Scrapy 框架的使用实例之爬取豆瓣 TOP250 电影榜单
安装就么得了,如果pip install不行的话,我曾遇到过的原因是,因为版本过低。所以升级一下Python版本就行了,如果其他安装还是不行的话,那就只能上网搜了。
从0爬取豆瓣 TOP250 电影榜单
这个例子好像很经典,很多大佬都用来举例,我也用一下吧3.3
大概的一个规划
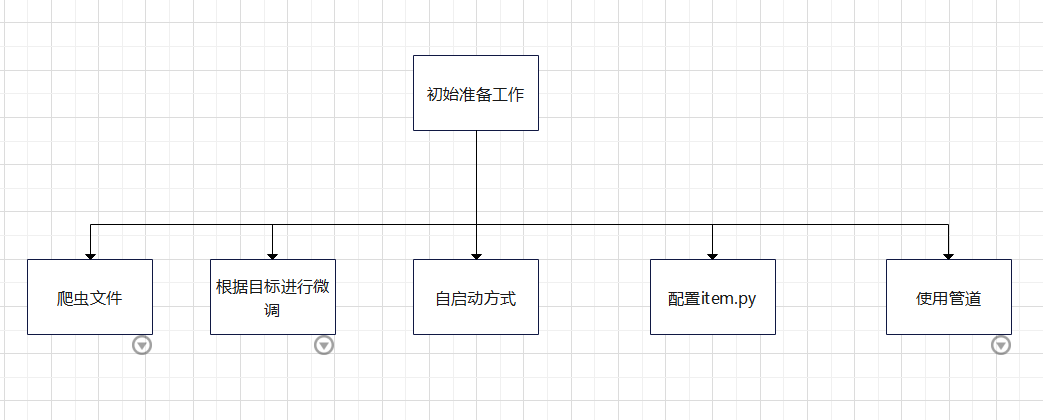
初始准备工作
创建一个爬虫项目
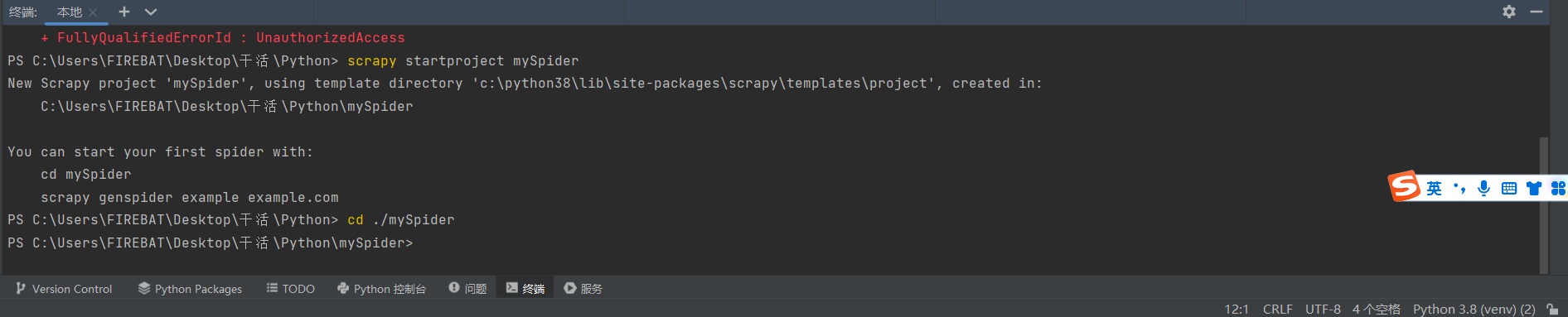
在Python终端运行
scrapy startproject mySpider
记住,是终端,是如图这里
创建一个爬虫规则
对于 豆瓣TOP250的榜单 的URL "https://movie.douban.com/top250"
首先像下面这代码这样来一下
scrapy genspider douban https://movie.douban.com
