

[转]That's Just the Way It Is - How NT Describes I/O Requests
Posted on 2012-07-04 08:58 Ady Lee 阅读(231) 评论(0) 编辑 收藏 举报As part of our effort to address some of the more rudimentary issues in writing NT drivers, we thought it would be a good idea to talk about IRPs and data buffers… a topic we’ve never really covered in any detail in The NT Insider before.
NT uses a packet-based architecture for describing I/O requests. In this approach, each I/O request to be performed can be described using a single I/O Request Packet, or IRP. When an I/O system service is issued (such as a request to create a file or read from a file), the I/O Manager services that request by building an IRP describing the request and passing a pointer to that IRP to a device driver to begin processing the request.
An IRP contains all the information necessary to fully describe an I/O request to the I/O Manger and device drivers. The IRP is a standard NT structure defined inNTDDK.H and named "IRP". Its structure is shown in Figure 1.
Figure 1 -- Structure of an IRP

As you can see in Figure 1, each I/O Request Packet may be thought of as having two parts: A "fixed" part, and an I/O Stack. The fixed part of the IRP contains information about the request that either does not vary from driver to driver, or does not need to be preserved when the IRP is passed from one driver to another. The I/O Stack contains information specific to each driver that may handle the request.
While the size of a particular IRP is fixed when it is created by the I/O Manager, every IRP the I/O Manager creates is not the same size. When the I/O Manager allocate an IRP, it allocates space for the fixed portion of the IRP plus enough space to contain at least as many I/O Stack locations as there are drivers in the driver stack that will process this request. Thus, if an I/O request were issued to write to a file on a floppy disk, the stack of drivers that process this request would likely be similar to the stack shown in Figure 2. The I/O Manager would create an IRP to describe this request that has at least two I/O Stack locations: One location for the file system driver, and a second location for the floppy disk device driver.
Notice that we said the IRP in the example will have at least two I/O Stack locations. To avoid allocating every IRP from NT’s non-paged pool, the I/O Manager maintains a pair of lookaside lists which hold pre-allocated IRPs. In NT V4.0 one of these lookaside list holds IRPs that have a single I/O Stack location.
The other lookaside list holds IRPs that have three I/O stack locations. The I/O Manager always attempts to use an IRP from these lists if possible. Thus, for an I/O request directed to a stack of two drivers, the I/O Manager will attempt to use one of the IRPs from the lookaside list of IRPs having three I/O Stack locations. If there are no IRPs available on the appropriate look-aside list, or if an IRP with more than three I/O stack locations is needed, the I/O Manager simply allocates the IRP from non-paged pool.
As we said earlier, the fixed part of the IRP contains information that either does not vary from driver to driver or does not need to be preserved when the IRP is passed from one driver to another. Particularly interesting or useful fields in the fixed portion of the IRP include the following:
- MdlAddres, UserBuffer and AssociatedIrp.SystemBuffer – These fields are used to describe the requestor’s data buffer, if one is associated with the I/O operation. More about this later.
- Flags – As the name implies, this field contains flags that (typically) describe the I/O request. For example, if the IRP_PAGING_IO flag is set in this field, this indicates the read or write operation described by the IRP as a paging request. Similarly, the IRP_NOCACHE bit indicates that the request is to be processed without intermediate buffering. This field is typically only of interest to file systems.
- IoStatus – When an IRP is completed, the field IoStatus.Status is set by the completing driver to the completion status of the I/O operation, and the field IoStatus.Information is set by the driver to any additional information to be passed back to the requestor in the second longword of the I/O Status Block. Typically, IoStatus.Information will contain the number of bytes actually read or written by a transfer request.
- RequestorMode – Indicates the mode (KernelMode or UserMode) from which the request was initiated.
- Cancel, CancelIrql, and CancelRoutine – Used if the IRP needs to be canceled while in progress. Cancel is a BOOLEAN which, when set to TRUE by the I/O Manager, indicates that this IRP is being canceled. CancelRoutine is a pointer, set by a driver while holding this IRP in a queue, to a function for the I/O Manager to call to have the driver cancel the IRP. Since the CancelRoutine is called at IRQL DISPATCH_LEVEL,CancelIRQL is the IRQL to which the driver should return. (See Volume 4 Issue 6 of The NT Insider for Part I of an article on Cancel Processing).
