第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
1、elasticsearch(搜索引擎)的查询
elasticsearch是功能非常强大的搜索引擎,使用它的目的就是为了快速的查询到需要的数据
查询分类:
基本查询:使用elasticsearch内置的查询条件进行查询
组合查询:把多个查询条件组合在一起进行复合查询
过滤:查询同时,通过filter条件在不影响打分的情况下筛选数据
2、elasticsearch(搜索引擎)创建数据
首先我们先创建索引、表、以及字段属性、字段类型、添加好数据
注意:一般我们中文使用ik_max_word中文分词解析器,所有在需要分词建立倒牌索引的字段都要指定,ik_max_word中文分词解析器
系统默认不是ik_max_word中文分词解析器
ik_max_word中文分词解析器是elasticsearch(搜索引擎)的一个插件,在elasticsearch安装目录的plugins/analysis-ik文件夹里,版本为5.1.1
更多说明:https://github.com/medcl/elasticsearch-analysis-ik
说明:
#创建索引(设置字段类型) #注意:一般我们中文使用ik_max_word中文分词解析器,所有在需要分词建立倒牌索引的字段都要指定,ik_max_word中文分词解析器 #系统默认不是ik_max_word中文分词解析器 PUT jobbole #创建索引设置索引名称 { "mappings": { #设置mappings映射字段类型 "job": { #表名称 "properties": { #设置字段类型 "title":{ #表名称 "store": true, #字段属性true表示保存数据 "type": "text", #text类型,text类型可以分词,建立倒排索引 "analyzer": "ik_max_word" #设置分词解析器,ik_max_word是一个中文分词解析器插件 }, "company_name":{ #字段名称 "store": true, #字段属性true表示保存数据 "type": "keyword" #keyword普通字符串类型,不分词 }, "desc":{ #字段名称 "type": "text" #text类型,text类型可以分词,但是没有设置分词解析器,使用系统默认 }, "comments":{ #字段名称 "type": "integer" #integer数字类型 }, "add_time":{ #字段名称 "type": "date", #date时间类型 "format":"yyyy-MM-dd" #yyyy-MM-dd时间格式化 } } } } }
#保存文档(相当于数据库的写入数据) POST jobbole/job { "title":"python django 开发工程师", #字段名称:值 "company_name":"美团科技有限公司", #字段名称:值 "desc":"对django的概念熟悉, 熟悉python基础知识", #字段名称:值 "comments":20, #字段名称:值 "add_time":"2017-4-1" #字段名称:值 } POST jobbole/job { "title":"python scrapy redis 分布式爬虫基础", "company_name":"玉秀科技有限公司", "desc":"对scrapy的概念熟悉, 熟悉redis基础知识", "comments":5, "add_time":"2017-4-2" } POST jobbole/job { "title":"elasticsearch打造搜索引擎", "company_name":"通讯科技有限公司", "desc":"对elasticsearch的概念熟悉", "comments":10, "add_time":"2017-4-3" } POST jobbole/job { "title":"pyhhon打造推荐引擎系统", "company_name":"智能科技有限公司", "desc":"熟悉推荐引擎系统算法", "comments":60, "add_time":"2017-4-4" }
通过上面可以看到我们创建了索引并且设置好了字段的属性、类型、以及分词解析器,创建了4条数据

3、elasticsearch(搜索引擎)基本查询
match查询【用的最多】
会将我们的搜索词在当前字段设置的分词器进行分词,到当前字段查找,匹配度越高排名靠前,如果搜索词是大写字母会自动转换成小写
#match查询 #会将我们的搜索词进行分词,到指定字段查找,匹配度越高排名靠前 GET jobbole/job/_search { "query": { "match": { "title": "搜索引擎" } } }

