒更新t1表中的2000条数据,t1表一共有10000条数据,执行一段时间后,t1表的大小稳定在如下值:
postgres=# select pg_size_pretty(pg_relation_size('t1')); pg_size_pretty ---------------- 4152 kB (1 row)
每秒更新2000条数据,一个autovacuum内(1分钟)会产生120000条死数据,也就是说表膨胀的空间基本会在初始大小的13倍以内,而4152/360=11.5基本验证了我们的说法。

