
[转]ECMAScript 2016,2017 和 2018 中所有新功能的示例
很难追踪 JavaScript(ECMAScript)中的新功能。 想找到有用的代码示例更加困难。
因此,在本文中,我将介绍 TC39 已完成 ES2016,ES2017 和 ES2018(最终草案)提案中所有添加的 18 个功能,并展示有用的示例。
这是一个很长的文章,但应该很容易阅读。 可以把它想象成 “Netflix binge reading”。但是到文章结束,我保证你将对所有这些功能有很好的了解。
好的,让我们逐个讨论这些问题。
ECMAScript 2016
1.Array.prototype.includes
includes 是 Array 上的一个简单实例方法,有助于轻松查找某项元素是否在数组中(包括NaN ,与 indexOf不同)。

人们想要 contains 来命名该规范,但显然 Mootools 已经使用过这个命名,所以使用了 includes。
更多示例和常见问题请参见:ES2016 新特性:npm scripts : 每个前端开发都应知道的一些使用提示
2.指数运算符
加法和减法等数学运算分别具有 + 和 - 等中缀运算符。与它们类似,** 中缀运算符通常用于指数运算。在 ECMAScript 2016 中,引入了 ** 代替 Math.pow 。

更多示例和常见问题请参见:ES2016 新特性:求幂运算符(**)
ECMAScript 2017
1.Object.values()
Object.values() 是一个与 Object.keys() 类似的新函数,但返回 Object 自身属性的所有值,不包括原型链中的任何值。

更多示例和常见问题请参见:ES2017 新特性:Object.entries() 和 Object.values()
2.Object.entries()
Object.entries() 与 Object.keys 相关,但它不仅仅返回 keys ,而是以数组方式返回 keys 和 values 。这使得在循环中使用对象或将对象转换为 Maps 等操作变得非常简单。
示例1

示例2

更多示例和常见问题请参见:ES2017 新特性:Object.entries() 和 Object.values()
3.字符串填充
String 中添加了两个实例方法,String.prototype.padStart 和 String.prototype.padEnd – 允许将空字符串或其他字符串附加到原始字符串的开头或结尾。
'someString'.padStart(numberOfCharcters [,stringForPadding]); '5'.padStart(10) // ' 5' '5'.padStart(10, '=*') //'=*=*=*=*=5' '5'.padEnd(10) // '5 ' '5'.padEnd(10, '=*') //'5=*=*=*=*='
当我们想要对齐字符串的长度的时候,可以非常方便的使用这两个函数。
3.1 padStart 示例
在下面的示例中,我们列出了不同长度的数字。我们希望前置“0”,以便所有项具有相同的 10 位数长度显示。我们可以使用 padStart(10, '0') 轻松实现这一目标。

3.2 padEnd 示例
当我们打印不同长度的多个项并希望正确对齐它们时,padEnd 真的很方便。
下面的示例是 padEnd,padStart 和 Object.entries 组合在一起以产生漂亮输出的一个很好的现实示例。

const cars = { '🚙BMW': '10', '🚘Tesla': '5', '🚖Lamborghini': '0' } Object.entries(cars).map(([name, count]) => { //padEnd appends ' -' until the name becomes 20 characters //padStart prepends '0' until the count becomes 3 characters. console.log(`${name.padEnd(20, ' -')} Count: ${count.padStart(3, '0')}`) }); //Prints.. // 🚙BMW - - - - - - - Count: 010 // 🚘Tesla - - - - - - Count: 005 // 🚖Lamborghini - - - Count: 000
3.3 ⚠️padStart 和 padEnd 用于 Emojis 表情和其他双字节字符
Emojis 和其他双字节字符使用多个字节的 unicode 表示。 所以 padStart 和 padEnd 可能无法按预期工作!⚠️
例如:假设我们把字符串 heart 通过 emoji表情 ❤️ 使用 padStart 延长到十个字节,这个时候我们得到如下的输出:
- //Notice that instead of 5 hearts, there are only 2 hearts and 1 heart that looks odd!
- 'heart'.padStart(10, "❤️"); // prints.. '❤️❤️❤heart'
这是因为 ❤️ 本身占据两个字节(\u2764\uFE0F),而 heart 本身有 5 个字节,所以我们只剩 5 个字节的位置可以填充,JS使用\u2764\uFE0F 来填充两颗心并产生 ❤️❤️ 。对于最后一个,它只使用 heart \u2764的第一个字节产生 ❤
所以我们最终得到:❤️❤️❤heart
PS:你可以使用 此链接 查看 unicode 字符转换。
更多示例和常见问题请参见:ES2017 新特性:字符串方法:padStart 和 padEnd
4.Object.getOwnPropertyDescriptors
此方法返回给定对象的所有属性的所有详细信息(包括 getter get 和 setter set方法)。 添加它的主要动机是允许浅复制/克隆对象到另一个对象,该对象也复制 getter 和 setter 函数而不像 Object.assign。
Object.assign 浅复制除原始源对象的 getter 和 setter 函数之外的所有信息。
下面的示例显示了 Object.assign 和 Object.getOwnPropertyDescriptors 以及 Object.defineProperties之间的区别,以将原始对象 Car 复制到新对象 ElectricCar 中。 你将看到,通过使用 Object.getOwnPropertyDescriptors,discount getter 和 setter 函数也会复制到目标对象中。
之前…

