人脸关键点检测算法
传统机器学习方法
机器学习----人脸对齐的算法-ASM.AAM..CLM.SDM
OpenCV实现人脸对齐
http://baijiahao.baidu.com/s?id=1597935437209282228&wfr=spider&for=pc
【LBF算法】Face Alignment at 3000 FPS via Regressing Local Binary Features.
有牛人改编的C++代码。
https://github.com/yulequan/face-alignment-in-3000fps
https://github.com/luoyetx/face-alignment-at-3000fps
matlab代码https://github.com/jwyang/face-alignment
这些代码不一定完全实现了论文所说的效果,但是都可用
Face Alignment at 3000 FPS通俗易懂讲解一 随机森林的生成
https://blog.csdn.net/rongrongyaofeiqi/article/details/53898334
https://blog.csdn.net/u010333076/article/details/50637321
关键笔记
2、样本划分
因为要训练10个决策树,所以将样本划分为10个小样本。这里划分的方式如图所示。对每一个小样本(642个)训练出一个决策树,就有了10个决策树。
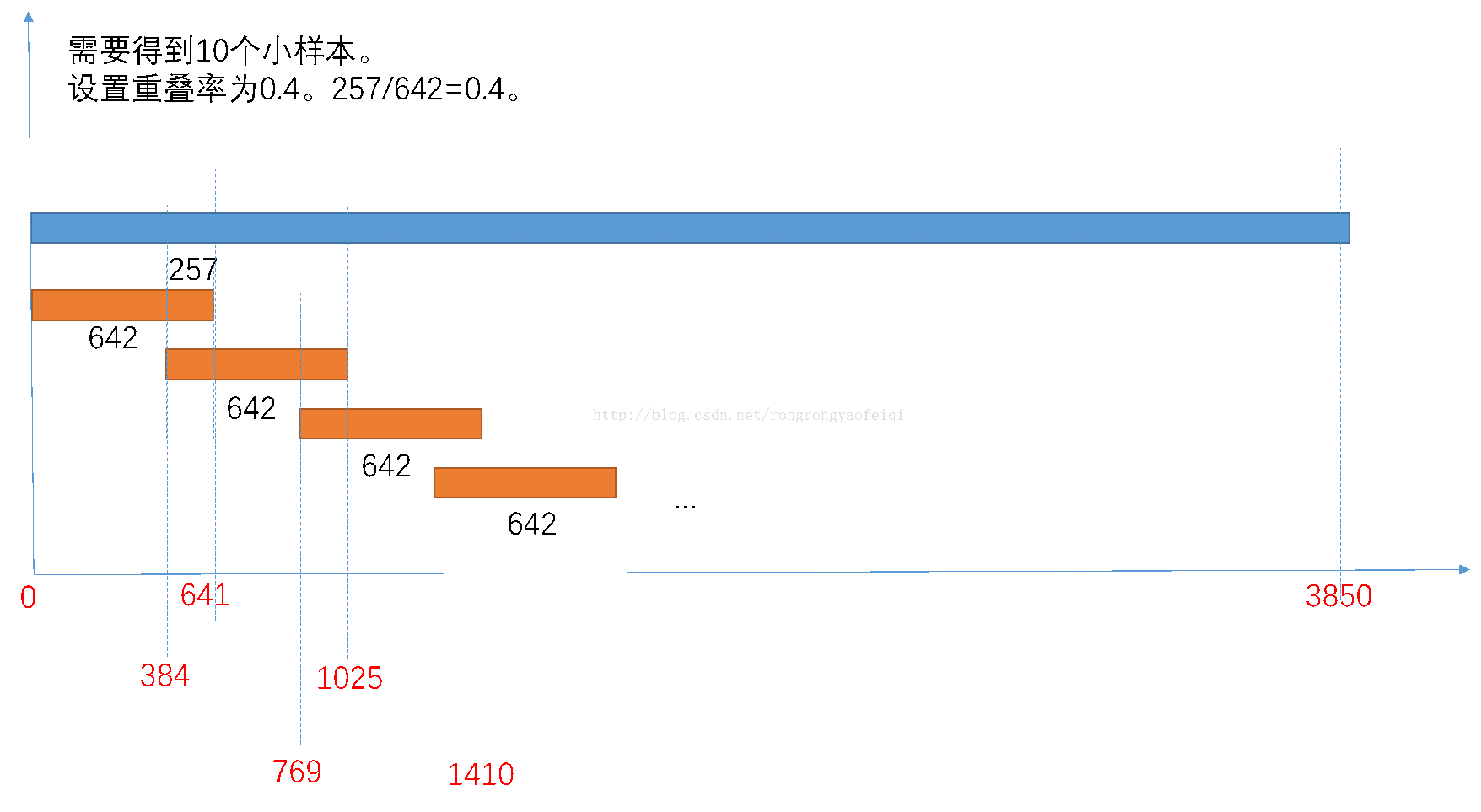
3、决策树与随机森林
对第一个小样本的某一个标记点生成决策树。
树的深度为5,所以一共有31个节点。
比如在0-641编号(642训练集)的每张图的一个关键点的固定半径(第一级会在较大的范围内取值,如实例中第一级的半径为0.4,第二级到第七级是0.3、0.2、0.1、0.15、0.12、0.08、0.05)内,随机生成M=500个点(如实例中第一级的500,第二级到第七级是500、500、300、300、200、200、200),并记录其坐标。
组成一个500×642的输入矩阵,每一列代表的是一个样本内的500个像素差值;每一行代表的是642个样本中,每个样本间随机选择的一个像素差值。
决策树的阈值确定:最大方差衰减