别问为什么,我现在不知道,我要知道就写上了。
然后你就可以在如图所示的地方找到这么个玩意
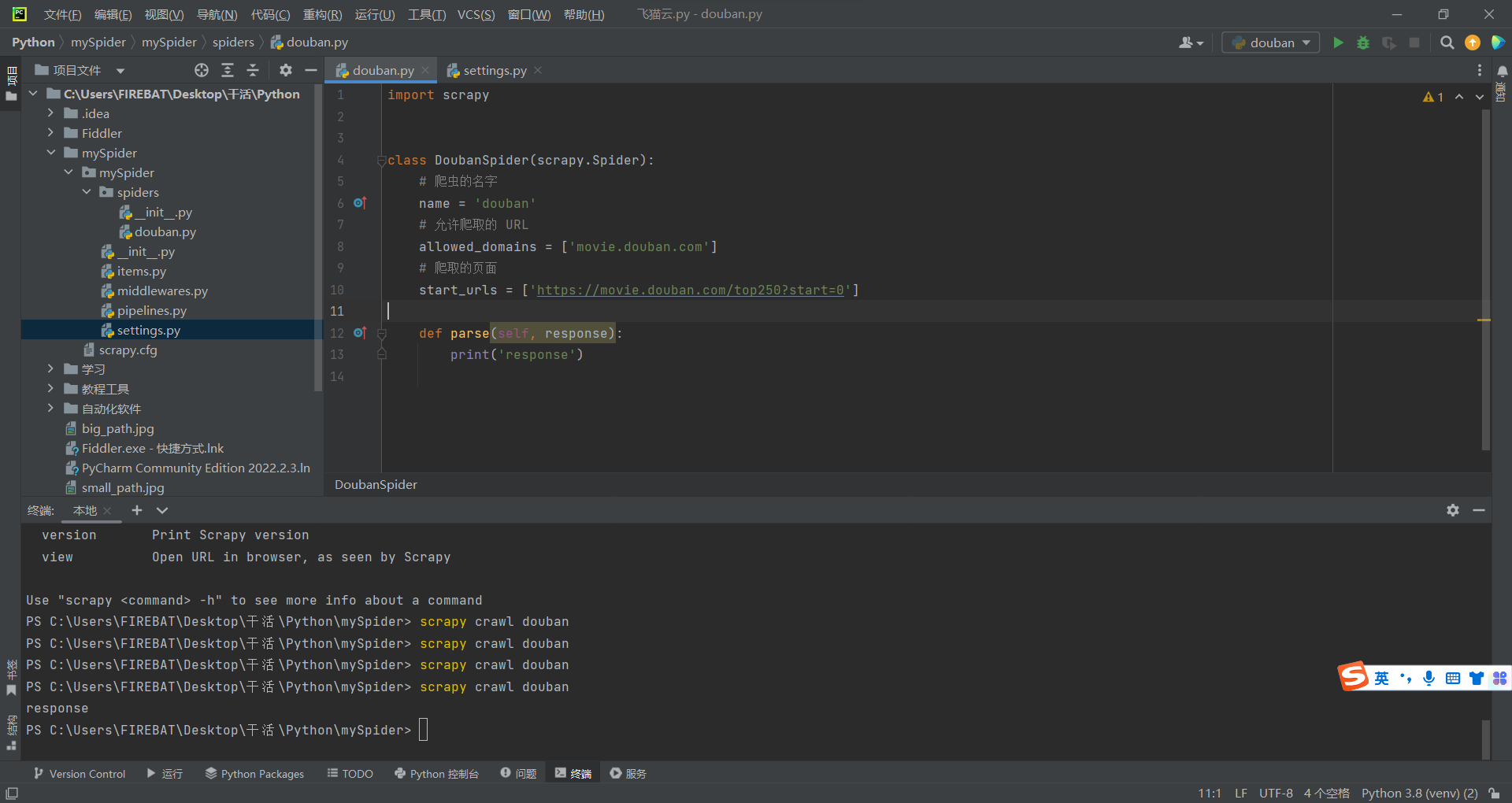
- 打开他,就会看见类似下图的代码,如果有哪里不一样,那就是我自己加的。3.3
进入爬虫项目
cd ./mySpider
进入相对路径和绝对路径之类的方法如果忘了的话,可以去地方补补。
修改 settings.py 配置文件
有如下操作
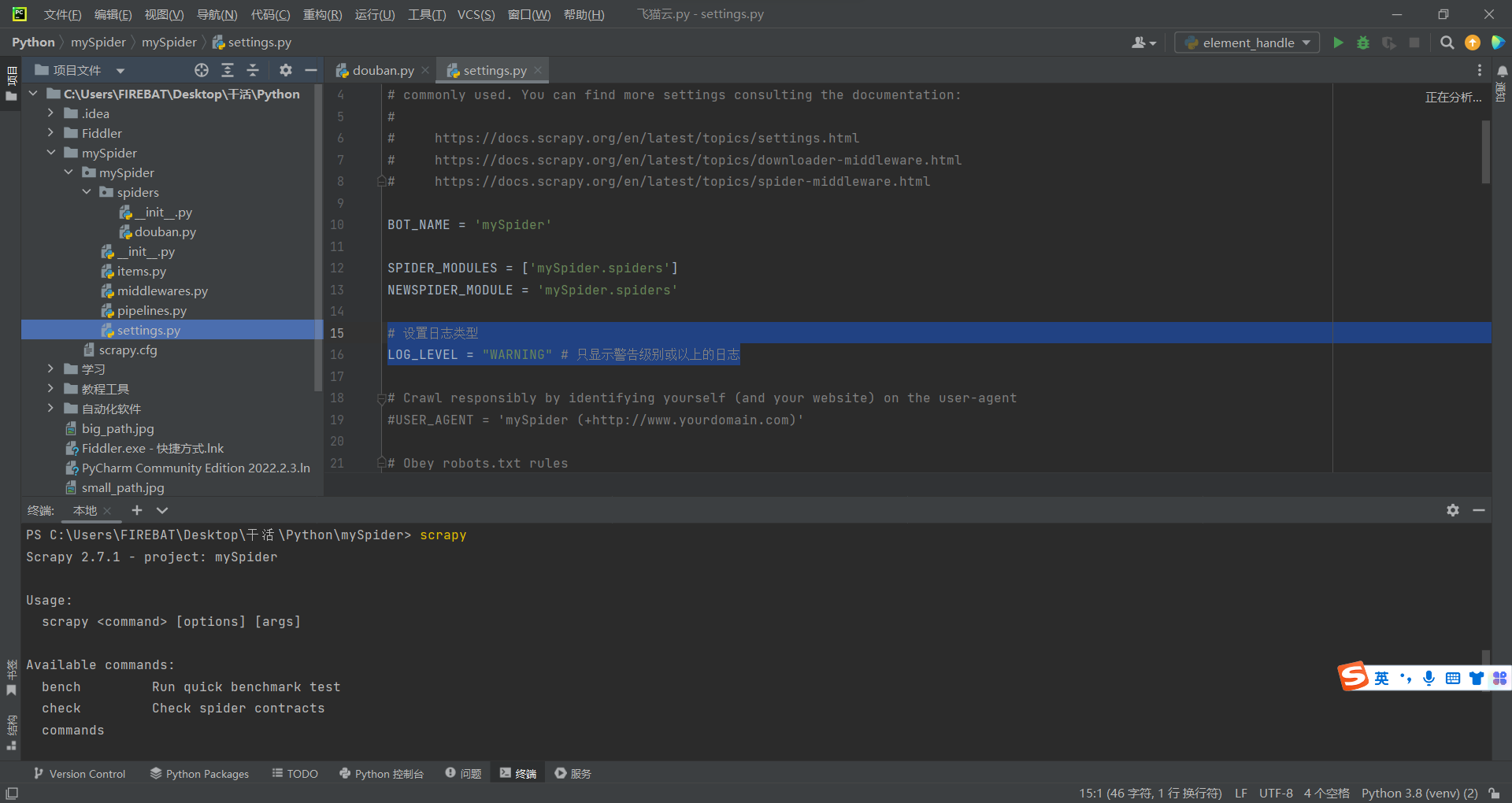
设置日志类型
LOG_LEVEL = "WARNING" # 只显示警告级别的日志(我猜的)
如图所示,在这个文件里,自己写这么一段代码加进去,没猜错的话,代码应该是放哪都行
使得scrapy框架不遵守 robots.txt 协议
操作如图,找到这行代码,然后把 True 改成下面的 False 就行了

修改默认UA
估计就我一个人一开始不知道UA就是user-agent的吧,呵呵。
UA在这里设置哒!
