
JVM 调优案例分析1
1 案例资料
案例程序在stock.zip中http://download.csdn.net/detail/jingshuaizh/9234175
Requirements
jdk1.7
mysql 5.1
import db.sql
修改stock.bat 关于数据库的连接配置

2 调优目标
目标程序启动需要的时间太长,
调优目标缩短目标程序启动时间。
3 JVM 调优思路
3.1 观察内存
1) 观察内存释放情况、集合类检查、对象树
2) 可查看堆空间大小分配(年轻代、年老代、持久代分配)
3) 提供即时的垃圾回收功能
4) 垃圾监控(长时间监控回收情况)
5) 查看堆内类、对象信息查看:数量、类型等
6) 对象引用情况查看
7) 有了堆信息查看方面的功能,我们一般可以顺利解决以下问题:
--年老代年轻代大小划分是否合理
--内存泄漏
--垃圾回收算法设置是否合理
8) 线程信息监控:系统线程数量。
9) 线程状态监控:各个线程都处在什么样的状态下
10) Dump线程详细信息:查看线程内部运行情况
11) 死锁检查
a) CPU热点:检查系统哪些方法占用的大量CPU时间
b) 内存热点:检查哪些对象在系统中数量最大(一定时间内存活对象和销毁对象一起统计)
这两个东西对于系统优化很有帮助。我们可以根据找到的热点,有针对性的进行系统的瓶颈查找和进行系统优化,而不是漫无目的的进行所有代码的优化
12) 快照
快照是系统运行到某一时刻的一个定格。在我们进行调优的时候,不可能用眼睛去跟踪所有系统变化,依赖快照功能,我们就可以进行系统两个不同运行时刻,对象(或类、线程等)的不同,以便快速找到问题
举例说,我要检查系统进行垃圾回收以后,是否还有该收回的对象被遗漏下来的了。那么,我可以在进行垃圾回收前后,分别进行一次堆情况的快照,然后对比两次快照的对象情况。
3.2内存泄漏检查
内存泄漏是比较常见的问题,而且解决方法也比较通用,这里可以重点说一下,而线程、热点方面的问题则是具体问题具体分析了。
内存泄漏一般可以理解为系统资源(各方面的资源,堆、栈、线程等)在错误使用的情况下,导致使用完毕的资源无法回收(或没有回收),从而导致新的资源分配请求无法完成,引起系统错误。
内存泄漏对系统危害比较大,因为他可以直接导致系统的崩溃。
需要区别一下,内存泄漏和系统超负荷两者是有区别的,虽然可能导致的最终结果是一样的。内存泄漏是用完的资源没有回收引起错误,而系统超负荷则是系统确实没有那么多资源可以分配了(其他的资源都在使用)。
年老代堆空间被占满
异常: java.lang.OutOfMemoryError: Java heap space
说明:
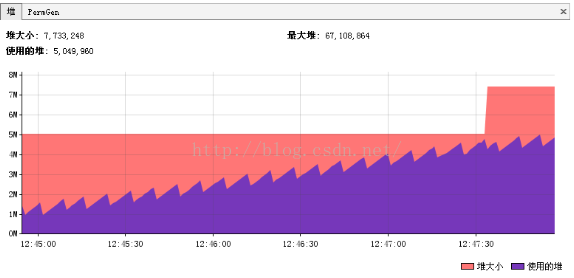
这是最典型的内存泄漏方式,简单说就是所有堆空间都被无法回收的垃圾对象占满,虚拟机无法再在分配新空间。
