大数据竞赛(高职组)
大数据平台环境搭建(10 分)
- Docker基本操作
- Hadoop 完全分布式安装配置
- Spark安装配置
- Flink安装配置
- Hive 安装配置
- Kafka 安装配置
- Flume 安装配置
- ClickHouse 安 装 配 置
- HBase 安装配置
- 总结
基于Docker 环境,进行大数据相关平台组件安装配置
数据采集(15 分)
-
Spark 数据读取、数据存储
使用Spark抽取MySQL指定数据表中的增量数据到ods层的指定的分区表中 -
Flume数据采集
使用Flume采集某端口的实时数据流并存入Kafka指定的Topic中 -
Maxwell 数据采集
使用Maxwell采集MySQL的binlog日志并存入Kafka指定的Topic中
实时数据处理(25分)
- 使用 Scala 语言基于 Flink 完成 Kafka 中的数据消费
- 将数据分发至 Kafka 的 dwd层中
- 在 HBase 中进行备份同时建立 Hive 外表
- 基于 Flink 完成相关的数据指标计算
- 将计算结果存入 Redis、ClickHouse 中
离线数据处理(20分)
- 使用Spark对ods层中的离线数据进行清洗,包括数据合并、去重、排序、数据类型转换等操作
- 将清洗完的数据存入dwd层中
- 根据dwd层的数据使用Spark对数据进行处理计算
- 将计算结果存入MySQL、HBase、ClickHouse中
数据可视化(15 分)
- 编写前端 Web 界面(不确定要不要,好像重点可视化就行了)
- 调用后台数据接口
- 使用 Vue.js、ECharts 完成数据可视化(柱状图、折线图、饼状图等)
综合分析报告(10 分)
- 根据项目要求,完成综合分析报告编写。
- 主要评分点包括能够按照赛项要求进行综合分析。
