范数约束的理解
常见范数的含义
1-范数:
,即向量元素绝对值之和,matlab调用函数norm(x, 1) 。
2-范数:
,Euclid范数(欧几里得范数,常用计算向量长度),即向量元素绝对值的平方和再开方,matlab调用函数norm(x, 2)。
-范数:
,即所有向量元素绝对值中的最大值,matlab调用函数norm(x, inf)。
-范数:
,即所有向量元素绝对值中的最小值,matlab调用函数norm(x, -inf)。
p-范数:
,即向量元素绝对值的p次方和的1/p次幂,matlab调用函数norm(x, p)。
范数的图形理解:
不同范数对应的曲线如下图:
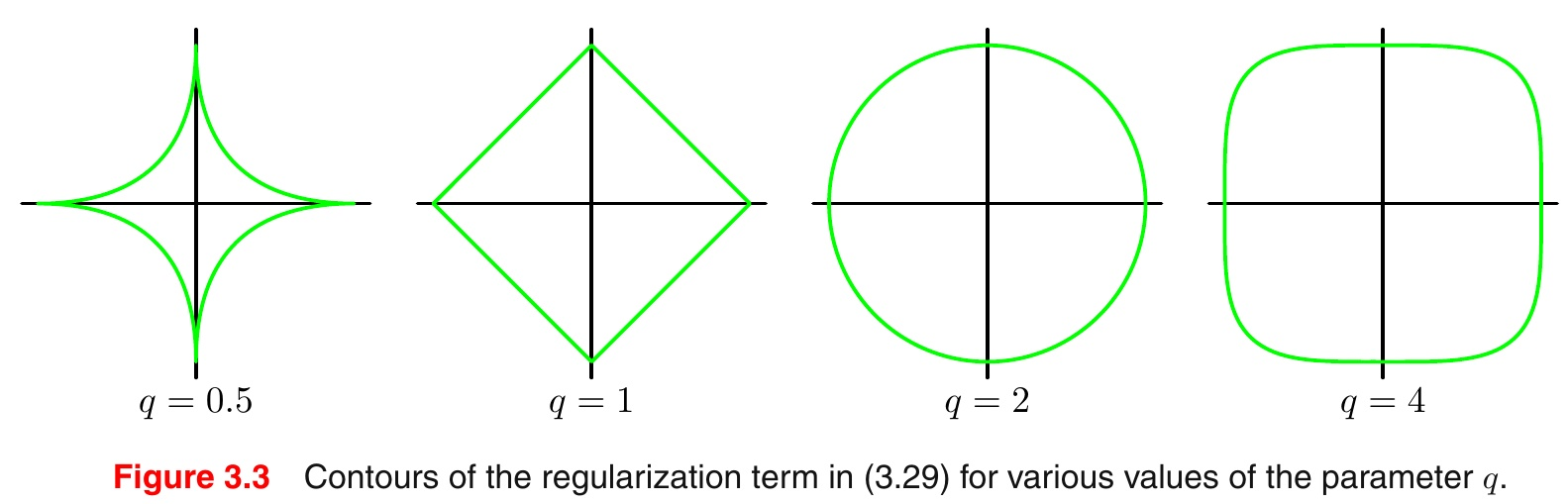
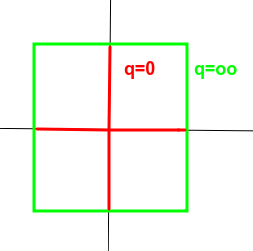
可以明显看到一个趋势,即q越小,曲线越贴近坐标轴,q越大,曲线越远离坐标轴,并且棱角越明显。那么 q=0 和 q=oo 时极限情况如何呢?猜猜看。
以1范数和2范数为例:
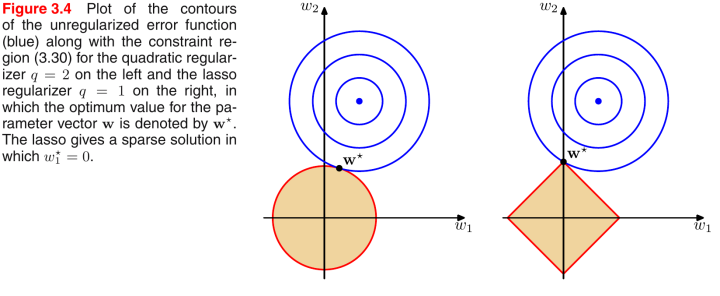
上图中,蓝色的圆圈表示原问题可能的解范围,橘色的表示正则项可能的解范围。而整个目标函数(原问题+正则项)有解当且仅当两个解范围相切。从上图可以很容易地看出,由于2范数解范围是圆,所以相切的点有很大可能不在坐标轴上(感谢评论区@临熙指出表述错误),而由于1范数是菱形(顶点是凸出来的),其相切的点更可能在坐标轴上,而坐标轴上的点有一个特点,其只有一个坐标分量不为零,其他坐标分量为零,即是稀疏的。所以有如下结论,1范数可以导致稀疏解,2范数导致稠密解。那么为什么不用0范数呢,理论上它是求稀疏解最好的规范项了。然而在机器学习中,特征的维度往往很大,解0范数又是NP-hard问题,所以在实际中不可行。但是用1范数解是可行的,并且也可以得到稀疏解,所以实际稀疏模型中用1范数约束。
至此,我们总结一下,在机器学习中,以0范数和1范数作为正则项,可以求得稀疏解,但是0范数的求解是NP-hard问题; 以2范数作为正则项可以得到稠密解,并且由于其良好的性质,其解的定义很好,往往可以得到闭式解,所以用的很多。
范数总结知识:




你不点赞 我不开心 —_— 鲁迅《网友回忆录》
-----------------------------------
世界上只有一种真正的英雄主义:
那就是在认识到生活的真相后
依然选择热爱它
-----------------------------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号