如上图所示,这是非常典型的内存泄漏的垃圾回收情况图。所有峰值部分都是一次垃圾回收点,所有谷底部分表示是一次垃圾回收后剩余的内存。连接所有谷底的点,可以发现一条由底到高的线,这说明,随时间的推移,系统的堆空间被不断占满,最终会占满整个堆空间。因此可以初步认为系统内部可能有内存泄漏。(上面的图仅供示例,在实际情况下收集数据的时间需要更长,比如几个小时或者几天)
解决:
这种方式解决起来也比较容易,一般就是根据垃圾回收前后情况对比,同时根据对象引用情况(常见的集合对象引用)分析,基本都可以找到泄漏点。
持久代被占满
异常:java.lang.OutOfMemoryError: PermGen space
说明:
Perm空间被占满。无法为新的class分配存储空间而引发的异常。这个异常以前是没有的,但是在Java反射大量使用的今天这个异常比较常见了。主要原因就是大量动态反射生成的类不断被加载,最终导致Perm区被占满。
更可怕的是,不同的classLoader即便使用了相同的类,但是都会对其进行加载,相当于同一个东西,如果有N个classLoader那么他将会被加载N次。因此,某些情况下,这个问题基本视为无解。当然,存在大量classLoader和大量反射类的情况其实也不多。
解决:
1. -XX:MaxPermSize=16m
2. 换用JDK。比如JRocket。
堆栈溢出
异常:java.lang.StackOverflowError
说明:这个就不多说了,一般就是递归没返回,或者循环调用造成
线程堆栈满
异常:Fatal:Stack size too small
说明:java中一个线程的空间大小是有限制的。JDK5.0以后这个值是1M。与这个线程相关的数据将会保存在其中。但是当线程空间满了以后,将会出现上面异常。
解决:增加线程栈大小。-Xss2m。但这个配置无法解决根本问题,还要看代码部分是否有造成泄漏的部分。
系统内存被占满
异常:java.lang.OutOfMemoryError:unable to create new native thread
说明:
这个异常是由于操作系统没有足够的资源来产生这个线程造成的。系统创建线程时,除了要在Java堆中分配内存外,操作系统本身也需要分配资源来创建线程。因此,当线程数量大到一定程度以后,堆中或许还有空间,但是操作系统分配不出资源来了,就出现这个异常了。
分配给Java虚拟机的内存愈多,系统剩余的资源就越少,因此,当系统内存固定时,分配给Java虚拟机的内存越多,那么,系统总共能够产生的线程也就越少,两者成反比的关系。同时,可以通过修改-Xss来减少分配给单个线程的空间,也可以增加系统总共内生产的线程数。
解决:
1. 重新设计系统减少线程数量。
2. 线程数量不能减少的情况下,通过-Xss减小单个线程大小。以便能生产更多的线程。
4 用到的工具
1) jstat 用来实时查看gc的状态,
用法:jstat -gcutil 进程号 时间(毫秒)。结果如下:
里面列出每个区间的内存大小,新生代gc的次数和时间,老年代gc的次数和时间。这里都能反映出你的JVM的运行状况
2) jmap 用于查看java进程的对象状况