职业素养(5 分)
- ???
关于这我还能写什么?
个人总结
-
最好自行提前适应一下比赛提供的工具,别自己瞎搞,到时候发现完全不对劲,下图是官方 PDF 的截图。
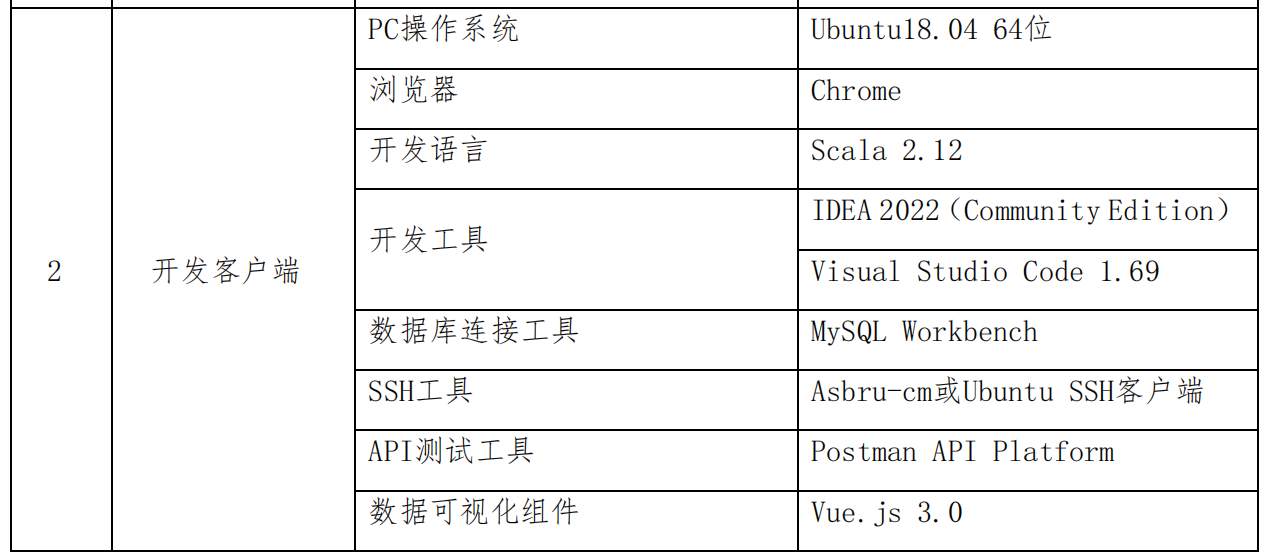

-
因为比赛服务器组件环境是要自己搭建的,所以就自己从头弄吧,不过最好用他指定的版本号,避免出现不兼容等问题。
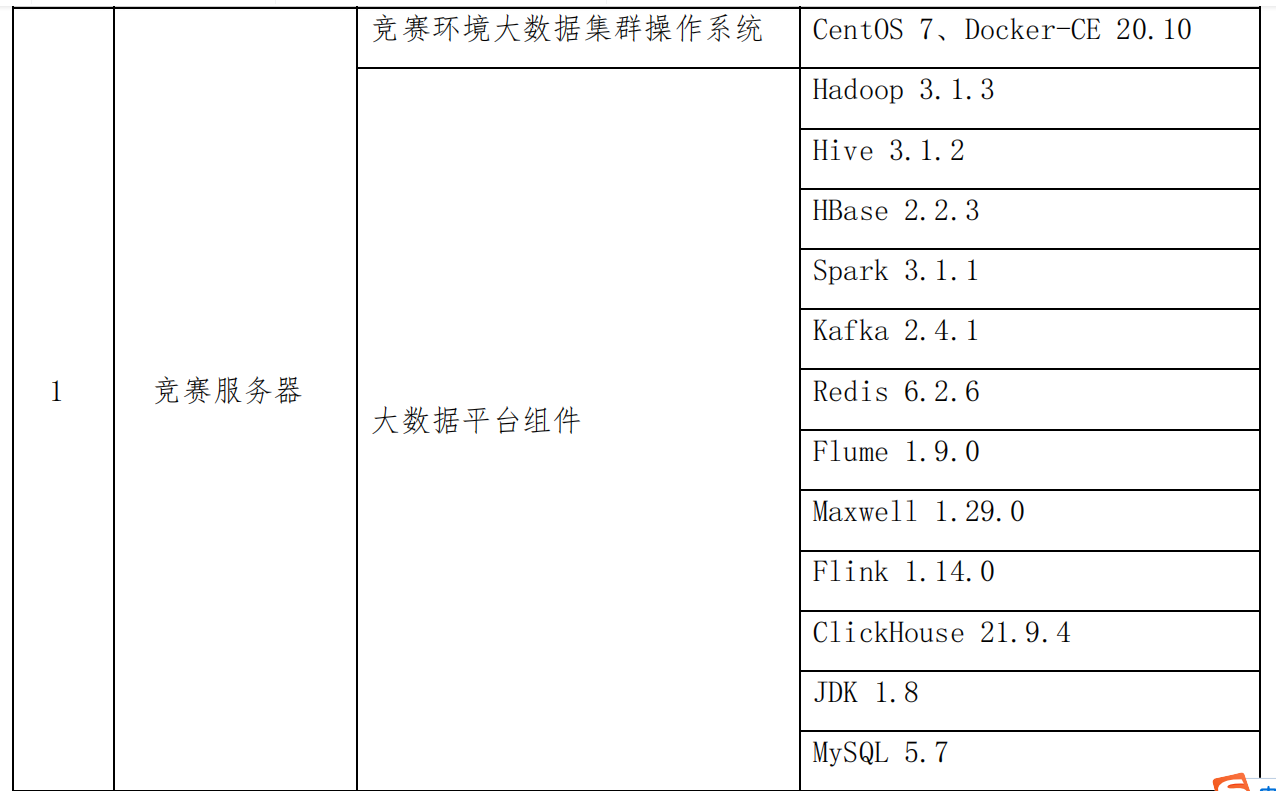
-
大概的分工可以分为
- 环境配置和数据采集。
- 数据处理
- 数据可视化和综合分析报道
怎么写了好像没写似的?
-
不求好,只求稳。学好基础能做出简陋的成品再谈别的。应该可以分为以下几条路线,组合起来就是成品了。
-
- 实时数据分析
Spark安装配置
Flume 安装配置
Kafka 安装配置
HBase 安装配置
Flink安装配置
ClickHouse 安 装 配 置
Spark 数据读取、数据存储
实时数据分析全部
- 实时数据分析
-
- 离线数据分析
Spark安装配置
HBase 安装配置
ClickHouse 安装配 置
Spark 数据读取、数据存储
离线数据处理全部
- 离线数据分析
-
- 数据可视化
调用数据接口
使用 Vue.js、ECharts 完成数据可视化(柱状图、折线图、饼状图等)
- 数据可视化
-
- 按照打分各自负责
数据处理跟数据采集的谈好怎么对接。
数据处理人员又跟数据可视化人员谈怎么对接。
就这样从上而下一层一层对接,逐步完成项目。
不过这种做法最大的问题是,上一层没做完的话,下一层就没有可操作的空间,就只能单线程逐步一个人一个人的学习,而不能多人同时学习,最后组合了
- 按照打分各自负责
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号