- Tail.Overlay.Thread – Pointer to the ETHREAD of the requesting thread.
- TailOverlay.ListEntry – Location which may be used by a driver for queuing while it owns the IRP.
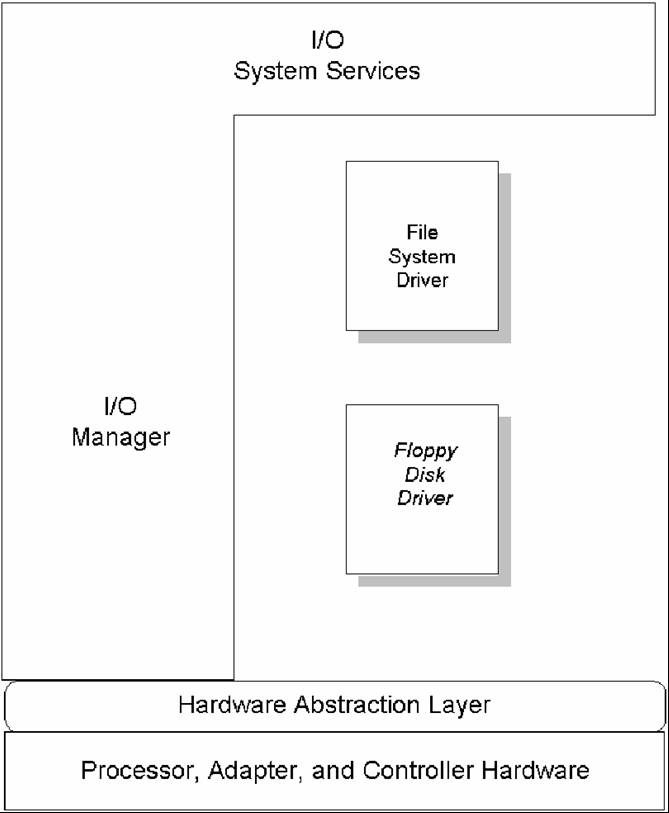
Figure 2 -- Example Driver Stack
Each I/O Stack location in an IRP contains information for a specific driver about the I/O request. The I/O Stack location is defined by the structureIO_STACK_LOCATION in NTDDK.H. To locate the current I/O Stack location within a given IRP, a driver calls the function IoGetCurrentIrpStackLocation(…). A pointer to the IRP is the sole parameter on the call. The return value is a pointer to the current I/O Stack location.
When the I/O Manager initially allocates the IRP and initializes its fixed portion, it also initializes the first I/O Stack location in the IRP. The information in this location corresponds with information to be passed to the first driver in the stack of drivers that will process this request. Fields in the I/O Stack location include the following:
- MajorFunction – The major I/O function code associated with this request. This generally indicates the type of I/O operation to be performed.
- MinorFunction – The minor I/O function code associated with the request. When used, this will modify the major function code. Minor functions are almost exclusively used by network transport drivers and file systems, and are ignored by most device drivers.
- Flags – Processing flags specific to the I/O function being performed. This field is mostly of interest to file systems drivers.
- Control – A set of flags that are set and read by the I/O Manager, indicating how it needs to handle this IRP. For example, the SL_PENDING bit is set in this field (by a driver’s call to the function IoMarkIrpPending(…)) to indicate to the I/O Manager how completion is to be handled. Similarly, the flags SL_INVOKE_ON_CANCEL, SL_INVOKE_ON_ERROR, and SL_INVOKE_ON_SUCCESS indicate when the driver’s I/O Completion Routine should be invoked for this IRP.
- Parameters – This field comprises several sub-members, each specific to the particular I/O major function being performed.
- DeviceObject – This field contains a pointer to the device object that is the target of this I/O request.
- FileObject – A pointer to the file object associated with this request.