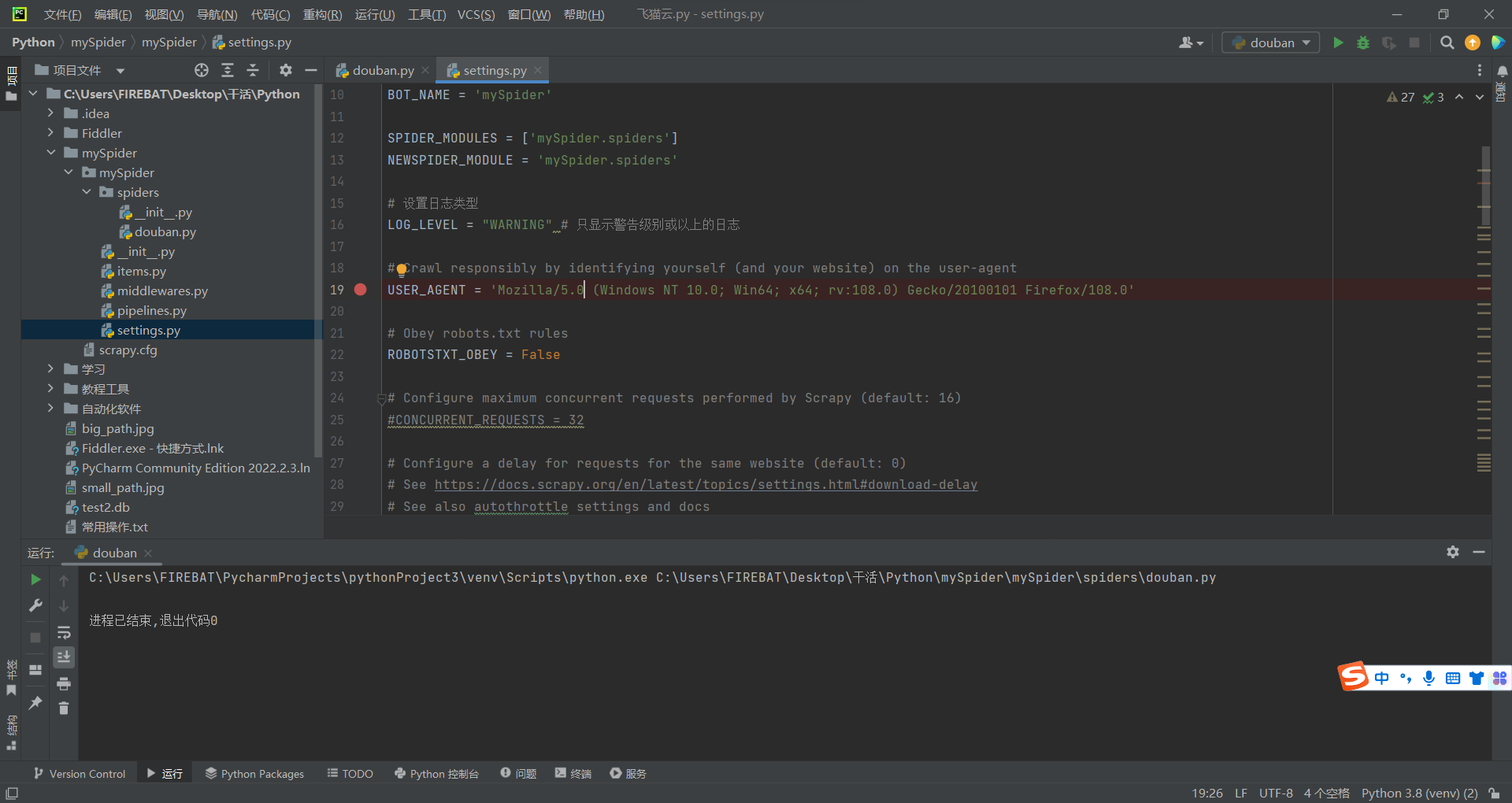
下图是教怎么找自己的UA的,大佬会的就可以不用看
如图,右下角标蓝的那个就是自己的UA,复制粘贴进要修改的代码处即可
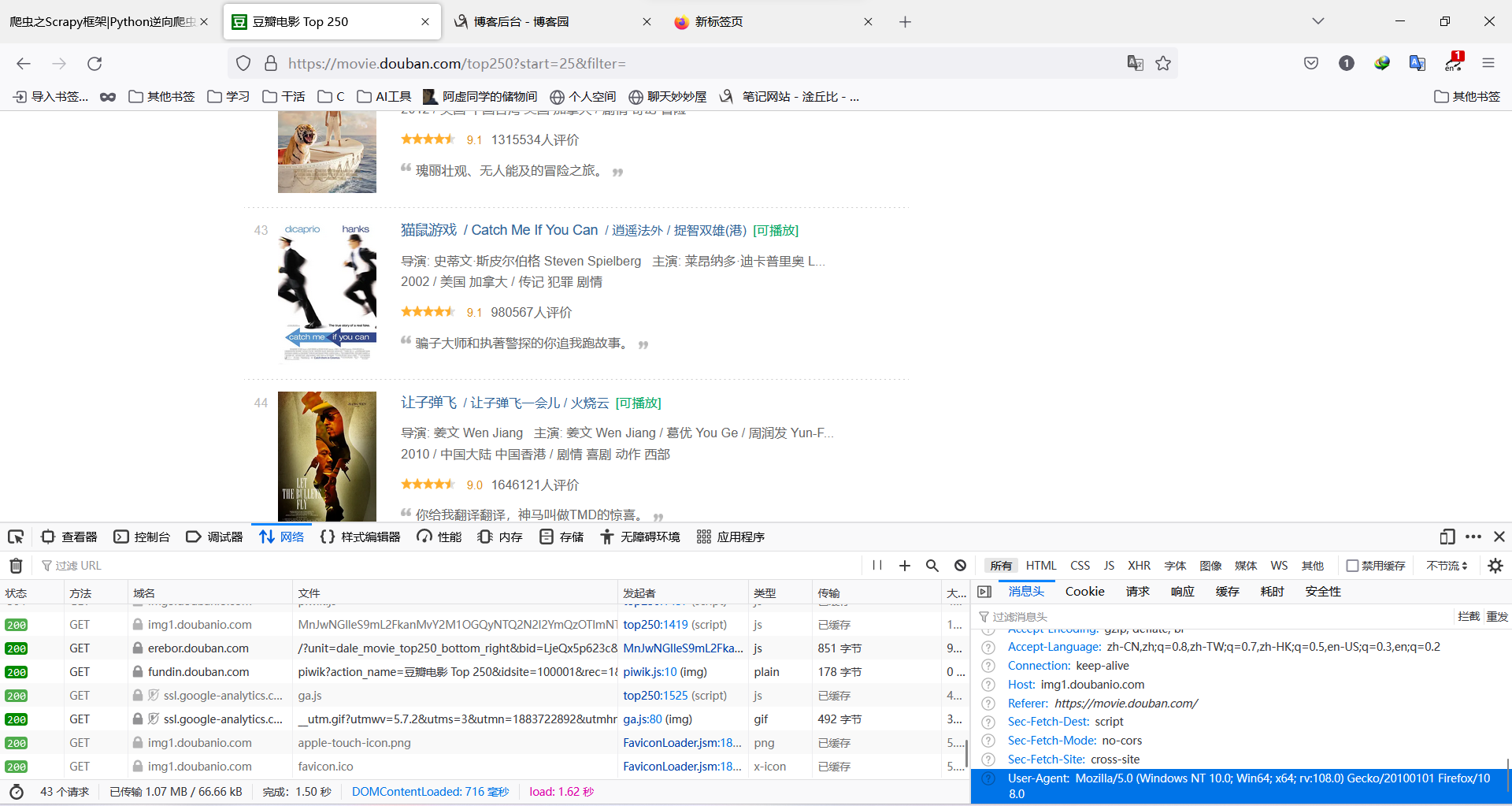
顺带再说一下怎么才能看到图里的那样子。
按如下步骤走。
- 打开豆瓣网页
- 点击F12
- 点击"网络"或者"network"
- 单击,切记是单击任意链接
- 在右侧滑动到最低端
就可以看见跟图类似的情况了。
如果"网络"或"network"一片空白,那就按F5刷新一下,接着从第2或3步重新做起即可。