以后…

var Car = { name: 'BMW', price: 1000000, set discount(x) { this.d = x; }, get discount() { return this.d; }, }; // 打印 Car 对象 'discount' 属性的详细信息 console.log(Object.getOwnPropertyDescriptor(Car, 'discount')); // 打印 .. // { // get: [Function: get], // set: [Function: set], // enumerable: true, // configurable: true // } //使用 Object.assign 将 Car 的属性复制到 ElectricCar const ElectricCar = Object.assign({}, Car); // 打印 ElectricCar 对象 'discount' 属性的详细信息 console.log(Object.getOwnPropertyDescriptor(ElectricCar, 'discount')); // 打印 .. // { // value: undefined, // writable: true, // enumerable: true, // configurable: true // } //⚠️ 请注意,ElectricCar 对象中的 'discount' 属性缺少 getter 和 setter !👎👎 // 使用 Object.defineProperties 将 Car 的属性复制到 ElectricCar2 , // 并使用 Object.getOwnPropertyDescriptors 提取 Car的属性 const ElectricCar2 = Object.defineProperties({}, Object.getOwnPropertyDescriptors(Car)); // 打印 ElectricCar2 对象的 'discount' 属性的详细信息 console.log(Object.getOwnPropertyDescriptor(ElectricCar2, 'discount')); // 打印.. // { get: [Function: get], 👈🏼👈🏼👈🏼 // set: [Function: set], 👈🏼👈🏼👈🏼 // enumerable: true, // configurable: true // } // 请注意,ElectricCar2 对象中的 'discount' 属性存在 getter 和 setter !
更多示例和常见问题请参见:ES2017 新特性:Object.getOwnPropertyDescriptors()
5.在函数参数中添加尾逗号
这是一个小更新,允许我们在函数最后一个参数后面有逗号。 为什么? 帮助使用像 git blame 这样的工具,防止添加一个参数却需要修改两行代码。
以下示例显示了问题和解决方案。

注意:你也可以在调用函数时使用尾逗号!
更多示例和常见问题请参见:ES2017 新特性:函数参数列表和调用尾逗号
6. Async/Await
到目前为止,这个特性应该是目前为止是最重要和最有用的功能。async 函数解决了回调地狱的问题,并使整个代码看起来简单。
async 关键字告诉 JavaScript 编译器以不同方式处理函数。 只要到达该函数中的 await 关键字,编译器就会暂停。 它假定 await 之后的表达式返回一个 promise 并等待,直到 promise 被 resolved 或被 rejected ,然后才继续执行。
在下面的示例中,getAmount 函数调用两个异步函数 getUser 和 getBankBalance。 我们可以用 Promise 做到这一点,但是使用 async await 更加优雅和简单。

6.1 Async 函数本身返回一个 Promise 。
如果你正在等待 async 函数的结果,则需要使用 Promise 的 then 语法来捕获其结果。
在以下示例中,我们希望使用 console.log 但不在 doubleAndAdd 中记录结果。 所以我们想等待并使用 then 语法将结果传递给console.log 。

6.2 并行调用 async/await
在前面的例子中,我们调用 await 两次,但每次我们等待一秒钟(总共2秒)。相反,我们可以并行调用它,因为使用 Promise.all 并行调用 a 和 b 。

6.3 async/await 函数的错误处理
使用 async/await 时,有多种方法可以处理错误。
选项1-在函数中使用try catch

//Option 1 - Use try catch within the function async function doubleAndAdd(a, b) { try { a = await doubleAfter1Sec(a); b = await doubleAfter1Sec(b); } catch (e) { return NaN; //return something } return a + b; } //🚀Usage: doubleAndAdd('one', 2).then(console.log); // NaN doubleAndAdd(1, 2).then(console.log); // 6 function doubleAfter1Sec(param) { return new Promise((resolve, reject) => { setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val); }, 1000); }); }
选项2-捕获(Catch) await 表达式
由于每一个 await 表达式返回的都是 Promise,我们可以直接在每一行上面添加 catch。