max(分裂前的样本方差总和-分裂后左样本集的方差-分裂后右样本集的方差) 即argmax (Var-Var_Left-Var_right)
① 一个决策树的生成
首先找根节点的分类阈值。找阈值,分裂。
500×642矩阵每一行,随机选任意一个样本的像素差值做分类阈值,用这个分类阈值将第一行642个样本分成两类:大于分类阈值的样本 和 小于分类阈值的样本,分别放在左右子集。
计算642个样本的方差,左子集的方差,右子集的方差。
依次对500行,即计算矩阵的每一行,随机产生阈值,分类,计算方差。
得到500个 (var_overall - var_lc - var_rc),选择其中最大的值,作为根节点的分裂阈值。
根据根节点的阈值真正分裂这642个,分为左右两类
叶节点的分类阈值同理
对根节点分类出来的左右子集的样本再分别计算方差,确定决策树的其他节点。确定一棵树的分裂节点和叶子节点。更具体的,假如左节点有79个样本,那么对这79个样本的这个关键点固定半径内随机生成500点,组成一个500×79的输入矩阵,每一列代表的是一个样本内的500个像素差值;每一行代表的是79个样本中,每个样本间随机选择的一个像素差值。选择500个 ( var_overall - var_lc - var_rc)最大的值,作为此左节点的分裂阈值。将这左节点的样本再次分别左右子节点…知道完成31个节点。
一个标记点的第一个决策树生成。
② 一个随机森林的生成
然后对剩下的样本输入训练第二个决策树(如384-1025编号的样本),循环知道所有样本都处理,得到随机森林的结构。
一个标记点的随机森林生成。
③ 所有特征点随机森林的生成
同样的样本,对所有标记点训练相应的随机森林,得到68个随机森林。
所有标记点的随机森林生成。
④ 级联的随机森林。
训练时共七级,分别对每一级生成68个标记点的随机森林。区别在于,级数越高,生成的随机点离关键点的固定半径越小。级数越高,随机点的个数也会不一样。级别越高,对人脸的定位效果越好。
所有层级的随机森林生成。
每个节点会记录节点的阈值,是否被分裂、是否是叶节点等信息。
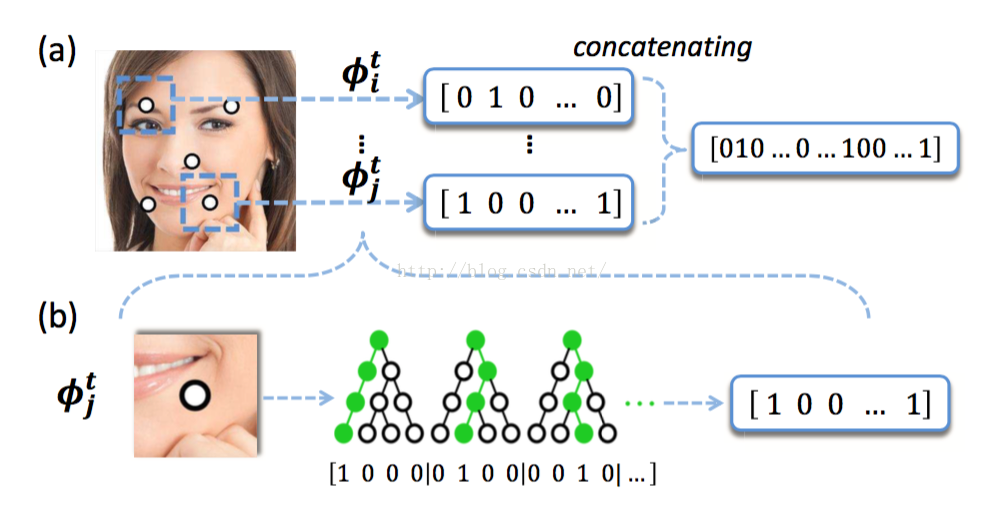
先看b,随机森林的三棵树,样本经过三棵树后分别落在了第1,2,3个叶子节点上,于是三棵树的LBF就是1000,0100,0010.连接起来就是100001000010.
