

维度建模
1 选择业务过程
2 声明粒度
3 确认维度
4 确认事实
业务过程是组织完成的操作型活动。
粒度用于确定某一事实表中的行表示什么。在选择维度或事实前必须声明粒度,因为每个候选维度或事实必须与定义的粒度保持一致。
维度提供围绕某一业务过程事件所涉及的 “谁、什么、何处、何时、为什么、如何” 等背景。维度表包含BI应用所需要的用户过滤及分类事实的描述性属性。
事实涉及来自业务过程事件的度量,基本上都是以数量值表示。一个事实表行与按照事实表粒度描述的度量事件之间存在一对一关系,因此事实表对应一个物理可观察的事件。在事实表内,所有事实只允许与声明的粒度保持一致。
一、数据仓库体系结构和建模过程、技巧。
二、维度表建模技术。
三、事实表建模技术。
一、数据仓库体系结构和建模过程、技巧
关键点:数据仓库体系结构、维度建模的四个步骤、数据仓库总线结构、一致性维度。
- 对于数据仓库来说,业务需求是第一位的。
- 数据仓库的目标:
- 随心所欲的访问数据。直观、明显、简单、易用、切割、合并、下钻、上卷。
- 一致的展现数据(相对于原来从多个系统中出来的报表不一致)。
- 适应性、扩展性、可维护性。
- 为领导决策提供支持。
- 数据仓库的组成。源数据-->数据准备区-->数据仓库(维度建模)-->数据聚集区(OLAP)-->展现。
- 数据仓库应特别注意的几点特点:
- 数据应该以维度的形式进行展示、存储和访问。
- 数据仓库中必须包含详细的原子数据。
- 必须采用共同的维度和事实表来建模。
- 数据仓库采用使用维度建模的好处:易理解、查询的高性能、修改的灵活性和可扩充性。
- 维度建模的扩展性。表现在三个方面:
- 在现有的事实表中增加维度。
- 在事实表中增加事实。
- 在维度表中增加属性。
- 维度模型设计的四个步骤。
- 选取业务(主题)。
- 声明业务处理的粒度。
- 选择维度。
- 选择事实。
- 应优先为模型选择原子性的信息,因为原子性的数据提供了最大限度的灵活性,可以接受任何可能形式的约束。
- 数据仓库总线结构。
- 实际上是一种增量建模方式,通过一致性维度来集成数据中心。
- 数据总线矩阵:业务处理、公共维度。
- 一级数据中心:衍生于单个基本源系统的数据中心,建议从一级数据中心开始建模,因为导致失败的主要风险是ETL。合并数据中心:合并多个位于不同源系统的一级数据中心。
- 维度建模复查。考虑的问题:粒度,日期维度,退化维度,维度属性采用名称而不是编码,代理关键字,维度的多少。
- 维度建模常犯的错误:
- 舍弃一致性维度和一致性事实表。
- 事实表的粒度不采用原子型。
- 基于报表来设计维度表。
- 忽视维度的变化的需求。
- 将体系与体系层次分解成多个维度。
- 在维度表中为节省空间而限制使用详细的描述属性。
- 在事实表中放置用于约束与分组操作的文本属性。
- 数据仓库成功的五个前提:
- 拥有精明、强干的业务用户。用户应该对数据仓库具有独特的见解,坚信数据仓库项目具有实现的价值。
- 机构必须存在建立数据仓库坚实而有说服力的业务动机。
- 数据仓库的可用性。
- 业务用户与IT人员之间的沟通。
- 业务分析人员的分析文化,是基于图形、数据还是直觉、传闻和一时冲动。
二、维度表建模技巧
关键点:退化维度、代理关键字、一致性维度、渐变维度、角色模仿、杂项维度、微型维度、深度可变的层次建模方法、多值维度解决办法、异构产品解决办法。
- 维度表倾向于将行数做得相当少,而将列数做的特别大。数据仓库的能力直接与维度表的属性的质量和深度成正比。
- 维度的属性采用文字而不是编码。
- 维度表通常是不规范的,几乎总是用空间换取简明性和可访问性。
- 日期维度
- 应包含星期、周末指示符、月末指示符、节假日指示符、重大事件、财政时间等。
- 如果需要处理一天中不同时间,则增加一个时间维度。
- 国别历法的处理办法,做成日期维度的支架。
- 多个时区日期的处理办法,增加维度。
- 一个维度包含多个层次,每个层次包含若干级别。
- 退化维度。一方面可以通过退化维度对数据进行分组,另一方面可以使用退化维度关联到源数据上,有利于ETL更新及排错。
