
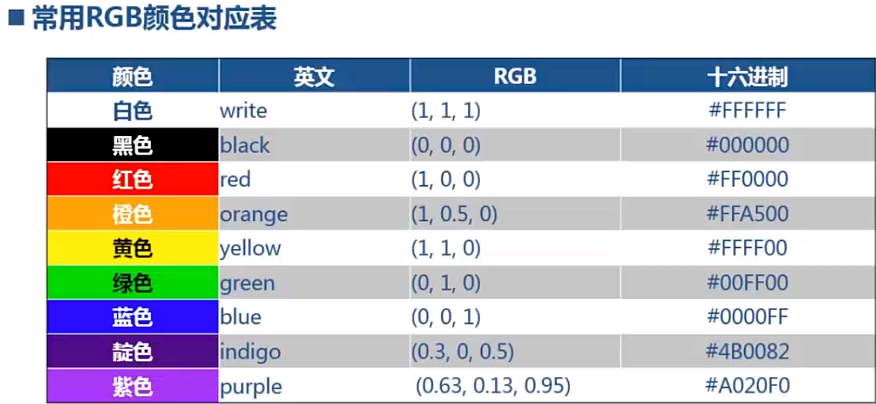
1、散点图
plot(x, y, '.', color = (r,g,b))
plt.xlable('x轴标签')
plt.ylable('y轴标签')
x,y x轴和y 轴的序列 ; '.', '。'小点还是大点 color, 散点图的颜色,可以用rgb定义,也可以用英文字母定义
plt.grid(True, linestyle = "-.", color = "r", linewidth = "3")
#散点图 import matplotlib#%% from pandas import read_csv#%% import matplotlib.pyplot as plt from matplotlib.font_manager import _rebuild _rebuild() from pylab import mpl #%% data = read_csv("/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.1/data.csv") #%% 设置成中文!!!! mpl.rcParams['font.sans-serif']=[u'SimHei'] mpl.rcParams['axes.unicode_minus']=False #%% #plt.plot(data['广告费用'], data['购买用户数'], '.') #plt.plot(data['广告费用'], data['购买用户数'], 'o') plt.plot(data['广告费用'], data['购买用户数'], 'o', color='yellow') #plt.plot(data['广告费用'], data['购买用户数'], 'o', color=(1, 1, 0)) #plt.plot(data['广告费用'], data['购买用户数'], 'o', color='#FFFF00') plt.xlabel('广告费用')#%% plt.ylabel('购买用户数') plt.grid(True) #%% plt.grid(True, linestyle = "-.", color = "r", linewidth = "3") #%% plt.show()
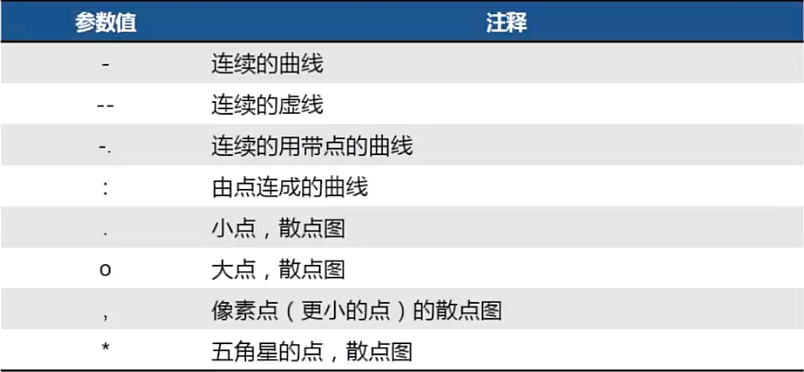
2、折线图
plot(x, y, style, color, linewidth)
title('图的标题')
style 画线的样式 color 画线的颜色 linewidth 线的宽度
#折线图 import pandas#%% from pandas import read_csv#%% from matplotlib import pyplot as plt data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.2/data.csv') #对日期格式进行转换 data['日期']=pandas.to_datetime(data['日期']) data.rename(columns={'日期':'购买日期'},inplace=True) #设置线条粗细 plt.plot(data['购买日期'], data['购买用户数'], '-', color='r', lineWidth=2) plt.xlabel('购买日期') plt.ylabel('购买用户数') #'-' 顺滑的曲线 #'--' 虚线 #'-.' 线加点 #':' 由点组成的曲线 #'.' 散点图 #',' 像素点的散点图 #'o' 大点的散点图 #'v' 下三角标记的散点图 #'^' 上上角标记的散点图 #'<' 左角标记的散点图 #'>' 右角标记的散点图 #'1' 伞形下的标记散点图 #'2' 伞形上的标记散点图 #'3' 伞形左的标记散点图 #'4' 伞形右的标记散点图 #'s' 正方形标记的散点图 #'p' 五角形标记的散点图 #'*' 五角星标记的散点图 #'h' 多边形标记的散点图 #'H' hexagon2 marker #'+' plus marker #'x' x marker #'D' diamond marker #'d' thin_diamond marker #'|' vline marker #'_' hline marker plt.title('购买用户数时间序列图') plt.show()
3、饼图
pie(x, labels, colors, explode, autopct);