然后看a,把27个特征点的lbf都连接起来形成总的LBF就是Φ了。
接下来是训练w:之前已经得到了wΦ(I,S)以及Φ(I,S),现在想求w,这还不容易吗,直接算呀。不过作者又调皮了,他说他不想求w,
而是想求一个总的大W=[w1,w2,w3,…,w27].怎么求呢?得做二次回归。至于为什么要这么做下面会介绍。目标函数:
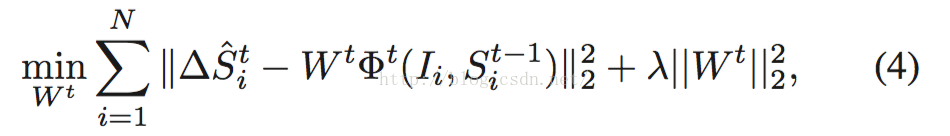
后面加了个L2项,因为W是炒鸡sparse的,防止过拟合。做线性回归即可得到W。
现在解释一下为啥不直接用w1w2w3…而是要再回归出来一个W:原因有两个:
1. 再次回归W可以去除原先小wi叶子节点上的噪声,因为随机森林里的决策树都是弱分类器嘛噪声多多滴;
2.大W是全局回归(之前的一个一个小w也就是一个一个特征点单独的回归是local回归),全局回归可以有效地实施一个全局形状约束以减少局部误差以及模糊不清的局部表现。
这样一来,测试的时候每输入一张图片I,先用随机森林Φ求出它的LBF,然后在用W乘一下就得到了下一个stage的shape,然后迭代几次就得到了最终的shape。所以效率十分的快。
深度学习方法
2017 世界最大人脸对齐数据集 ICCV 2017:距离解决人脸对齐已不远
http://www.sohu.com/a/194035320_473283
https://github.com/1adrianb/face-alignment
2018 Joint 3D Face Reconstruction and Dense Alignment with Position Map Regression Network
https://github.com/YadiraF/PRNet
2017 Pose-Invariant Face Alignment (PIFA)
人脸对齐与人脸姿态估计
人脸姿态估计,顾名思义,给定一张人脸图像,确定其姿态,姿态由什么构成呢?很简单(pitch,yaw,roll)三种角度,分别代表上下翻转,左右翻转,平面内旋转的角度。
目前,人脸姿态估计有多种方法,可以分为基于模型的方法,基于表观的方法,基于分类的方法。我之前做过 这方面的调研,调研的结果很明显,基于模型的方法得到的效果最好,因为其得到的人脸姿态是连续的,而另外两种,是离散的,并且很耗时间。
人脸姿态估计算法一般当做很多人脸对齐相关论文的副产品被提出,近期,比较“出名”的人脸对齐论文主要来自于CVPR,ICCV等,如下:
《Supervised Descent Method and its Applications to Face Alignment》,这篇论文提供了demo,并且附加了人脸姿态估计功能,估计精度还不错。
《Face Alignment at 3000 FPS via Regressing Local Binary Features》,这篇文章是最新的人脸对齐算法,基于随机森林的算法,速度比较快,精度基本和上一篇持平。
《Face Alignment by Explicit Shape Regression》这篇文章很出名,作者也和上一篇是同一人。
还有经典的人脸对齐鼻祖算法ASM,AAM,想必大家也都知道,这里不再多说,因为咱这篇博客的主题是人脸姿态估计嘛!~
基于模型的估计方法的前提是,手头必须具备两样东西,一个是人脸特征点(眼镜,嘴巴,鼻子等处的像素位置),另外一个,是需要自己制作一个3维的,正面的“标准模型”。
这个模型的好坏很重要,人脸的特征点精度可以不高,因为后面的姿态估计算法可以采用鲁棒方法予以弥补,但是标准模型一旦有问题,势必会导致姿态估计的精度偏低。
算法最重要的还是思想,其余诸如流程什么的,都是实现思想的手段而已。人脸姿态估计的思想:旋转三维标准模型一定角度,直到模型上“三维特征点”的“2维投影”,与待测试图像上的特征点(图像上的特征点显然是2维)尽量重合。这时候我们脑海中就应该浮现出一种诡异的场景:在幽暗的灯光中,一个发着淡蓝色光芒的人皮面具一点点的“自我调整”,突然一下子“完美无缺”的“扣在了你的脸上”。这就是人脸姿态估计的思想。
想到了什么没?这貌似听起来像是某种数学中常常介绍的一种方法。是的,大部分论文中也经常利用这种方式来建立模型。这个方法就叫做“非线性最小二乘”。
我们也可以利用非线性最小二乘方法来建立我们的模型,模型公式如下:
其中,(α,β,γ)代表人脸姿态三个旋转角度, N代表着一张人脸上标定特征点的个数,qi代表着待测试人脸特征点,pi代表对应着的三维通用标准模型特征点,R代表旋转矩阵, t为空间偏移向量,s为伸缩因子。R的具体形式是如下三个矩阵相乘:
给出了人脸姿态估计的模型,我们可以发现,这个公式的形式,刚好对应于刚刚提出的人脸姿态估计算法思想。数学是奇妙的!
更奇妙的在下面.....
这个公式看起来很直观,很好的解释了人脸姿态估计的内涵,但是,这个公式怎么求解?
对了,别忘记,这是“烂大街的”非线性最小二乘算法,从牛顿爷爷开始,就有着大把的优化方法,梯度下降,牛顿高斯,信赖域,马夸尔特等等等等等用于解决它,等到下一篇博客,我会尽量用通俗的语言,为大家介绍姿态估计的下一个重要阶段:迭代求精。
附图(姿态估计效果图):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号