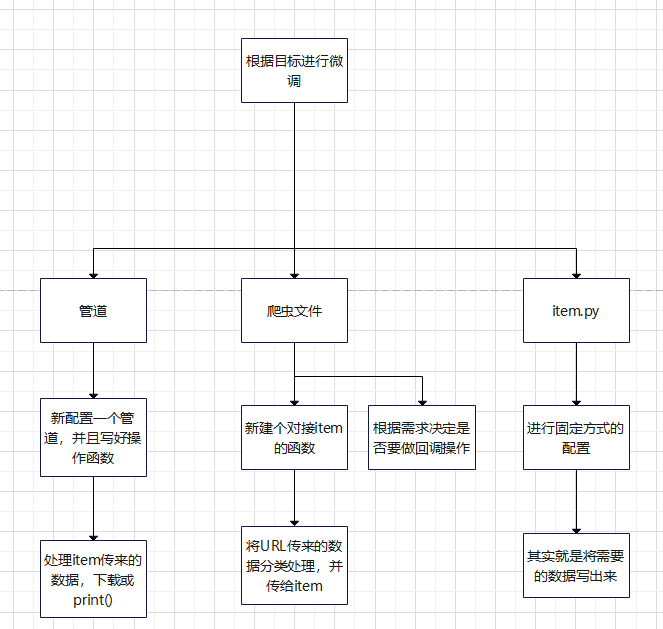
- 到这里,就是初始准备工作了,根据自己的需求微调一下即可
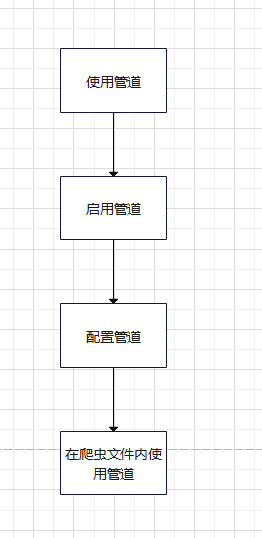
使用管道
什么是管道
希腊奶,我不知道具体含义,学艺不精,还没学到,目前只会怎么用
启用管道
像这样,把注释给去掉就行了
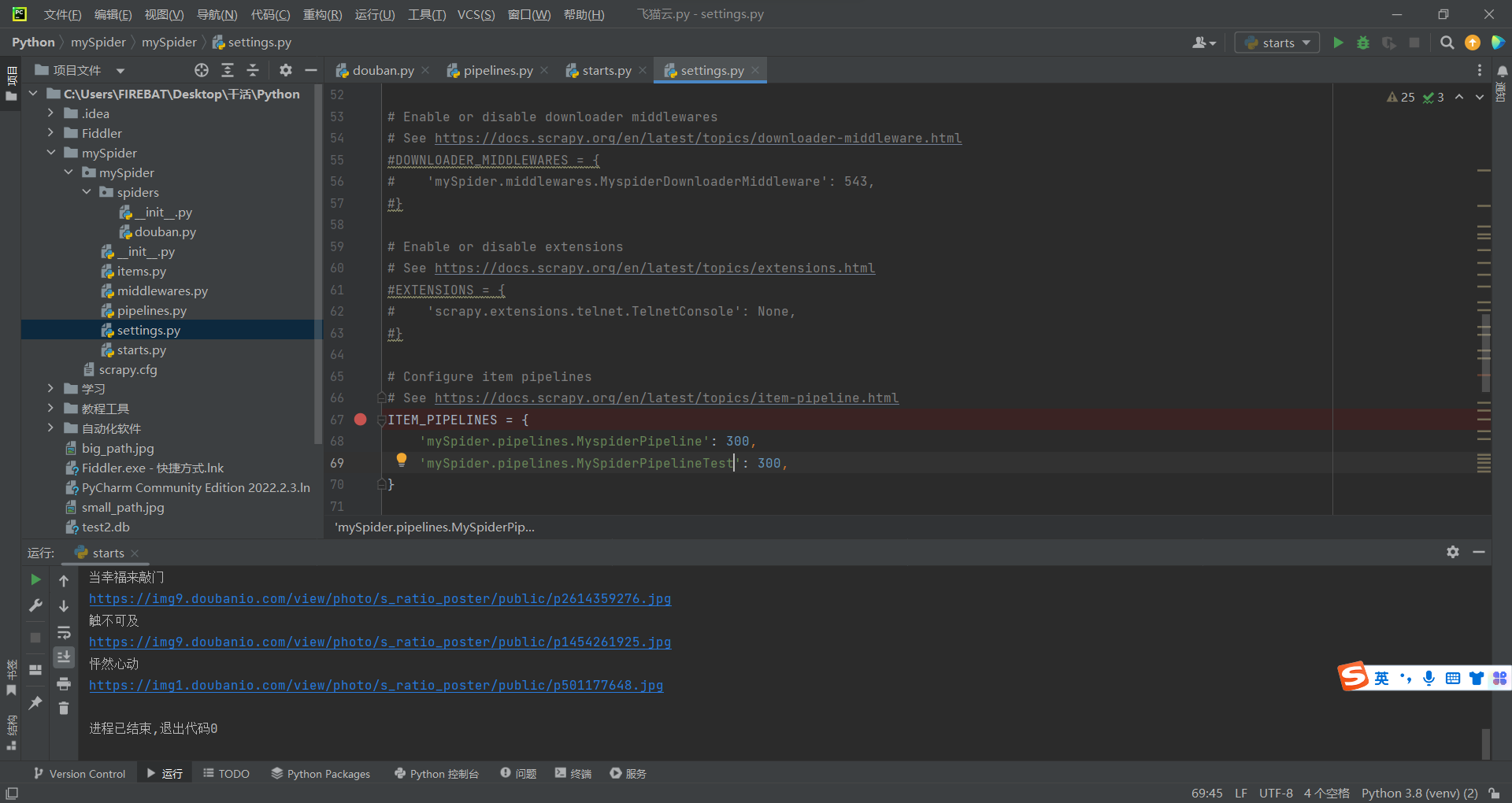
配置管道
如图,管道实例名字可以自己任取。
但是实例内的函数必须是这三个名字。
def open_spider(self, spider):
def process_item(self, item, spider):