//Option 2 - *Catch* errors on every await line //as each await expression is a Promise in itself async function doubleAndAdd(a, b) { a = await doubleAfter1Sec(a).catch(e => console.log('"a" is NaN')); // 👈 b = await doubleAfter1Sec(b).catch(e => console.log('"b" is NaN')); // 👈 if (!a || !b) { return NaN; } return a + b; } //🚀Usage: doubleAndAdd('one', 2).then(console.log); // NaN and logs: "a" is NaN doubleAndAdd(1, 2).then(console.log); // 6 function doubleAfter1Sec(param) { return new Promise((resolve, reject) => { setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val); }, 1000); }); }
选项3-捕获(Catch) 整个async-await函数

//Option 3 - Dont do anything but handle outside the function //since async / await returns a promise, we can catch the whole function's error async function doubleAndAdd(a, b) { a = await doubleAfter1Sec(a); b = await doubleAfter1Sec(b); return a + b; } //🚀Usage: doubleAndAdd('one', 2) .then(console.log) .catch(console.log); // 👈👈🏼<------- use "catch" function doubleAfter1Sec(param) { return new Promise((resolve, reject) => { setTimeout(function() { let val = param * 2; isNaN(val) ? reject(NaN) : resolve(val); }, 1000); }); }
ECMAScript 2018
1. 共享内存和 atomics
这是一个巨大的,非常先进的功能,并且是对 JS 引擎的核心增强。
这个特性的主要目的是给 JavaScript 提供多线程功能,以便JS开发人员通过自己管理内存来编写高性能的并发程序,而不是让JS引擎管理内存。
这是通过一种名为 SharedArrayBuffer 的新型全局对象完成的,该对象实质上将数据存储在共享内存空间中。因此,这些数据可以在主JS线程和 Web-worker 线程之间共享。
之前,如果我们想在主 JS 线程和 web-worker 之间共享数据,我们必须复制数据并使用 postMessage 将其发送到另一个线程。
现在,你只需使用 SharedArrayBuffer ,主线程和多个 web-worker 线程都可以立即访问数据。
但是在线程之间共享内存会导致竞争条件(即多个进程同时操作一个内存)。为了帮助避免竞争条件,引入了 Atomics 全局对象。 Atomics 提供了各种方法来在线程使用其数据时锁定共享内存。它还提供了安全地更新共享内存中的此类数据的方法。
建议通过某个库使用此功能,但是现在没有基于此功能构建的库。
如果你有兴趣,我建议阅读:
- From Workers to Shared Memory?—?lucasfcosta
- A cartoon intro to SharedArrayBuffers?—?Lin Clark
- Shared memory and atomics?—?Dr. Axel Rauschmayer
2.移除了标记模板字面量的限制
首先,我们需要澄清“标记模板字面量”是什么,以便我们更好地理解这个功能。
在 ES2015+ 中,有一个称为标记模板文字的功能,允许开发人员自定义字符串的插值方式。 例如,在标准方式中,字符串被插入如下…