x 进行绘制的序列, labels 拼图的个部分标签, colors, 饼图的各部分颜色,使用rgb标色 explode需要突出的块状序列,即各块距离中心的位置 autopct 饼图占比的显示格式 , %.2f: 保留两位小数
import numpy import matplotlib from pandas import read_csv import matplotlib.pyplot as plt#%% data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.3/data.csv') #%% # 进行分组 gb = data.groupby( by=['通信品牌'], as_index=False )['号码'].agg({ '用户数':numpy.size }) #%% #pip install matplotlib font = { 'family' : 'SimHei' } matplotlib.rc('font', **font) #%% plt.pie(gb['用户数'], labels=gb['通信品牌'],colors=[(1,0.1,1),(1,0.5,1),(0,0,1)],explode=[0.2,0,0.1],autopct='%.2f%%')#%% plt.show()
4. 柱形图:
d.bar(left, height, width, color)
barh(bottom, width, height,color)
left, x 轴的位置序列,一般采用arrange函数产生一个序列
height, y 轴的数值序列,也就是柱形图的高度
width , 柱形图的宽度,一般设置为1即可
color 柱形图 填充颜色
d.xticks (位置,标签)
d.yticks (位置,标签)
普通 竖向/横向 柱形图
import numpy; import matplotlib; from pandas import read_csv; from matplotlib import pyplot as plt; font = { 'family' : 'SimHei' }; matplotlib.rc('font', **font); data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.4/data.csv'); gb = data.groupby( by=['手机品牌'] )['月消费(元)'].sum() index = numpy.arange(gb.size); #竖向柱形图 plt.bar(index, gb, 1, color='G'); plt.show(); #%% 加上了标签 plt.bar(index, gb, 1, color='G'); plt.xticks(index + 1/2, gb.index); plt.show(); #%% #横向柱形图 并加上了标签 plt.barh(index, gb, 1, color='G'); plt.yticks(index + 1/2, gb.index); plt.show();
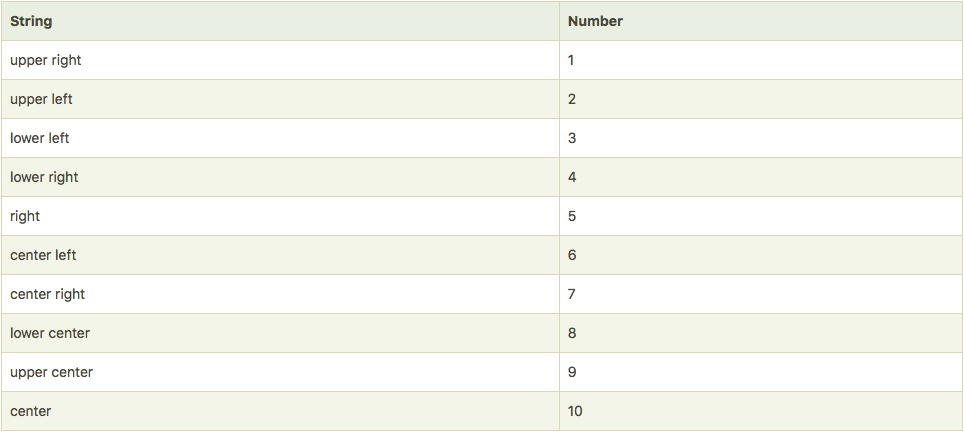
多组柱状图
d.index.levels[a] :多层索引取第a层
d.[:,a] 多层索引 依据第二个索引求值 适用于series
d.legend(标签,loc=2) loc为存放位置
import numpy import matplotlib from pandas import read_csv from matplotlib import pyplot as plt font = { 'family' : 'SimHei' } matplotlib.rc('font', **font) data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.4/data.csv') d1 = '手机品牌'#%% d2 = '通信品牌'#%% v = "月消费(元)" # 进行分组 并将多级分组放入索引里面 df = data.groupby(by=[d1,d2])['月消费(元)'].apply(lambda x: sum(x)) #%% d1size = df.index.levels[0].size #%% d2size = df.index.levels[1].size # 求出横坐标的为主 index = numpy.arange(d1size) #%% colors=['r', 'g', 'b'] #%% a = df.index.levels[0] b = df.index.levels[1] #%% print(df[:,'全球通']) # 依据第二格索引求值 适用于series print(b[0]) # 索引的取值 #%% for i in range(0, d2size): x = b[i] # 求出索引名 sb = df[:,x] # 通过索引求出值 sa = sb.values # 转换成向量 bar = plt.bar(index * d2size + i, sa, color=colors[i]) # 这里用series 和array 即 sb 和 sa都行 lIndex = numpy.arange(d1size)*d2size # 取等差数列 plt.xticks(lIndex + 3/2, df.index.levels[0]) # 确定横坐标的标签 plt.legend(df.index.levels[1],loc=2) # 带等于号的参数放在后面,此参数用来调整所在位置 #%% plt.show()#%%
多分类累积柱状图
多了一个bottoms 参数
import numpy#%% import matplotlib#%% from pandas import read_csv#%% from matplotlib import pyplot as plt#%% font = { 'family' : 'SimHei' }#%% matplotlib.rc('font', **font)#%% data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.4/data.csv')#%% d1 = '手机品牌'#%% d2 = '通信品牌'#%% v = "月消费(元)"#%% gb = data.groupby([d1, d2])['月消费(元)'].sum()#%% d1size = gb.index.levels[0].size d1 = gb.index.levels[0] d2size = gb.index.levels[1].size d2= gb.index.levels[1] index = numpy.arange(d1size)#%% colors = ['r', 'g', 'b']#%% #%% bsum = index*0.0#%% print(bsum) # 多分类累积柱状图 bsum 有点不太懂 for i in range(0, d2size): x = d2[i] subgb = gb[:,x] bar = plt.bar(index, subgb, color=colors[i], bottom=bsum) # 是为了让最开始的不被覆盖掉? bsum += subgb # bottom需要传入的是[第0个类别~(当前类别-1)]的数据总和。 plt.xticks(index+1/2, gb.index.levels[0])#%% plt.legend(gb.index.levels[1])#%% plt.show()#%%
5.直方图
hist(x,color,bins,cumulative=False)
x 需要进行绘制的向量 color 直方图的填充颜色 bins 设置直方图的分组个数
cumulative 设置是否累积技术
import matplotlib; from pandas import read_csv; from matplotlib import pyplot as plt; import numpy font = { 'family' : 'SimHei' }; matplotlib.rc('font', **font); data = read_csv('/Volumes/CHASESKY/python/03-数据分析与数据挖掘篇/1-数据分析数据可视化实战-(Python3.5)/章节5数据可视化/5/5.4/data.csv') data['购买用户数']=numpy.random.randint(0,100,31402) #%% plt.hist(data['购买用户数']); plt.show(); # 设置了分组个数 plt.hist(data['购买用户数'], bins=50); plt.show(); # 进行累积 plt.hist(data['购买用户数'], bins=20, cumulative=True); plt.show();