- 一般情况维度个数应该控制在15个以内,维度过多影响查询性能和磁盘空间。一些小维度可以进行组合,这取决于具体的业务。
- 代理关键字。使用代理关键字的优点:
- 能实现渐变维度;
- 获得性能上的优势,节省事实表空间;
- 可以记录没有操作源码的数据(ETL过程生成);
- 处理关键字段的修改、删除等。
- 一致性维度。具有一致性的维度关键字,一致的属性名称,一致的属性定义,一致的属性值。一致性维度对于设计可以进行集成的数据中心来说,具有绝对的决定性作用。
- 渐变维度。渐变维度的处理办法:
- 类型1:改写属性值;
- 类型2:添加维度行;
- 类型3:添加维度列。
- 快变维度的处理办法:微型维度,将这些迅速变化的属性分裂成一个或者多个单独的维度。
- 实体之间存在固定的,不随时间变化的,强烈相关的关系时,应该将它们当作单一维度进行建模。
- 杂项维度。将标志与指标符从设计中剥离出来,将其封装成一个或者多个杂项维度。例如销售订单,它可能有很多离散数据(yes-no这种类型的值),这类数据常被用于增强销售分析,应该用称为杂项维度的特殊维度类型存储。
verification_ind(如果订单已经被审核,值为yes)
credit_check_flag(表示此订单的客户信用状态是否已经检查)
new_customer_ind(如果这是新客户的首个订单,值为yes)
web_order_flag(表示此订单是否是在线下的订单)
- 雪花模型的使用场合:粒度悬殊,节省空间(属性众多)。
- 深化不变的体系结构。一个层次建立单独的字段,如果某一个级别没有值,就应该用较低级别的属性覆盖该值。
- 深度可变的体系结构。使用桥接表来解决,父到子的每一条路径都包含一行记录。
- 维度的属性数量不确定时,使用关键词支架维度。
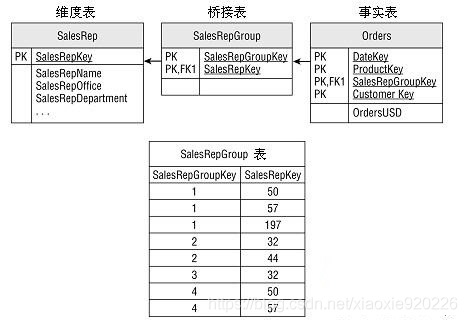
- 多值维度:一个账户拥有多个客户,一个客户也可能拥有多个账户。解决办法:桥接表
![]()
三、事实表建模技术
- 事实表中的事实分为三种类型:可加性事实,半可加性事实,非可加性事实。
- 可加型事实,指的是在所有维度加起来都有意义的数字型度量。
- 半可加型事实,指的是在特定维度下加起来有意义,另一些维度下加起来无意义的数字型度量。
- 不可加型事实,是指在所有维度下,加起来都没有意义的数字型度量。
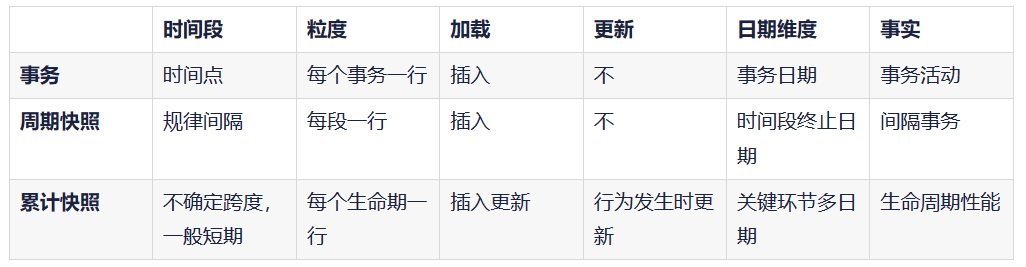
- 事实表的三种粒度:事务,周期快照,累计快照。
![]()
- 事实表倾向于具有更多的行和更少的列。
- 事实表的主键应采用复合主键,引入唯一的rowid关键字作为主键并无什么优点可言。
- 明显属于不同粒度的事实必须放在单独的事实表中。
- 将可计算的值作为事实的原因:消除用户出错的可能性,一致的引用它。例如,利润=销售额-成本额,将利润作为一个事实而不是通过展现工具进行计算得到。
- 非可加性的数据项尽量不要放到事实表中。例如,毛利润率是非可加性数据,不应该保存在事实表中,应保存分子和分母,再通过前端展现工具进行计算得到。
- 事实表的粒度很关键,决定了维度模型的扩展性。
- 周期快照事实表是最常见的设计方案。
- 累计快照事实表。适用于业务过程有明确的起止时间的短生命周期场景,如交易订单、物流订单。长生命周期的实体记录完全可以由周期快照表实现,如商品、用户。
- 事实的变化通过增加一行记录,而不是通过修改原事实数据。
- 非事实型事实表。
- 第一类,记录实际发生事件。
- 第二类,范围表,包含所有可能事件。
- 事实维度表。对于稀疏事实表,通常会在事实中存在大量的NULL值,使用事实维度表,可以将不同的事实以记录的形式保存到事实维度表中。原来在事实表中的事实如果有值产生时,就在事实维度表中插入记录,否则就不需要插入记录。
- 异构产品事实表建模。建立一个核心事实表和一簇定制事实表,使用相同的代理关键字。
- 合并事实表。将两个事实表通过公共的维度合并在一起,可以通过展现工具进行合并。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号