def close_spider(self, spider):
然后把需要对爬取的数据进行的操作写在中间这个函数即可。
像我这里,就是要下载图片并保存到指定路径。
配置item.py文件
想要用到管道,就必须配置好item.py文件。
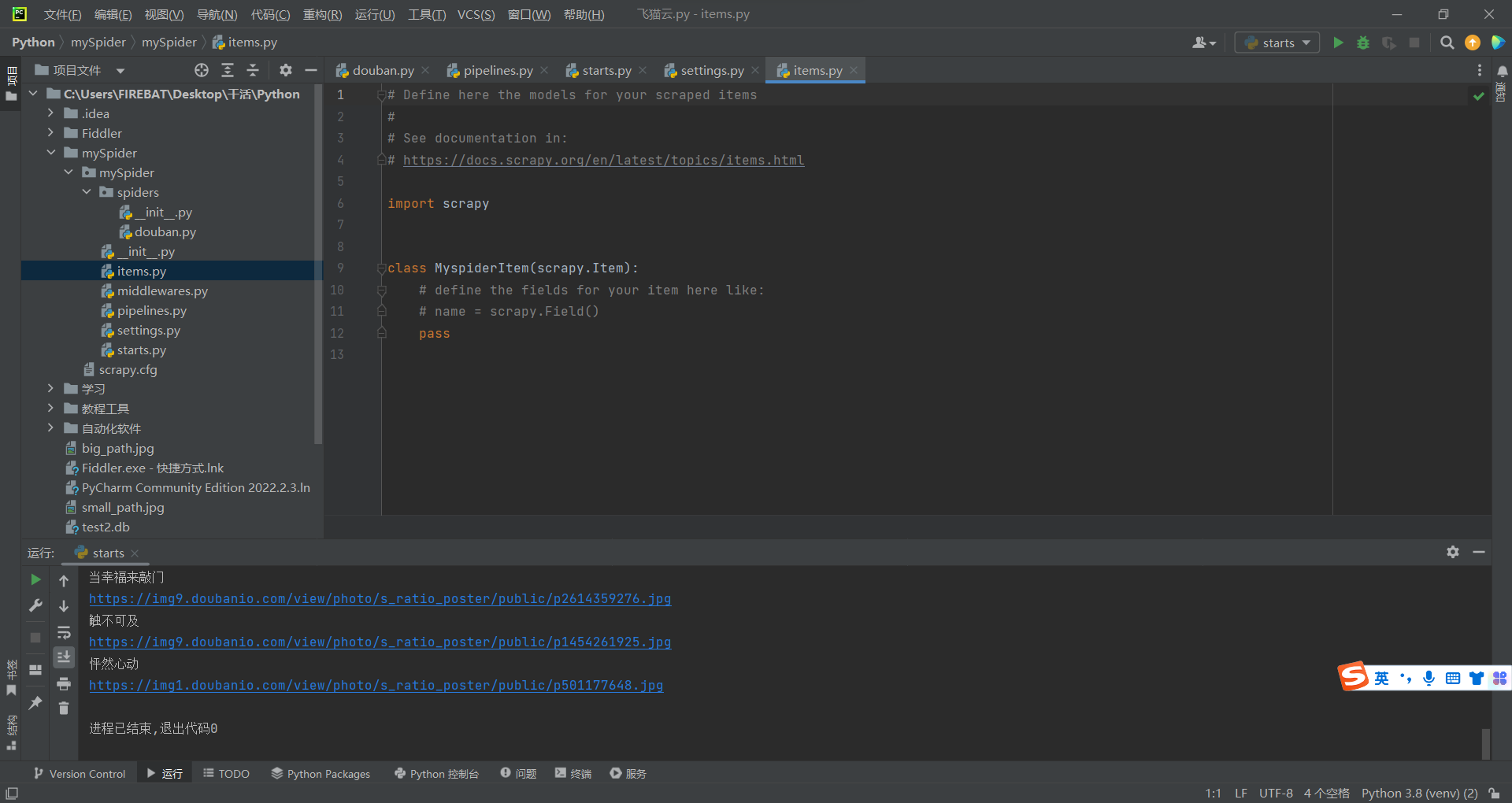
如图所示,在这里进行操作
然后如图进行配置
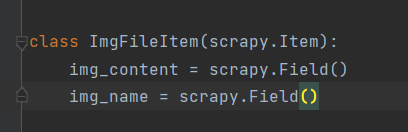
- 配置跟函数差不多,可以理解为换了个装扮的形参。
需要将函数内的参数传入,才能使用管道。
就是说,使用管道的话,需要传入 名字(img_name) 和 图片(img_content)。
