第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
第三百四十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—Requests请求和Response响应介绍
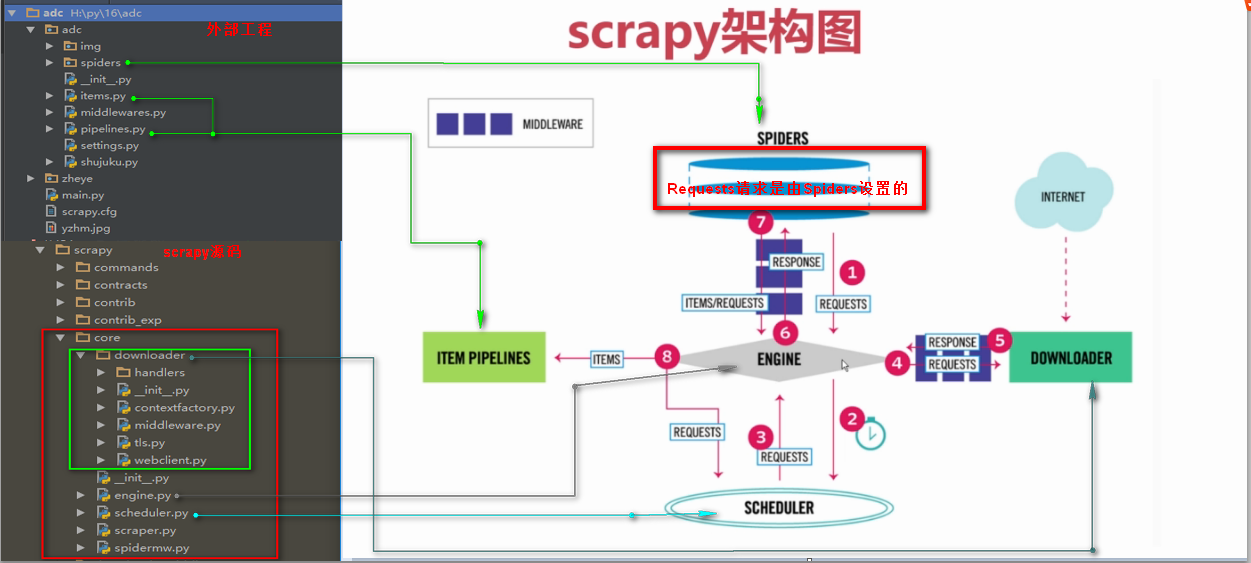
Requests请求
Requests请求就是我们在爬虫文件写的Requests()方法,也就是提交一个请求地址,Requests请求是我们自定义的
Requests()方法提交一个请求
参数:
url= 字符串类型url地址
callback= 回调函数名称
method= 字符串类型请求方式,如果GET,POST
headers= 字典类型的,浏览器用户代理
cookies= 设置cookies
meta= 字典类型键值对,向回调函数直接传一个指定值
encoding= 设置网页编码
priority= 默认为0,如果设置的越高,越优先调度
dont_filter= 默认为False,如果设置为真,会过滤掉当前url
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request,FormRequest import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider name = 'pach' #设置爬虫名称 allowed_domains = ['www.luyin.org/'] #爬取域名 # start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls """第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数""" return [Request( url='http://www.luyin.org/', headers=self.header, meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数 callback=self.parse )] def parse(self, response): title = response.xpath('/html/head/title/text()').extract() print(title)
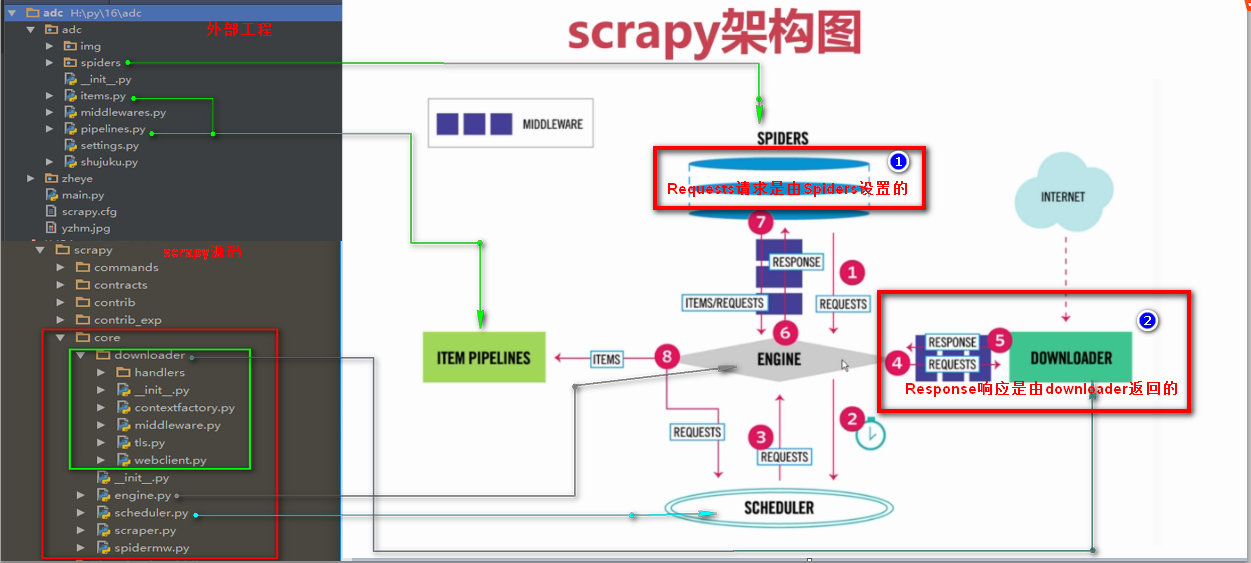
Response响应
Response响应是由downloader返回的响应

Response响应参数
headers 返回响应头
status 返回状态吗
body 返回页面内容,字节类型
url 返回抓取url
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request,FormRequest import re class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider name = 'pach' #设置爬虫名称 allowed_domains = ['www.luyin.org/'] #爬取域名 # start_urls = [''] #爬取网址,只适于不需要登录的请求,因为没法设置cookie等信息 header = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:54.0) Gecko/20100101 Firefox/54.0'} #设置浏览器用户代理 def start_requests(self): #起始url函数,会替换start_urls """第一次请求一下登录页面,设置开启cookie使其得到cookie,设置回调函数""" return [Request( url='http://www.luyin.org/', headers=self.header, meta={'cookiejar':1}, #开启Cookies记录,将Cookies传给回调函数 callback=self.parse )] def parse(self, response): title = response.xpath('/html/head/title/text()').extract() print(title) print(response.headers) print(response.status) # print(response.body) print(response.url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号