After the fixed portion of the IRP and the first I/O Stack location in the IRP are appropriately initialized, the I/O Manager calls the top driver in the driver stack at its dispatch entry point corresponding to the major function code for the request. Thus, if the I/O Manager has just built an IRP to describe a read request, he will call the first driver at his read dispatch entry point. A pointer to the IRP that was just built, and a pointer to the device object corresponding to the device on which the driver is to process the request, are passed as parameters by the I/O Manager to the driver at the dispatch entry point.
Describing Data Buffers
The descriptor for the requestor’s data buffer appears in the fixed portion of the IRP. Windows NT provides driver writers three different options for how it can describe the requestor’s data buffer associated with an I/O operation:
- The buffer may be described in its original location in the requestor’s physical address space by a structure called a Memory Descriptor List (MDL). This is called Direct I/O.
- The data from the buffer may be copied from the requestor’s address space into an intermediate location in system address space, and the driver is provided a pointer to this copy of the data. This is called Buffered I/O.
- The driver is provided the requestor’s virtual address of the buffer. This description method is called Neither I/O.
Drivers must choose a single method for the I/O Manager to use to describe all the read and write requests that are sent to a particular device. The choice is made (typically at initialization time when the Device Object is created) by setting bits in the Flags field of the Device Object. A different method from the one chosen for read and write requests, however, may be used for each Device I/O Control (IOCTL) code supported by the driver.
If a driver chooses Direct I/O, any data buffer associated with read or write I/O requests will be described by the I/O Manager using an opaque structure called a Memory Descriptor List (MDL). This MDL describes the data buffer in its original location within the requestor’s physical address space. The address of the MDL is passed to the driver in the IRP in the MdlAddress field.
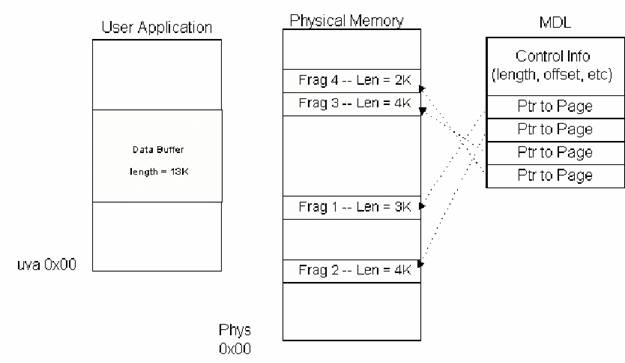
Figure 3 -- Diagram of an MDL
Before the IRP is passed to the driver, the I/O Manager checks to ensure the caller has appropriate access to the entire data buffer. If the access check fails, the request is completed by the I/O Manager with an error status, and the request is never passed on to the driver.
After the access check is completed, but still before the IRP is passed to the driver, the I/O Manager locks the physical pages that comprise the data buffer in memory. If this operation fails (e.g., due to the data buffer being too large to fit into memory at one time), the request is completed by the I/O Manager with an error status. If the locking operation succeeds, the pages remain locked for the duration of the I/O operation (until the IRP is ultimately completed).
An MDL is capable of describing a single virtually contiguous data buffer, which of course may not be physically contiguous. It is designed to make it particularly fast and easy to get the physical base addresses and lengths of the fragments that comprise the data buffer. The definition for the MDL structure appears inNTDDK.H. Figure 3 contains a diagram of the MDL.
Figure 4 -- MDL Fields

Even though the structure of an MDL is well known, it is one of the few truly opaque data structures in Windows NT. By opaque we mean that the structure of the MDL can never be assumed by a driver. Thus, the fields of the MDL should never be directly referenced by a driver. The I/O and Memory Managers provide functions for getting information about a data buffer using an MDL. These functions include:
· MmGetSystemAddressForMdl(…) – Returns a kernel virtual address that may be used in an arbitrary thread context to refer to the buffer that the MDL describes. As can be seen from Figure 4, one of the fields in the MDL contains the mapped system virtual address associated with the MDL, if one exists. This function is in fact a macro that appears in NTDDK.H. The first time this function is called, it calls MmMapLockedPages(…) to map the buffer into kernel virtual address space. The returned kernel virtual address is then stored in the MappedSystemVa field of the MDL. On subsequent calls to MmGetSystemAddressForMdl(…), the value that was previously stored in MappedSystemVa is simply returned to the caller. Any mapping that is present is deleted when the MDL is freed (i.e. when the I/O request is ultimately completed).