就像这样
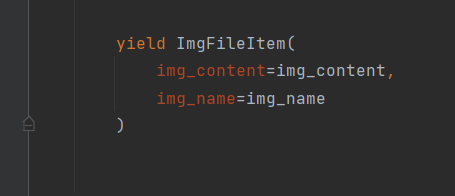
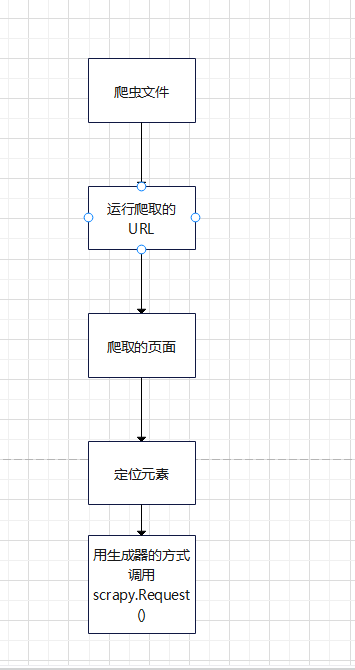
爬虫文件
- 最后就到配置爬虫文件了
执行一个爬虫
首先,什么都不做,先执行打印一下实参再说,能用就是成功。
#模板
scrapy crawl 爬虫名字
#举例
scrapy crawl douban
修改完设置文件后,执行爬虫打印一下结果,看看能不能运行。
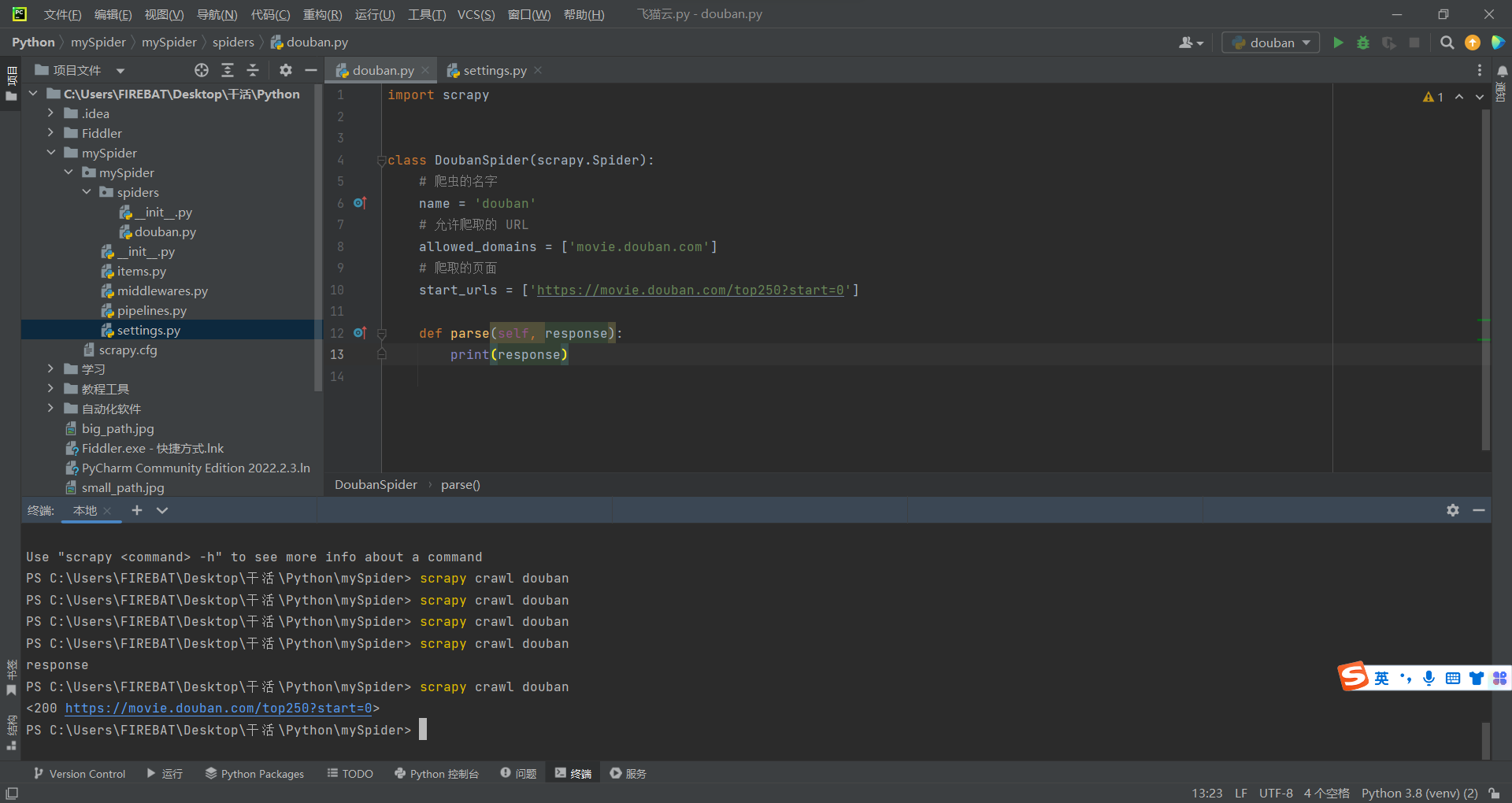
YA☆DA☆,粉碎玉碎大喝彩,顺利运行哒!
