
分词工具的选择:
现在对于中文分词,分词工具有很多种,比如说:jieba分词、thulac、SnowNLP等。在这篇文档中,笔者使用的jieba分词,并且基于python3环境,选择jieba分词的理由是其比较简单易学,容易上手,并且分词效果还很不错。
分词前的准备:
待分词的中文文档
存放分词之后的结果文档
中文停用词文档(用于去停用词,在网上可以找到很多)
分词之后的结果呈现:

图1 去停用词和分词前的中文文档

图2去停用词和分词之后的结果文档
分词和去停用词代码实现:
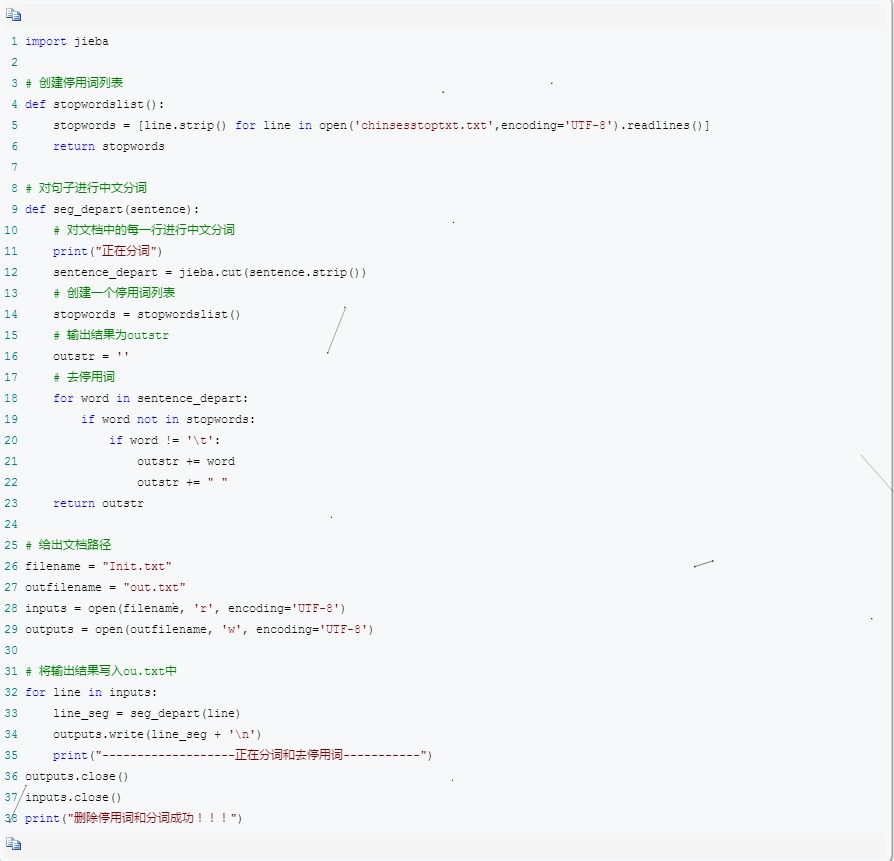
图3
转载自:https://www.cnblogs.com/zuixime0515/p/9221156.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号