Group Normalization
Group Normalization
FAIR 团队,吴育昕和恺明大大的新作Group Normalization。

主要的优势在于,BN会受到batchsize大小的影响。如果batchsize太小,算出的均值和方差就会不准确,如果太大,显存又可能不够用。
而GN算的是channel方向每个group的均值和方差,和batchsize没关系,自然就不受batchsize大小的约束。
从上图可以看出,随着batchsize的减小,GN的表现基本不受影响,而BN的性能却越来越差。
BatchNorm基础:
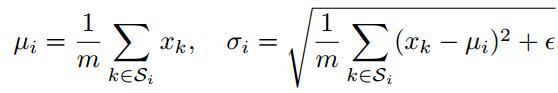
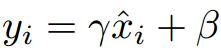
其中u为均值,seigema为方差,实际训练中使用指数滑动平均EMA计算。
gamma为scale值,beta为shift值
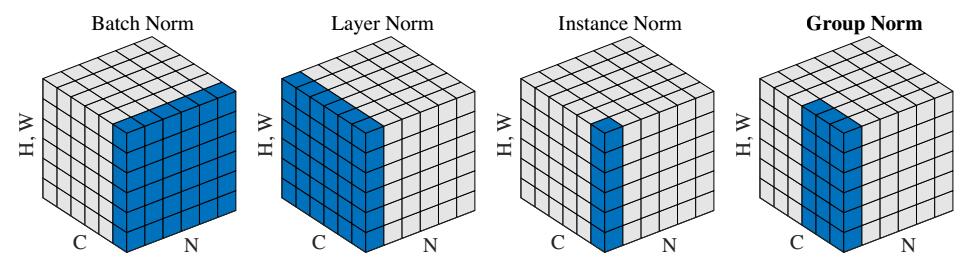
BatchNorm:batch方向做归一化,算N*H*W的均值
LayerNorm:channel方向做归一化,算C*H*W的均值
InstanceNorm:一个channel内做归一化,算H*W的均值
GroupNorm:将channel方向分group,然后每个group内做归一化,算(C//G)*H*W的均值
Tensorflow代码:
- def GroupNorm(x,G=16,eps=1e-5):
- N,H,W,C=x.shape
- x=tf.reshape(x,[tf.cast(N,tf.int32),tf.cast(H,tf.int32),tf.cast(W,tf.int32),tf.cast(G,tf.int32),tf.cast(C//G,tf.int32)])
- mean,var=tf.nn.moments(x,[1,2,4],keep_dims=True)
- x=(x-mean)/tf.sqrt(var+eps)
- x=tf.reshape(x,[tf.cast(N,tf.int32),tf.cast(H,tf.int32),tf.cast(W,tf.int32),tf.cast(C,tf.int32)])
- gamma = tf.Variable(tf.ones(shape=[1,1,1,tf.cast(C,tf.int32)]), name="gamma")
- beta = tf.Variable(tf.zeros(shape=[1,1,1,tf.cast(C,tf.int32)]), name="beta")
- return x*gamma+beta
References:
https://www.zhihu.com/question/269576836/answer/348670955
https://github.com/taokong/group_normalization
https://github.com/shaohua0116/Group-Normalization-Tensorflow

 浙公网安备 33010602011771号
浙公网安备 33010602011771号