然后,这个对象的参数 response 其实就等价于下面这条代码。
response = requests.get(url)
都能看懂的吧,看不懂的话就去修行一下requests库的使用吧,我这就不多说了。肯定不是嫌麻烦
顺带一提,
- 可以通过该命令得知 scrapy 的全部命令
scrapy
没错就是他自己。3.3 - 以上操作统一是在终端,应该不会有人跟我一样傻吧,这都要提醒自己免得忘掉。
自启动方式
用终端总是感觉不太顺手的话,就可以像这样写一个 start.py 文件
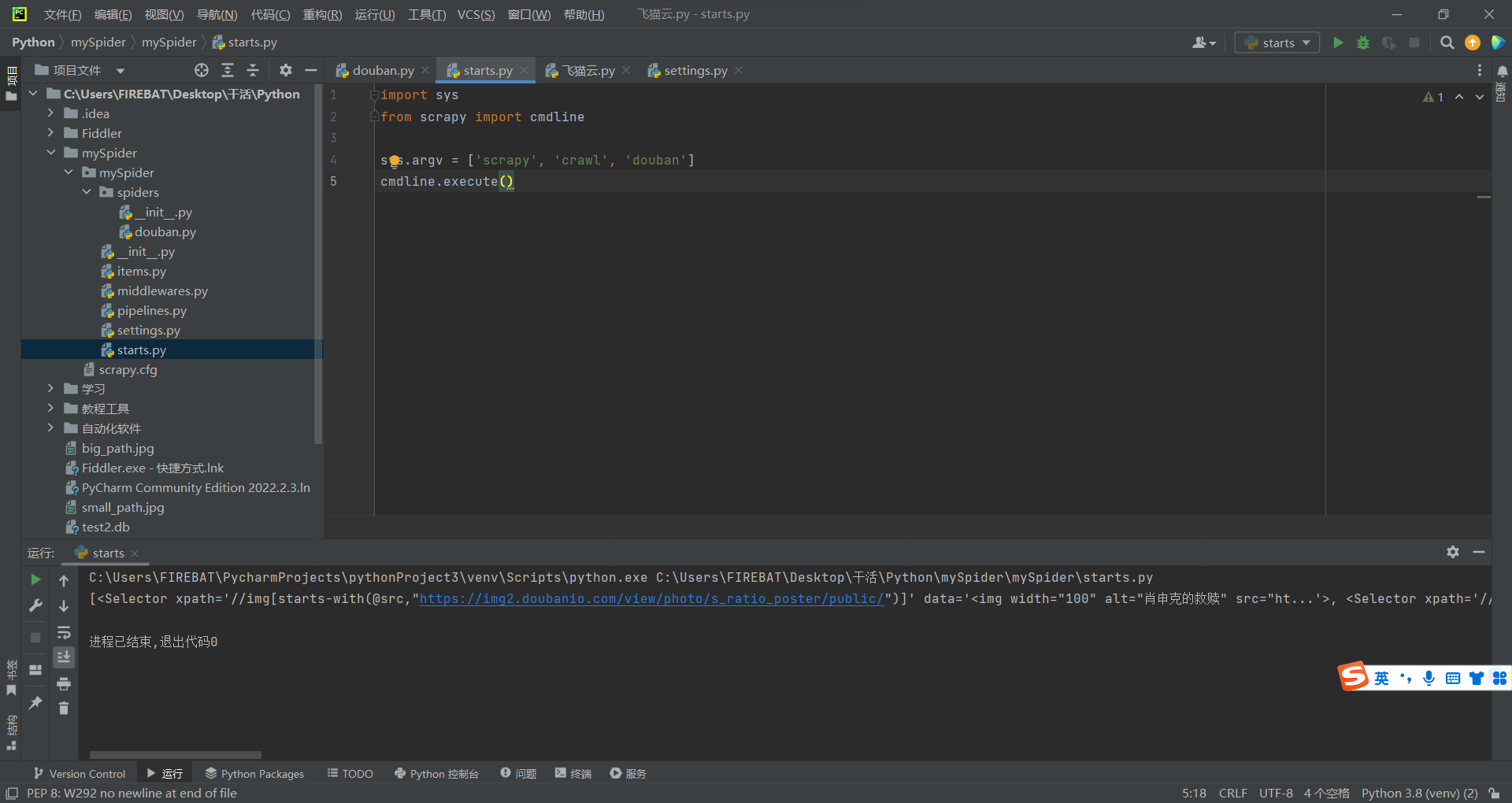
定位元素
- 根据上面说的,response其实就等价于requests.get(url)可以得知。
response已经访问了我们需要访问的页面了,也就是写在这里的部分

- 所以,现在下一步就是定位元素。
按我们现在要做的事情来说的话,就是定位到图片的元素,不然怎么下载呢?是吧。
如图所示,我这里是用的xpath方式定位的元素,如果不会用,那可以先去学一下。
如果忘了的话,这个大佬写了很详细的xpath使用方法,适合用作回忆
https://www.cnblogs.com/unknows/p/7684331.html

用生成器的方式调用 scrapy.Request()
- 直接的来的话,就是这样做
yield scrapy.Request(
url=img_url,
callback=self.img_download,
headers={
'referer': response.url
}
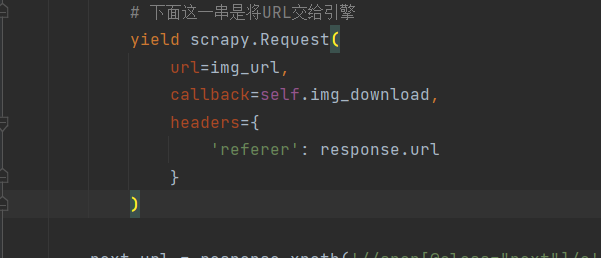
这样做有什么用?
这样做就相当于重新定义规则,再次使用scrapy框架。
用人话讲一遍就是。

把starts-urls 改为 img_url。
同时调用 self.img_download 函数。
就是还没说到的这个。

也由此,引出爬虫文件的其他函数的作用
其他函数的写法

- 如图,跟上面那个函数是一样的形参,含义也是一样的。
那么众所周知,函数存在意义在于封装。
在编程里用cv操作总会导致代码看着又臭又长。
这里也是一样。
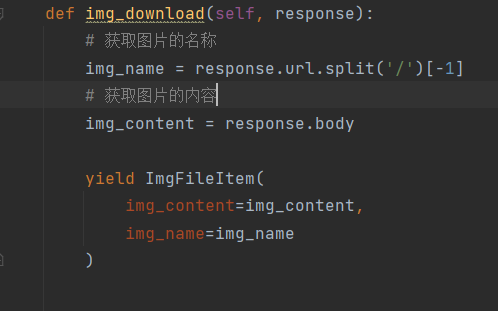
- 在这里,这个函数的意义就是对图片链接进行操作(分割出名字和内容)
然后通过生成器的方式使用管道来下载图片。
嗯,没错,然后就到怎么使用管道了。
使用管道
- 上面有提到一嘴的item.py文件的配置,不知道还记不记得。
就这个
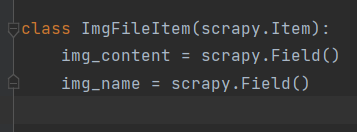
想要使用管道,他很重要。
因为逻辑上来说就是,
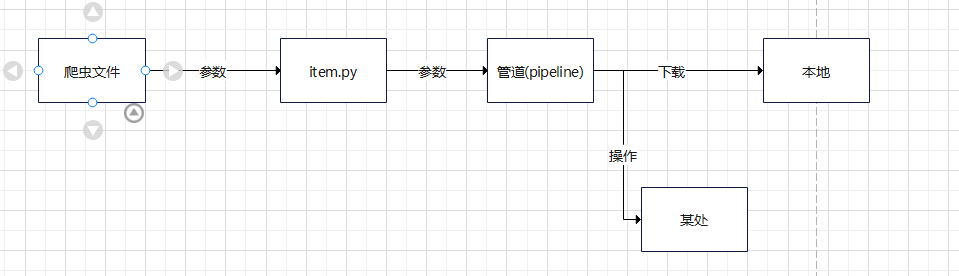
-
虽然因为我是新手的缘故,不知道为啥一定要有item来作为中介,但就目前的结果来看,就是这样一个逻辑。
-
说回正题,那要怎么使用管道呢?
