
本篇接上一篇内容《HanLP-基于HMM-Viterbi的人名识别原理介绍》介绍一下层叠隐马的原理。
首先说一下上一篇介绍的人名识别效果对比:
1. 只有Jieba识别出的人名
准确率极低,基本为地名或复杂地名组成部分或复杂机构名组成部分。举例如下:
[1] 战乱的阿富汗地区,枪支可随意买卖,AK47价格约500人民币
“阿富汗”被识别为人名。
[2] 安庆到桂林自驾游如何规划?
“桂林”被识别为人名。
[3] 2018天津市和平分局招聘社区戒毒、社区康复工作人员成绩查询入口
“康复”被识别为人名。
2. 只有HanLP识别出的人名
除了特别常用姓氏的名字识别正确,其他的都识别错误。举例如下:
[1] 纳溪区副区长李明带队到“花田酒地”景区检查节前安全工作
“花田酒”被被识别为人名。
[2] 秀英“线上线下”齐发力 助力贫困户“微互动”拓宽农产品销路
“齐发力”被识别为人名。
[3] 紧急通知:秦报融媒粉团祖山一日游日报名费大调整!
“秦报”被识别为人名。
3. HanLP与Jieba都识别出的人名
1. 非常用姓氏识别出的人名基本错误。
[1] 房产高管薪酬大起底 万科郁亮年薪1189.9万仅排第二
[2] 生生不息 南通支云发布汶川地震十周年海报呼吁赛前默哀
[3] 为什么伊郎不能有核武器,而美国有核武器?
2. 名字本身构成词时基本错误。
[1] 周口一村庄杨絮着火,对付杨絮用啥方法好呢?
[2] 上联: 三国魏蜀吴,如何对下联?
[3] 上联:灯火辉煌万家乐。求下联?
如何解决这些badcase呢,要看你的时间了,如果时间充裕的话,可以调整发射概率文件也就是nr.txt文件。如果时间不充裕的话,比如我现在的情况,那就只保留常用姓氏,以及特别需要关注的人名了。
上一篇的内容先说到这里,介绍本篇的主题”基于层叠隐马的命名实体识别”我这里主要阅读的是这篇文章《基于层叠隐马尔可夫模型的中文命名实体识别》。层叠就是将模型级联起来的意思,因此系统的结构如下图所示:
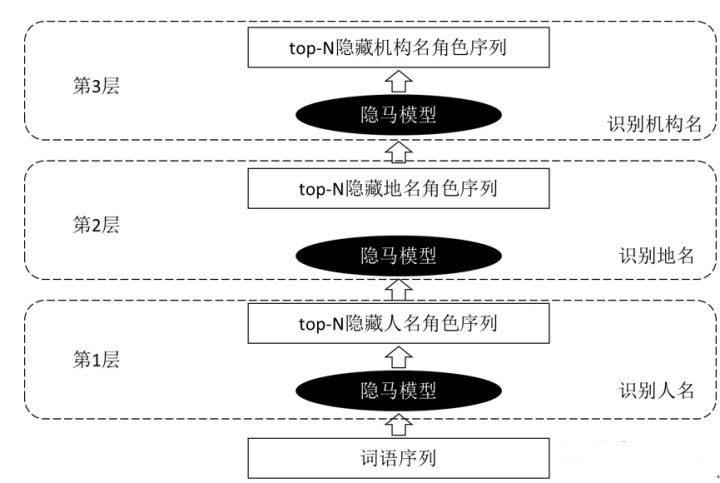
如图所示,层叠隐马就是训练三个隐马模型,每个模型标注一种实体,三个模型采用级联形式连接。
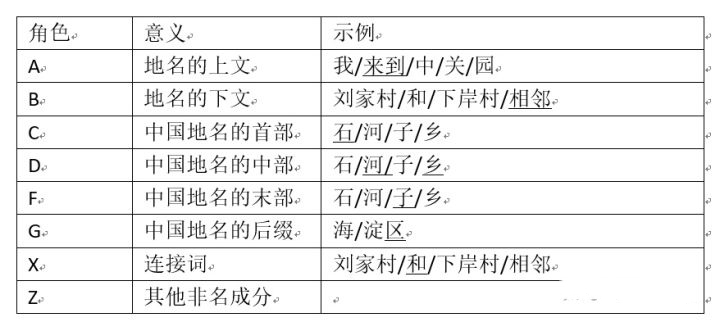
不同的实体有不同的角色标注,实际就是特征,这些特征需要有语言学的知识,实际上就是你的阅读量,通过你大量阅读总结经验,比如姓氏可以作为名字的一个特征(张、王、李、赵),常用地名的后缀可以作为一个特征(省、市、区、县),机构名表处所的尾字可以作为一个特征(局、处、所、院)。这里地名的角色标注简表如下所示:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号