· IoMapTransfer(…) – This function is used primarily by DMA device drivers to get the base address and length of each of the fragments of the data buffer.
· MmGetMdlVirtualAddress(…) – This function (actually a macro in NTDDK.H) returns the requestor’s virtual address of the buffer described by the MDL. This virtual address is only of direct use in the context of the calling process. However, this function is frequently used by DMA device drivers as the requestor’s virtual address is one of the input parameters to IoMapTransfer(…).
· MmGetMdlByteCount(…) – Another macro from NTDDK.H, this function returns the length of the buffer described by the MDL.
· MmGetMdlByteOffset(…) – This function, which is yet another macro in NTDDK.H, returns the offset to the start of the data buffer from the first page of the MDL.
One particularly interesting field in the MDL is the field Next. This field is used to build "chains" of MDLs that together describe a single buffer that is not virtually contiguous. Each MDL in the chain would describe a single virtually contiguous buffer. MDL chains are designed for use by network drivers only, and are not supported by most of the I/O Manager’s standard functions. Therefore, MDL chains may not be used by standard device driver in Windows NT.
Direct I/O is most often used by "packet based" DMA device drivers. However, it may be used by any type of driver that wants to transfer data directly between a user buffer and a peripheral without having the overhead of rebuffering the data (as would be the case for Buffer I/O), and without having to perform the transfer in the context of the calling process (as would be the case for Neither I/O).
When an IRP is ultimately completed (by calling IoCompleteRequest(…)), and the MdlAddress field is non-zero, the I/O Manager unmaps and unlocks any pages which were mapped and locked, and then frees the MDL associated with the IRP.
An alternative to Direct I/O is Buffered I/O. In this scheme an intermediate buffer in system space is used as the data buffer. The I/O Manager is responsible for moving the data between the intermediate buffer and the requestor’s original data buffer. The system buffer is deallocated by the I/O Manager when the IRP describing the I/O request is ultimately completed.
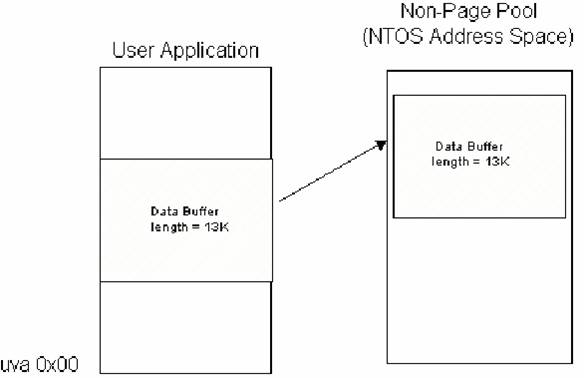
Figure 5 -- Buffered I/O Write
To prepare a Buffered I/O request, the I/O Manager checks to ensure the caller has the appropriate access to the entire length of the data buffer, just as it did for Direct I/O. If the caller does not have appropriate access, the request is completed and is not passed along to the driver. As an optimization, this check is not performed if the request originated in Kernel Mode.
The I/O Manager next allocates a system buffer from non-paged pool with a size equal to that of the data buffer. If this is a write operation, the I/O Manager then copies the data from the requestor’s buffer to the intermediate buffer. Whether the request is for a read or a write, the kernel virtual address of the intermediate buffer is passed to the driver in the AssociatedIrp.SystemAddress field of the IRP. Note that even though this field is part of the "AssociatedIrp" structure in the IRP, this use of the field has nothing to do with associated IRPs! Since the address of the intermediate buffer corresponds to a location in the system’s non-paged pool, the address is usable by the driver in an arbitrary thread context. Of course, the system buffer is virtually contiguous. There is no guarantee, however, that the system buffer will be physically contiguous.
When using Buffered I/O, the memory pages comprising the original data buffer are not locked during the I/O operation. Thus, their ability to be paged is not affected by the I/O operation.