在标记的字面量中,你可以编写一个函数来接收字符串字面量的硬编码部分,例如 ['Hello','!'] 并且替换变量,例如 ['Raja'] ,作为参数进入一个自定义函数(例如 greet ),并从该自定义函数返回任何你想要的内容。
下面的示例显示我们的自定义 “Tag” 函数 greet,如“Good Morning” “Good afternoon”,等等,取决于当天到字符串字面量的时间,并返回自定义字符串。
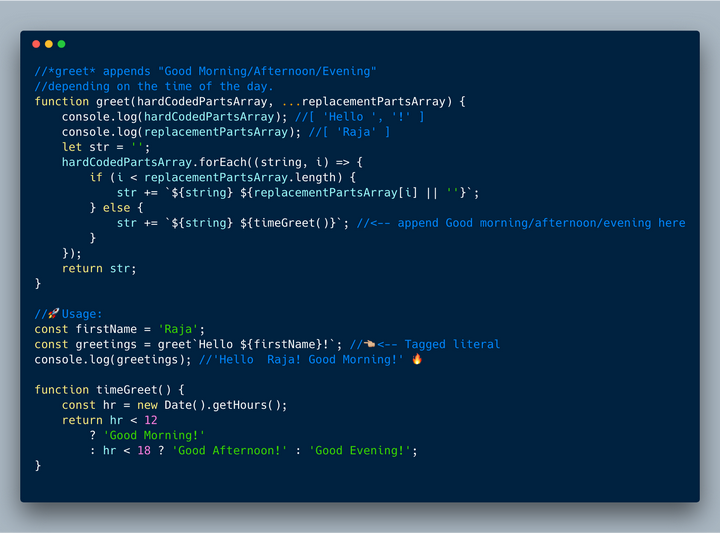
//A "Tag" function returns a custom string literal. //In this example, greet calls timeGreet() to append Good //Morning/Afternoon/Evening depending on the time of the day. function greet(hardCodedPartsArray, ...replacementPartsArray) { console.log(hardCodedPartsArray); //[ 'Hello ', '!' ] console.log(replacementPartsArray); //[ 'Raja' ] let str = ''; hardCodedPartsArray.forEach((string, i) => { if (i < replacementPartsArray.length) { str += `${string} ${replacementPartsArray[i] || ''}`; } else { str += `${string} ${timeGreet()}`; //<-- append Good morning/afternoon/evening here } }); return str; } //��Usage: const firstName = 'Raja'; const greetings = greet`Hello ${firstName}!`; //����<-- Tagged literal console.log(greetings); //'Hello Raja! Good Morning!' �� function timeGreet() { const hr = new Date().getHours(); return hr < 12 ? 'Good Morning!' : hr < 18 ? 'Good Afternoon!' : 'Good Evening!'; }
现在我们讨论了 “Tagged” 函数是什么,许多人想要在不同的场景下中使用此功能,例如在终端中使用命令和 HTTP 请求来编写 URI ,等等。
⚠️标签字符串模版存在的问题
ES2015 和 ES2016 规范不允许使用转义字符,如 \u(unicode),\x(十六进制),除非它们看起来完全像 \u00A9 或 \u{2F804} 或 \xA9 。
因此,如果你有一个内部使用其他域规则(如终端规则)的 Tagged 函数,可能需要使用 \ubla123abla ,而不能是 \u0049 或 \u{@F804} ,这样你会得到一个语法错误。
在 ES2018 中,只要 Tagged 函数返回具有 “cooked” 属性(无效字符为 “undefined” )的对象中的值,然后是 “raw” 属性( 无论你想要什么)。
function myTagFunc(str) { return { "cooked": "undefined", "raw": str.raw[0] } } var str = myTagFunc `hi \ubla123abla`; //call myTagFunc str // { cooked: "undefined", raw: "hi \\unicode" }
3. 正则表达式中的 ‘dotall’ 标记
目前在RegEx中,点(“.”)可以表示任何的单一字符,但它不能与 \n , \r,\f 等换行符匹配。 例如:
//Before /first.second/.test('first\nsecond'); //false
此增强功能使点运算符可以匹配任何单个字符。为了确保不会破坏任何内容,我们需要在创建RegEx时使用 \s 标记才能使其正常工作。
//ECMAScript 2018 /first.second/s.test('first\nsecond'); //true Notice: /s 👈🏼
以下是 提案 文档中的整体API:

4. 正则表达式捕获命名组
这个增强功能带来了其他语言(如Python,Java等)的有用 RegExp 功能,称为“命名组”。这个功能允许允许正则表达式给每一个捕获组起一个名字 (?<name>...),然后,我们可以使用该名称轻松获取我们需要的任何群组。
4.1 基本的命名组例子
在下面的例子中,我们使用 (?<year>) (?<month>) (?<day>) 来为正则表达式中的不同部分分组,结果对象中会包含一个 groups 属性,其拥有 year month day 三个对象。

4.2 在正则表达式本身内使用命名组
我们可以使用 \k<group name> 格式来反向引用正则表达式本身中的组。以下示例显示了它的工作原理。

4.3 在 String.prototype.replace 中使用命名组
命名组也可以在 String 的 replace 方法中使用,比如用来交换一个字符串中各个部分的位置。
例如,将firstName, lastName 更改为 lastName, firstName。

5. 对象的剩余属性
Rest 运算符 ...(三个点)允许我们提取 Object 的剩余属性。
5.1 我们可以使用展开运算符展开我们想要的属性:

5.2 或者我们借助展开运算符,移除我们不想要的属性 🔥🔥

6.展开对象的属性
展开属性看起来就像 Rest 运算符,都是三个点 ...,但不同之处在于你使用展开操作符来创建(重构)新对象。
提示:展开(spread)运算符用于等号的右侧。剩余(Rest)运算符用在等号的左侧。

