第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
我们自定义一个main.py来作为启动文件
main.py
#!/usr/bin/env python # -*- coding:utf8 -*- from scrapy.cmdline import execute #导入执行scrapy命令方法 import sys import os sys.path.append(os.path.join(os.getcwd())) #给Python解释器,添加模块新路径 ,将main.py文件所在目录添加到Python解释器 execute(['scrapy', 'crawl', 'pach', '--nolog']) #执行scrapy命令
爬虫文件
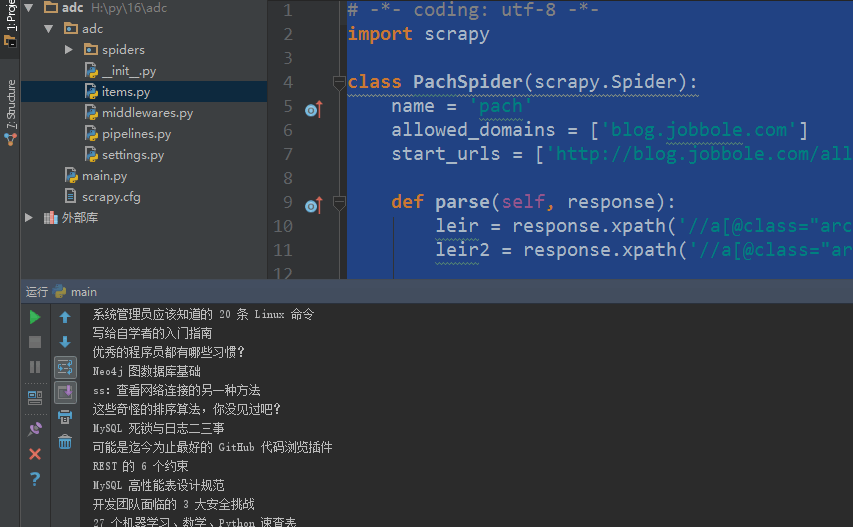
# -*- coding: utf-8 -*- import scrapy from scrapy.http import Request import urllib.response from lxml import etree import re class PachSpider(scrapy.Spider): name = 'pach' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): pass
xpath表达式
1、
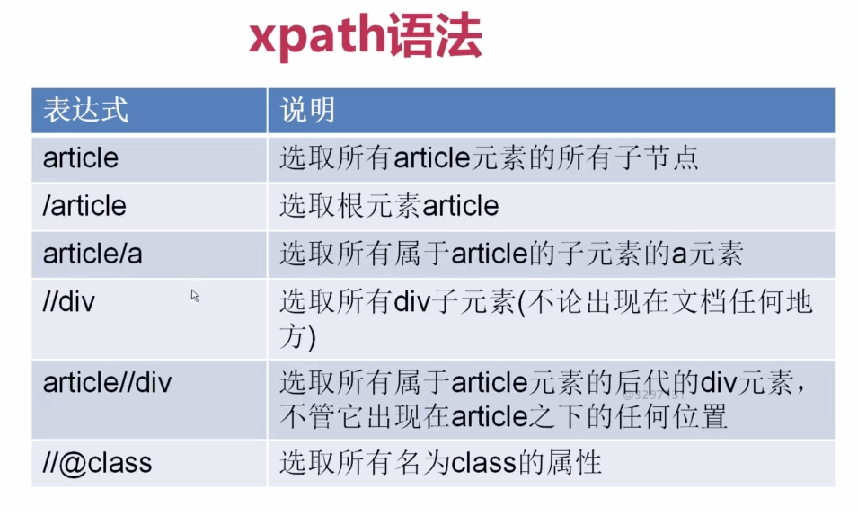
2、
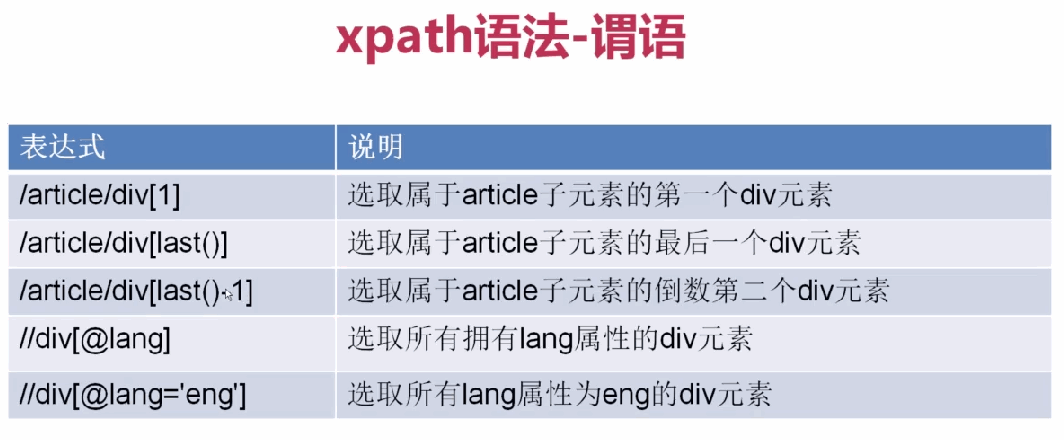
3、

基本使用
allowed_domains设置爬虫起始域名
start_urls设置爬虫起始url地址
parse(response)默认爬虫回调函数,response返回的是爬虫获取到的html信息对象,里面封装了一些关于htnl信息的方法和属性
responsehtml信息对象下的方法和属性
response.url获取抓取的rul
response.body获取网页内容
response.body_as_unicode()获取网站内容unicode编码
xpath()方法,用xpath表达式过滤节点
extract()方法,获取过滤后的数据,返回列表
# -*- coding: utf-8 -*- import scrapy class PachSpider(scrapy.Spider): name = 'pach' allowed_domains = ['blog.jobbole.com'] start_urls = ['http://blog.jobbole.com/all-posts/'] def parse(self, response): leir = response.xpath('//a[@class="archive-title"]/text()').extract() #获取指定标题 leir2 = response.xpath('//a[@class="archive-title"]/@href ').extract() #获取指定url print(response.url) #获取抓取的rul print(response.body) #获取网页内容 print(response.body_as_unicode()) #获取网站内容unicode编码 for i in leir: print(i) for i in leir2: print(i)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号