
对比特币相关的一些技术细节的补充
在上一篇文章里我简单的谈了一下比特币的原理。考虑到主要是为了写给策划看的,因此很多技术细节都没提及。因此我想在这篇文章里继续说说那些被忽略,但是却是很有意思的细节。
Merkle Tree
区块链中的每一个节点其实是使用Merkle Tree这种数据结构来存储交易数据的。点击查看Merkle Tree的介绍
而每个Block Head其实仅存储了Merkle Tree的根节点,如下图所示:
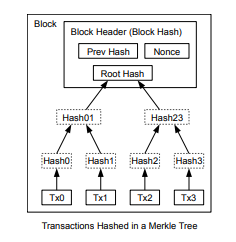
注:图片取自于Bitcoin: A Peer-to-Peer Electronic Cash System
下面我说说,Merkle Tree是如何做查找操作的。
假设我拥有一个交易数据的集合。如果把交易数据按照一般的集合实现的方式(列表、哈希表之类)构建在内存里,免不了要占用较多的内存。因此我把这些交易数据构建成一个Merkle Tree,这样做的好处就是,仅需要在内存里存一个根节点即可。
那么问题来了,在仅知道Merkle Tree的根节点的情况下,如何获知一个交易Tx是否存在于这个集合中呢?
举例来说,现在我手上握有这个根节点Root Hash,你要如何说服我叶子节点Tx3是在这个集合当中呢。方法就是,需要你给出Tx3、Hash2、Hash01这几个的值。我在得知这些值后,首先根据Tx3的内容计算其哈希值Hash3,然后将结果和你提供的Hash2进一步哈希,得到Hash23,再将其和你提供的Hash01哈希。最终我将得到一个计算出来的Root Hash',比较这个值和我手中持有的Root Hash是否一致。若是,则我相信Tx3是在这个集合当中。
这个过程就是Merkle Proof。
因为Block Head仅存储的是Root Hash,而不存储具体的交易数据。因此保证了Block Head的size较小且是固定的,这样做也方便了时间戳服务器计算工作量证明。
UTXO
虽说通过把交易数据存储到了区块链之后,理论上来说一个时间戳服务器可以通过遍历,来确定某个账户的余额信息,从而进行校验。但是对每一个收集得来的交易都这么遍历未免太傻了。那么比特币是怎么做的呢?
事实上,比特币通过utxo( Unspent Transaction Outputs)来表示“账户余额”。简单来说就是,当前我可以使用的比特币,实际上是过往别人向我支付的那些交易中,我未使用的交易。交易数据有记录相关比特币的数量,因此我的余额就是这些未花费的交易数据中,比特币的总和。用下图来说明:

注:图片取自https://bitcoin.org/en/developer-guide
图中的每一个矩形,表示了一个交易数据。由图可知,交易数据中必定仅会有一个input和至少一个output(output数量是允许多个的)。也就是说,每当我们尝试花费一笔钱的时候,必须明确的指出这笔钱是来自于之前的哪个交易。这样做的好处就是,时间戳服务器可以较为快速的对交易账户进行验证。一个full node时间戳服务器会维护一个当前最新的utxo集合。当需要对某个交易进行验证时,它可从这个集合中快速的索引出input所指向的那次交易。之后便可验证,是否有超出余额支付,是否拥有私钥等。
P2PKH vs P2SH
之前我说的,比特币的交易是支付给某个公钥的,其实这个说法不太准确。准确的说,比特币交易数据中包含的是一个pubkey script作为output。任何能通过pubkey script验证的人,即可使用这笔钱。通过pubkey script验证的方法是,提供一个与之对应的signature scripts。
pubkey script有两种形式:
(1)P2PKH(Pay-To-Public-Key-Hash)。output所绑定的是一个公钥,任何人只要能证明自己拥有公钥对应的私钥,即可通过验证。这也是一般大多数情况下使用的方式。
(2)P2SH(pay-to-script-hash)。output所绑定的是一个script,任何人只要能通过script提出的要求,即可通过验证。这种pubkey script允许我们使用更灵活的交易验证方式。比如说不仅要求能证明拥有私钥、还要求了别的什么条件。只有在都满足这样条件下才允许使用这笔钱。
实际上P2SH赋予了我们定制pubkey script的能力,而通过它我们可以在使用比特币交易之外做点别的小动作。比如说,我把一窜数据附加到定制的pubkey script中,那么随着这个交易被写入区块链,我便可以永久的保存这份数据,亦可以证明这个数据在过往的一段时间内存在的事实。这串数据已经变成不可修改的。因此区块链还有一个这样的能力,就是能证明在过去的一个时间点开始,某一个数据就已经存在了。
参考资料:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号