term查询
不会将我们的搜索词进行分词,将搜索词完全匹配的查询
#term查询 #不会将我们的搜索词进行分词,将搜索词完全匹配的查询 GET jobbole/job/_search { "query": { "term": { "title":"搜索引擎" } } }
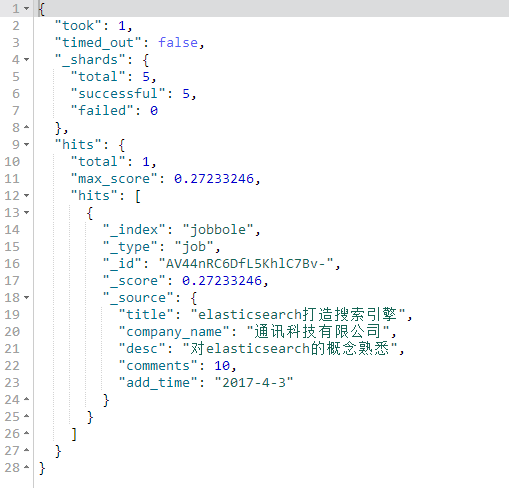
terms查询
传递一个数组,将数组里的词分别匹配
#terms查询 #传递一个数组,将数组里的词分别匹配 GET jobbole/job/_search { "query": { "terms": { "title":["工程师","django","系统"] } } }
控制查询的返回数量
from从第几条数据开始
size获取几条数据
#控制查询的返回数量 #from从第几条数据开始 #size获取几条数据 GET jobbole/job/_search { "query": { "match": { "title": "搜索引擎" } }, "from": 0, "size": 3 }
match_all查询,查询所有数据
#match_all查询,查询所有数据 GET jobbole/job/_search { "query": { "match_all": {} } }
match_phrase查询
短语查询
短语查询,会将搜索词分词,放进一个列表如[python,开发]
然后搜索的字段必须满足列表里的所有元素,才符合
slop是设置分词后[python,开发]python 与 开发,之间隔着多少个字符算匹配
间隔字符数小于slop设置算匹配到,间隔字符数大于slop设置不匹配
#match_phrase查询 #短语查询 #短语查询,会将搜索词分词,放进一个列表如[python,开发] #然后搜索的字段必须满足列表里的所有元素,才符合 #slop是设置分词后[python,开发]python 与 开发,之间隔着多少个字符算匹配 #间隔字符数小于slop设置算匹配到,间隔字符数大于slop设置不匹配 GET jobbole/job/_search { "query": { "match_phrase": { "title": { "query": "elasticsearch引擎", "slop":3 } } } }
multi_match查询
比如可以指定多个字段
比如查询title字段和desc字段里面包含python的关键词数据
query设置搜索词
fields要搜索的字段
title^3表示权重,表示title里符合的关键词权重,是其他字段里符合的关键词权重的3倍
#multi_match查询 #比如可以指定多个字段 #比如查询title字段和desc字段里面包含python的关键词数据 #query设置搜索词 #fields要搜索的字段 #title^3表示权重,表示title里符合的关键词权重,是其他字段里符合的关键词权重的3倍 GET jobbole/job/_search { "query": { "multi_match": { "query": "搜索引擎", "fields": ["title^3","desc"] } } }

stored_fields设置搜索结果只显示哪些字段
注意:使用stored_fields要显示的字段store属性必须为true,如果要显示的字段没有设置store属性那么默认为false,如果为false将不会显示该字段
#stored_fields设置搜索结果只显示哪些字段 GET jobbole/job/_search { "stored_fields": ["title","company_name"], "query": { "multi_match": { "query": "搜索引擎", "fields": ["title^3","desc"] } } }

通过sort搜索结果排序
注意:排序的字段必须是数字或者日期
desc升序
asc降序
#通过sort搜索结果排序 #注意:排序的字段必须是数字或者日期 #desc升序 #asc降序 GET jobbole/job/_search { "query": { "match_all": {} }, "sort": [{ "comments": { "order": "asc" } }] }
range字段值范围查询
查询一个字段的值范围
注意:字段值必须是数字或者时间
gte大于等于
ge大于
lte小于等于
lt小于
boost是权重,可以给指定字段设置一个权重
#range字段值范围查询 #查询一个字段的值范围 #注意:字段值必须是数字或者时间 #gte大于等于 #ge大于 #lte小于等于 #lt小于 #boost是权重,可以给指定字段设置一个权重 GET jobbole/job/_search { "query": { "range": { "comments": { "gte": 10, "lte": 20, "boost": 2.0 } } } }
range字段值为时间范围查询
#range字段值为时间范围查询 #查询一个字段的时间值范围 #注意:字段值必须是时间 #gte大于等于 #ge大于 #lte小于等于 #lt小于 #now为当前时间 GET jobbole/job/_search { "query": { "range": { "add_time": { "gte": "2017-4-1", "lte": "now" } } } }
wildcard查询,通配符查询
*代表一个或者多个任意字符
#wildcard查询,通配符查询 #*代表一个或者多个任意字符 GET jobbole/job/_search { "query": { "wildcard": { "title": { "value": "py*n", "boost": 2 } } } }
fuzzy模糊查询
#fuzzy模糊搜索 #搜索包含词的内容 GET lagou/biao/_search { "query": { "fuzzy": {"title": "广告"} }, "_source": ["title"] } #fuzziness设置编辑距离,编辑距离就是把要查找的字段值,编辑成查找的关键词需要编辑多少个步骤(插入、删除、替换) #prefix_length为关键词前面不参与变换的长度 GET lagou/biao/_search { "query": { "fuzzy": { "title": { "value": "广告录音", "fuzziness": 2, "prefix_length": 2 } } }, "_source": ["title"] }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号