用法:jmap -histo:live 进程id 。可以打印每个类的实例数量,内存大小
用法:jmap -dump:format=b,file=log.bin 进程id 这个命令特别有用,可以将jvm的整个内存镜像拷贝下来,用于分析每个对象占用的内存状况。当你的java进程崩溃了,用这个方法,可以分析出哪些对象是罪魁祸首
3) jstack 用于查看java进程id的堆栈信息
用法:jstack 进程id 这个工具对于查看死循环的线程很有效,可以直接找出是哪个线程在哪个方法内死循环了
4) Jconsole : jdk自带,功能简单,但是可以在系统有一定负荷的情况下使用。对垃圾回收算法有很详细的跟踪。详细说明参考这里
5) JProfiler:商业软件,需要付费。功能强大。详细说明参考这里
6) VisualVM:JDK自带,功能强大,与JProfiler类似。推荐。
5 调优步骤
5.1 打印程序GC日志
在stock.bat 文件中添加 -Xloggc:c:/2task/stcok.log -XX:+PrintGCDetails 打印程序GC log
查看log 文件
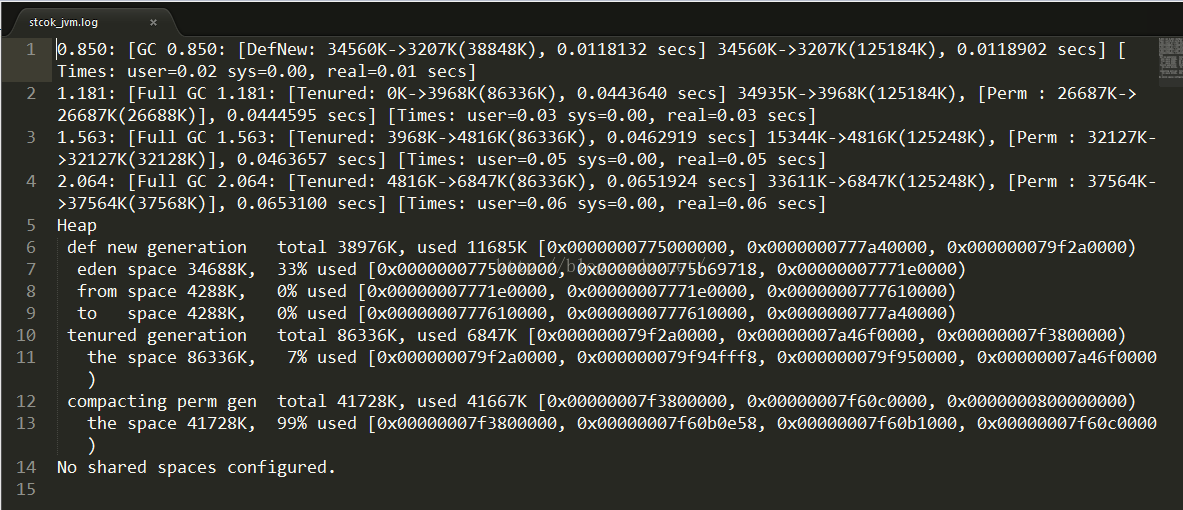
5.2 分析GC日志
发现程序Full GC 在启动期间非常频繁 1.159 1.522 2.057 发生了3次Full GC.
根据背景知识我们知道导致FullGC的原因:
1) 年老代(Tenured)被写满:
【分析】从我们的GClog文件中可以看到Tenured区有86336K并没有被写满
2) 持久代(Perm)被写满
【分析】3次full GC的数据
Perm: 26687K->26687K(26688K)]
Perm: 32127K->32127K(32128K)]
Perm: 37567K->37567K(37568K)]
持久代(Perm)都是被写满了,所以这个是Full GC的原因.
3) System.gc()被显示调用
【分析】没有源代码,暂不作分析.
5.3 解决办法
1) 设置持久代大小来避免程序FULL GC从而进行调优
通过VsualVM查看目标程序PermSize稳定在44M左右
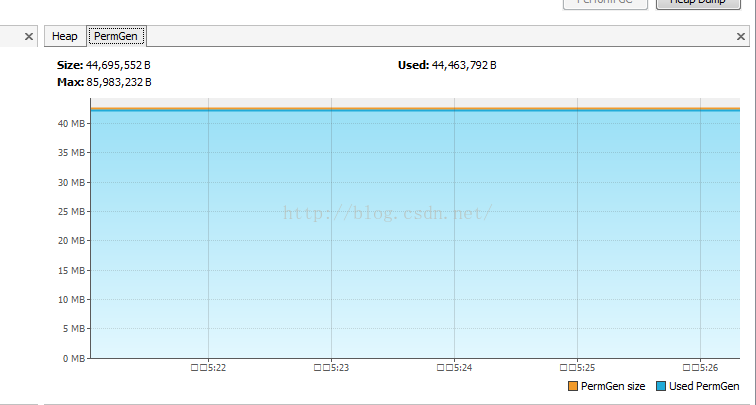
所以我们配置目标程序的默认PermSize=64m MaxPermSize=64m
-XX:PermSize=64m -XX:MaxPermSize=64m
2) 通过参数-Xverify:none禁止掉字节码验证过程

5.4 调优结果
调优之前的程序启动时间2259ms
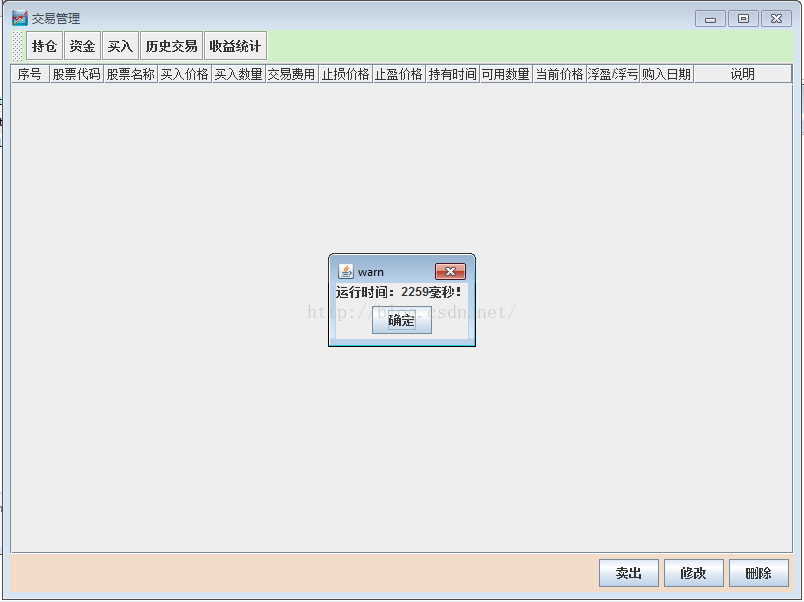
调优之后的程序启动时间1793ms

6 背景知识
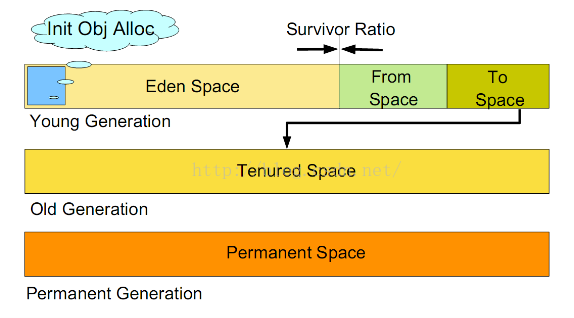
如图所示:
虚拟机中的共划分为三个代:年轻代(YoungGeneration)、年老点(OldGeneration)和持久代(PermanentGeneration)。其中持久代主要存放的是Java类的类信息,与垃圾收集要收集的Java对象关系不大。年轻代和年老代的划分是对垃圾收集影响比较大的。
年轻代:
所有新生成的对象首先都是放在年轻代的。年轻代的目标就是尽可能快速的收集掉那些生命周期短的对象。年轻代分三个区。一个Eden区,两个Survivor区(一般而言)。大部分对象在Eden区中生成。当Eden区满时,还存活的对象将被复制到Survivor区(两个中的一个),当这个Survivor区满时,此区的存活对象将被复制到另外一个Survivor区,当这个Survivor区也满了的时候,从第一个Survivor区复制过来的并且此时还存活的对象,将被复制“年老区(Tenured)”。需要注意,Survivor的两个区是对称的,没先后关系,所以同一个区中可能同时存在从Eden复制过来对象,和从前一个Survivor复制过来的对象,而复制到年老区的只有从第一个Survivor去过来的对象。而且,Survivor区总有一个是空的。同时,根据程序需要,Survivor区是可以配置为多个的(多于两个),这样可以增加对象在年轻代中的存在时间,减少被放到年老代的可能。
年老代:
在年轻代中经历了N次垃圾回收后仍然存活的对象,就会被放到年老代中。因此,可以认为年老代中存放的都是一些生命周期较长的对象。
持久代:
用于存放静态文件,如今Java类、方法等。持久代对垃圾回收没有显著影响,但是有些应用可能动态生成或者调用一些class,例如Hibernate等,在这种时候需要设置一个比较大的持久代空间来存放这些运行过程中新增的类。持久代大小通过-XX:MaxPermSize=<N>进行设置。
什么情况下触发垃圾回收
由于对象进行了分代处理,因此垃圾回收区域、时间也不一样。GC有两种类型:ScavengeGC和FullGC。
Scavenge GC
一般情况下,当新对象生成,并且在Eden申请空间失败时,就会触发ScavengeGC,对Eden区域进行GC,清除非存活对象,并且把尚且存活的对象移动到Survivor区。然后整理Survivor的两个区。这种方式的GC是对年轻代的Eden区进行,不会影响到年老代。因为大部分对象都是从Eden区开始的,同时Eden区不会分配的很大,所以Eden区的GC会频繁进行。因而,一般在这里需要使用速度快、效率高的算法,使Eden去能尽快空闲出来。
Full GC
对整个堆进行整理,包括Young、Tenured和Perm。Full GC因为需要对整个对进行回收,所以比ScavengeGC要慢,因此应该尽可能减少FullGC的次数。在对JVM调优的过程中,很大一部分工作就是对于FullGC的调节。有如下原因可能导致Full GC:
· 年老代(Tenured)被写满
· 持久代(Perm)被写满
· System.gc()被显示调用
·上一次GC之后Heap的各域分配策略动态变化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号