Scrapy 框架的 pipelines 参数详解
pipelines 的使用
- 在 pipelines.py 中创建 pipelines 的类。(也可用默认存在的类)
class PipelinesTest:
def process_item(self, item, spider):
print(item)
return item
- 编写数据处理的函数,函数格式是固定的。
def process_item(self, item, spider):
# 中间这里插入需要做的事情,其他的都别改
return item
-
在 settings.py 中启用 pipelines
在 settings.py 中找到如图所示代码

取消注释
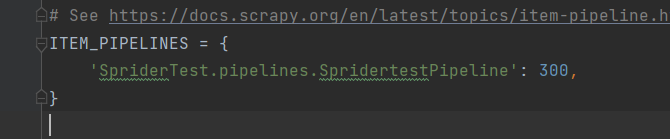
再把名字给改成自己的,就行了

可以有多条管道,所以可以不改名字,而是把自己创建的管道的名字加进去,像这样
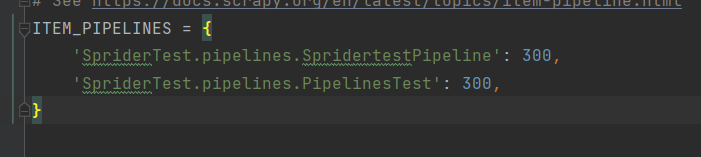
-
编写 spider 返回的数据格式。(在 items.py 中编写,编写格式也是固定、不能更改的)
class PipelinesTestItem(scrapy.Item):
name = scrapy.Field()
name 可以改别的,也可以多加几个,但格式得固定,例如
class PipelinesTestItem(scrapy.Item):
name = scrapy.Field()
hentai = scrapy.Field()
homula = scrapy.Field()
-
在 spider 中导入 items
from ..items import PipelinesTestItem -
通过 yield(生成器方式) 返回数据
def parse(self, response):
name = "丘比必死,圆神永存"
print(name)
yield PipelinesTestItem(name=name)
一个例子
spider.py 代码
import scrapy
from ..items import PipelinesTestItem
class TestSpider(scrapy.Spider):
name = 'douban'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250?start=0&filter=']
def parse(self, response):
name = "丘比必死,圆神永存"
print(name)
yield PipelinesTestItem(name=name)
itesms.py 代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class SpridertestItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
class PipelinesTestItem(scrapy.Item):
name = scrapy.Field()
pipelines.py 代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class SpridertestPipeline:
def process_item(self, item, spider):
return item
class PipelinesTest:
def process_item(self, item, spider):
print(item)
return item
第3步在 settings.py 启用 pipelines ,考虑到代码太多不好对比我就没放了,跟着第三步做就对了。
pipelines 常用的函数
一如既往地,格式是固定如下的。
- open_spider(self, spider) : 开启及执行
- process_item(self, item, spider) : 数据处理
- close_spider(self, spider) : 爬虫结束时调用
class PipelinesTest:
def open_spider(self, spider):
print('我是开始')
def process_item(self, item, spider):
print(item)
return item
def close_spider(self, spider):
print('我是结束')
简单粗暴,这串代码全是在 pipelines.py 里的,复制上去,自己动手改一下,print 一下就知道大概的一个逻辑思路了。
如果觉得写的还不错的话,可以关注支持一下,哪有问题的话也可以随意评论的,大不了聊天嘛

 浙公网安备 33010602011771号
浙公网安备 33010602011771号