首先要做的就是,引入

其次记得把管道加入配置文件
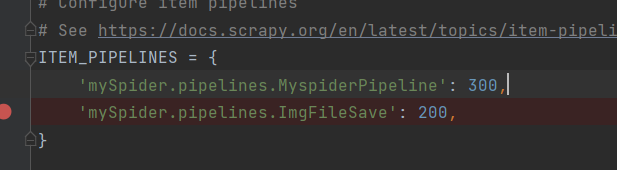
接着直接使用即可,
使用方式是,将item.py文件里设置的变量全都设置好,就行了。
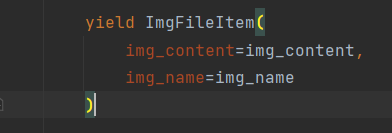
哦对了,最好用生成器的方式,不用应该也行,不过我看大佬的视频说的最好用一下。
最后他就会根据传来的参数自动做管道内函数的操作了。
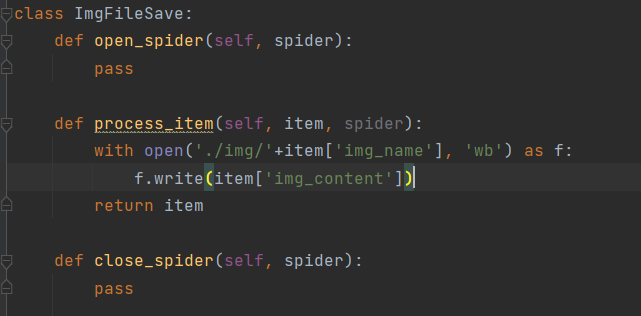
像这样,下载并保存图片(这图好像在上面就发过了)
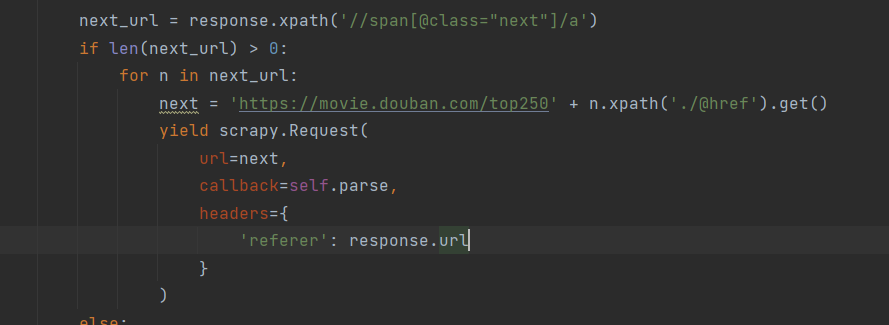
最后的微调,翻页功能(回调函数)
到这里为止,功能其实就已经差不多了,剩下的就是一个一个用一下试试了。
最后说一下的就是,怎么实现翻页功能了。
一言以蔽之,通过找到下一页的URL,不断调用自身(scrapy框架),从而实现翻页爬虫功能
全部代码
douban.py
点击查看代码
import scrapy
from ..items import ImgFileItem
class DoubanSpider(scrapy.Spider):
# 爬虫的名字
name = 'douban'
# 允许爬取的 URL
allowed_domains = ['movie.douban.com',
'img1.doubanio.com',
'img2.doubanio.com',
'img3.doubanio.com',
'img9.doubanio.com',
]
# 爬取的页面
start_urls = ['https://movie.douban.com/top250?start=0']
def parse(self, response):
# 使用 xpath 定位到图片元素
imgs = response.xpath('//ol[@class="grid_view"]/li')
for img in imgs:
img_url = img.xpath('./div[@class="item"]/div[@class="pic"]/a/img/@src').get()
# 豆瓣下载必须的操作,修改一下headers头
# 下面这一串是将URL交给引擎
yield scrapy.Request(
url=img_url,
callback=self.img_download,
headers={
'referer': response.url
}
)
next_url = response.xpath('//span[@class="next"]/a')
if len(next_url) > 0:
for n in next_url:
next = 'https://movie.douban.com/top250' + n.xpath('./@href').get()
yield scrapy.Request(
url=next,
callback=self.parse,
headers={
'referer': response.url
}
)
else:
print("最后一页了")
def img_download(self, response):
# 获取图片的名称
img_name = response.url.split('/')[-1]
# 获取图片的内容
img_content = response.body
yield ImgFileItem(
img_content=img_content,
img_name=img_name
)
pipeline.py
点击查看代码
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class MyspiderPipeline:
def process_item(self, item, spider):
return item
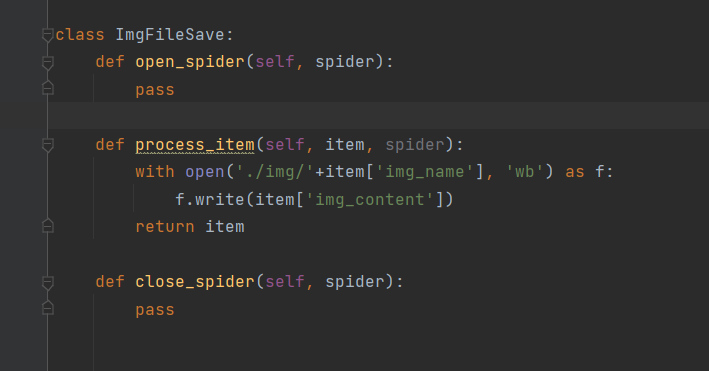
class ImgFileSave:
def open_spider(self, spider):
pass
def process_item(self, item, spider):
with open('./img/'+item['img_name'], 'wb') as f:
f.write(item['img_content'])
return item
def close_spider(self, spider):
pass
items.py
点击查看代码
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class ImgFileItem(scrapy.Item):
img_content = scrapy.Field()
img_name = scrapy.Field()
完
好了,估计也没人看,纯当做写笔记了,避免以后自己一窍不通成为白痴,看不懂自己写的什么。
我可真是费劲心力啊(~ ̄▽ ̄)~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号