When a read operation using Buffer I/O is ultimately completed, the I/O Manager is responsible for copying the data from the intermediate buffer back to the requestor’s data buffer. As an optimization, the I/O Manager delays this copy operation until the thread issuing the I/O request is next scheduled (using a "special Kernel APC for I/O completion"). When the requestor’s thread is next ready to run, the I/O Manager copies the data from the intermediate system buffer back to the requestor’s buffer, and frees the system buffer. This optimization not only avoids possible page thrashing, it also serves a "cache warming" function – pre-loading the processor cache with data from the buffer, so it is ready for rapid access by the requestor on return from the I/O request.
Buffered I/O is most often used by drivers that control programmed I/O devices which use small data transfers. In this case, it is usually very convenient to have requestor’s data described using a system virtual address.
The final option for having a requestor’s data buffer described by the I/O Manager is called "Neither I/O". It is called this simply because the driver requests neither Buffered I/O nor Direct I/O. In this scheme the I/O Manager provides the driver the requestor’s virtual address of the data buffer. The buffer is not locked into memory; No intermediate buffering of the data takes place. The address is passed in the IRP’s UserBuffer field.
Obviously, the requestor’s virtual address is only useful in the context of the calling process. As a result, the only drivers that can make use of Neither I/O are drivers that are entered directly from the I/O Manager, with no intermediate drivers above them, and can process (and, typically, complete) the I/O operation in the context of the calling process. Therefore, drivers for conventional storage devices can’t use Neither I/O, since their Dispatch routines are called in an arbitrary thread context. Most typical device drivers also can’t make use of Neither I/O, since these drivers’ I/O requests are often started from the DPC routine and thus are in an arbitrary thread context.
If used appropriately, and carefully, Neither I/O can be the most optimal method for some device drivers, however. For example, if a driver performs most of its work synchronously, in the context of the calling thread, Neither I/O saves the overhead of creating an MDL or recopying the data that would be required by the other methods. Even if such a driver occasionally intermediately buffers the data or creates a descriptor that allows the data buffer to referenced from in arbitrary thread context, the overhead saved by Neither I/O may be worthwhile.
How do you decide whether to use Direct I/O, Buffered I/O, or Neither I/O in your driver? There’s one case where the choice is made for you: If you are writing an Intermediate driver that will be layered above another driver, you must use the same buffering method that the device below you uses.
For device drivers, the choice is clearly an architectural decision that will affect both the complexity and performance of the driver. If you have a compelling reason to use Neither I/O, and you can meet the requirements for its use, you should choose Neither I/O.
Most drivers however, will not use Neither I/O due to the constraints involved. Drivers that transfer at least a page of data or more at a time will usually perform best using Direct I/O. While the I/O Manager will lock the pages in memory for the duration of the transfer, the overhead of recopying the data to an intermediate buffer will be avoided. Using Direct I/O for large transfers also avoids tying up large amounts of system pool. Also, most DMA drivers will want to use Direct I/O. Drivers for packet based DMA devices will want to use it since this allows them to easily get the physical base address and length of the fragments that comprise the data buffer. Drivers for "common buffer" DMA devices will want to use it to avoid the overhead of an additional copy operation.
Drivers that move data relatively slowly using Programmed I/O, and have operations that pend for long periods of time, as well as drivers that transfer data is small blocks, will most profitably make use of Buffered I/O. These include drivers for traditional serial and parallel port devices, as well as most simple machine control drivers. Buffered I/O is the simplest method to implement, since a pointer to a virtually contiguous buffer in system space containing the data is provided in the IRP.
While the choice of Buffered versus Direct I/O is an important one, it is far from critical in most cases. It has been our experience that first time NT driver writers often spend inordinate amounts of time worrying about which method to use. If it is not clear which method you should use in your driver, and you’re writing a driver for a programmed I/O type device, start by using Buffered I/O. Once your driver is written, you may wish to experiment to see if switching to Direct I/O will get you any performance gains. After all, the only difference between the two from a programming standpoint is where you look in the IRP for your information (Irp->AssociatedIrp.SystemBuffer, versus Irp->DmaAddress), and one function call (to MmGetSystemAddressForMdl(…) to get a system virtual address mapping a buffer described by an MDL). Hardly a problem at all!