7.正则表达式后行断言(Lookbehind)
这是 RegEx 的一个增强,它允许我们确保某些子字符串恰好出现在某些子字符串之前。
你现在可以使用一个组 (?<=…)(问号,小于,等于)来查看先行断言。
此外,你可以使用 (?<!…)(问号,小于,感叹号)来查看后行断言。基本上,只要-ve断言通过,这将匹配。
肯定断言:假设我们要确保 # 符号存在于 winning 之前(即:#winning),并希望正则表达式只返回字符串 “winning” 。下面是我们的做法:

否定断言:假设我们想要从具有 € 符号的行中提取数字,而不是 $ 。

8. RegExp Unicode属性转义
提案链接:https://github.com/tc39/proposal-regexp-unicode-property-escapes
编写 RegEx 以匹配各种 unicode 字符并不容易。像 \w,\W,\d 等只匹配英文字符和数字。但是其他语言中的数字如印地语,希腊语等等该怎么办呢?
这就是 Unicode 属性转义的用武之地。事实证明,Unicode 为每个符号(字符)添加元数据属性,并使用它来分组或表征各种符号。
例如,Unicode 数据库将所有印地语字符(??????)归为一个名为 Script 的属性,其值为 Devanagari ,另一个属性为Script_Extensions,其值为 Devanagari 。所以我们可以搜索 Script=Devanagari 并获得所有印地语字符。
梵文可以用于各种印度语言,如马拉地语,印地语,梵语等。
从 ECMAScript 2018 开始,我们可以使用 \p 来转义字符以及 {Script = Devanagari} 以匹配所有这些印度字符。也就是说,我们可以在 RegEx 中使用:\p{Script=Devanagari} 来匹配所有梵文字符。

- //The following matches multiple hindi character
- /^\p{Script=Devanagari}+$/u.test('हिन्दी'); //true
- //PS:there are 3 hindi characters h
同样,Unicode 数据库将 Script_Extensions(和 Script )属性下的所有希腊字符组合为希腊语。 所以我们可以使用 Script_Extensions=Greek 或 Script=Greek 搜索所有希腊字符。
也就是说,我们可以在RegEx中使用: \p{Script=Greek} 来匹配所有希腊字符。

- //The following matches a single Greek character
- /\p{Script_Extensions=Greek}/u.test('π'); // true
此外,Unicode数据库在布尔属性 Emoji ,Emoji_Component, Emoji_Presentation ,Emoji_Modifier和 Emoji_Modifier_Base 下存储各种类型的 Emojis,其属性值为 true。 因此,我们只需选择 Emoji 符号即可搜索所有表情符号。
也就是说,我们可以使用:\p{Emoji},\Emoji_Modifier 等来匹配各种 Emojis 。
以下示例将使一切清楚。

//The following matches an Emoji character /\p{Emoji}/u.test('❤️'); //true //The following fails because yellow emojis don't need/have Emoji_Modifier! /\p{Emoji}\p{Emoji_Modifier}/u.test('✌️'); //false //The following matches an emoji character\p{Emoji} followed by \p{Emoji_Modifier} /\p{Emoji}\p{Emoji_Modifier}/u.test('✌🏽'); //true //Explaination: //By default the victory emoji is yellow color. //If we use a brown, black or other variations of the same emoji, they are considered //as variations of the original Emoji and are represented using two unicode characters. //One for the original emoji, followed by another unicode character for the color. // //So in the below example, although we only see a single brown victory emoji, //it actually uses two unicode characters, one for the emoji and another // for the brown color. // //In Unicode database, these colors have Emoji_Modifier property. //So we need to use both \p{Emoji} and \p{Emoji_Modifier} to properly and //completely match the brown emoji. /\p{Emoji}\p{Emoji_Modifier}/u.test('✌🏽'); //true
最后,我们可以使用大写“P”( \P )转义字符,而不是小写“p”( \p )来否定匹配。
参考:
9.Promise.prototype.finally()
finally() 是一个添加到 Promise 实例的新方法。 主要考虑是允许在 resolve 或 reject 调用之后执行一些清理性质的代码。finally 被执行的时候不会被传入任何函数,并且无论什么时候都会被执行。
我们来看看各种情况。




10.异步迭代
这是一个非常有用的特性。 基本上它允许我们轻松创建异步代码循环!
此特性添加了一个新的“for-await-of”循环,允许我们在循环中调用返回 promises(或带有一堆 promise 的 Arrays )的异步函数。 循环会等待每个 Promise 在进行下一个循环之前 resolve 。

---------------------
作者:探索之路慢慢
来源:CNBLOGS
原文:https://www.cnblogs.com/amujoe/p/11076876.html
版权声明:本文为作者原创文章,转载请附上博文链接!
内容解析By:CSDN,CNBLOG博客文章一键转载插件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号