


基于HanLP,支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统。
Maven
<dependency>
<groupId>com.hankcs.nlp</groupId>
<artifactId>hanlp-lucene-plugin</artifactId>
<version>1.1.6</version>
</dependency>
Solr快速上手
1.将hanlp-portable.jar和hanlp-lucene-plugin.jar共两个jar放入${webapp}/WEB-INF/lib下。(或者使用mvn package对源码打包,拷贝target/hanlp-lucene-plugin-x.x.x.jar到${webapp}/WEB-INF/lib下)
2. 修改solr core的配置文件${core}/conf/schema.xml:
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
<!-- 业务系统中需要分词的字段都需要指定type为text_cn -->
<field name="my_field1" type="text_cn" indexed="true" stored="true"/>
<field name="my_field2" type="text_cn" indexed="true" stored="true"/>
· 如果你的业务系统中有其他字段,比如location,summary之类,也需要一一指定其type="text_cn"。切记,否则这些字段仍旧是solr默认分词器。
· 另外,切记不要在query中开启indexMode,否则会影响PhaseQuery。indexMode只需在index中开启一遍即可。
高级配置
目前本插件支持如下基于schema.xml的配置:
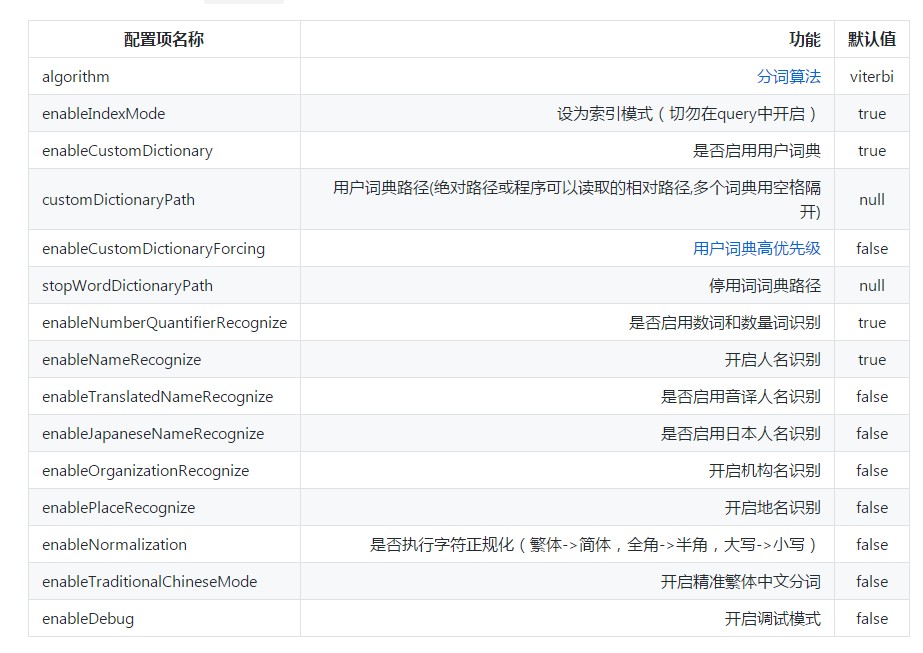
更高级的配置主要通过class path下的hanlp.properties进行配置,请阅读HanLP自然语言处理包文档以了解更多相关配置,如:
0.用户词典
1.词性标注
2.简繁转换
3.……
停用词与同义词
推荐利用Lucene或Solr自带的filter实现,本插件不会越俎代庖。 一个示例配置如下:

调用方法
在Query改写的时候,可以利用HanLPAnalyzer分词结果中的词性等属性,如
String text = "中华人民共和国很辽阔";
for (int i = 0; i < text.length(); ++i)
{
System.out.print(text.charAt(i) + "" + i + " ");
}
System.out.println();
Analyzer analyzer = new HanLPAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("field", text);
tokenStream.reset();
while (tokenStream.incrementToken())
{
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
// 偏移量
OffsetAttribute offsetAtt = tokenStream.getAttribute(OffsetAttribute.class);
// 距离
PositionIncrementAttribute positionAttr = tokenStream.getAttribute(PositionIncrementAttribute.class);
// 词性
TypeAttribute typeAttr = tokenStream.getAttribute(TypeAttribute.class);
System.out.printf("[%d:%d %d] %s/%s\n", offsetAtt.startOffset(), offsetAtt.endOffset(), positionAttr.getPositionIncrement(), attribute, typeAttr.type());
}
在另一些场景,支持以自定义的分词器(比如开启了命名实体识别的分词器、繁体中文分词器、CRF分词器等)构造HanLPTokenizer,比如:
tokenizer = new HanLPTokenizer(HanLP.newSegment()
.enableJapaneseNameRecognize(true)
.enableIndexMode(true), null, false);
tokenizer.setReader(new StringReader("林志玲亮相网友:确定不是波多野结衣?"));
文章摘自:2019 github
