
Hive函数
目录
Hive版本 = 3.1.2
1.Hive内置函数
1.1 函数查看
show functions;
desc function functionName;
1.2 日期函数
- 显示当前系统时间函数:current_date()、current_timestamp()、unix_timestamp()
select current_date();
-- 当前系统日期 格式:"yyyy-MM-dd"
select current_timestamp();
-- 当前系统时间戳 格式:"yyyy-MM-dd HH:mm:ss.ms"
select unix_timestamp();
-- 当前系统时间戳 格式:距1970-01-01 0时的秒数
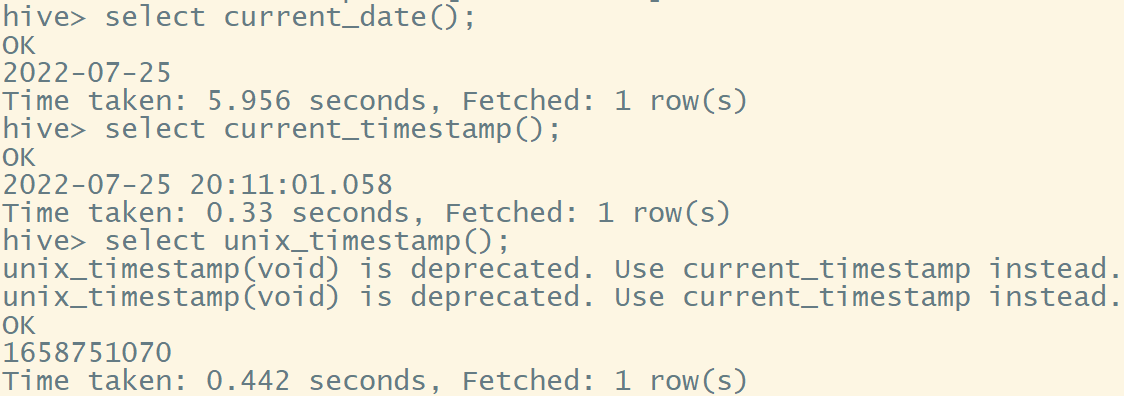
- 日期转时间戳函数:unix_timestamp()
格式:unix_timestamp([date [,pattern]])
select unix_timestamp('1970-01-01 0:0:0'); -- 传入的日期时间是东八区东时间,但返回值是相对于子午线的时间来说的
select unix_timestamp('0:0:0 1970-01-01', "HH:mm:ss yyyy-MM-dd");
select unix_timestamp(current_date());
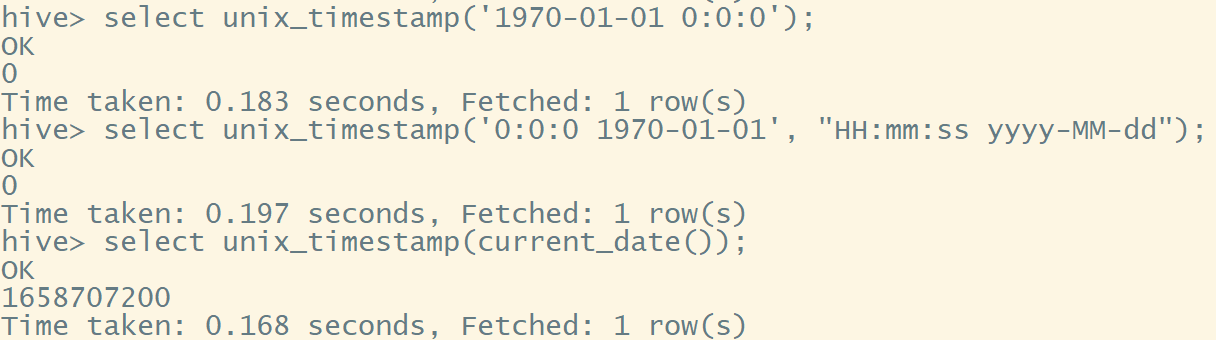
- 时间戳转日期函数:from_unixtime()
格式:from_unixtime(unix_time [,pattern])
select from_unixtime(1000000000[,'yyyy-MM-dd HH:mm:ss']);
select from_unixtime(1000000000, 'yyyyMMdd');
select from_unixtime(-3600, 'yyyy-MM-dd HH:mm:ss');
- 字符串转日期:to_date()
-- 字符串必须为 yyyy-MM-dd [HH:mm:ss[.s]] 格式
select to_date('2022-02-02 22:22:22');

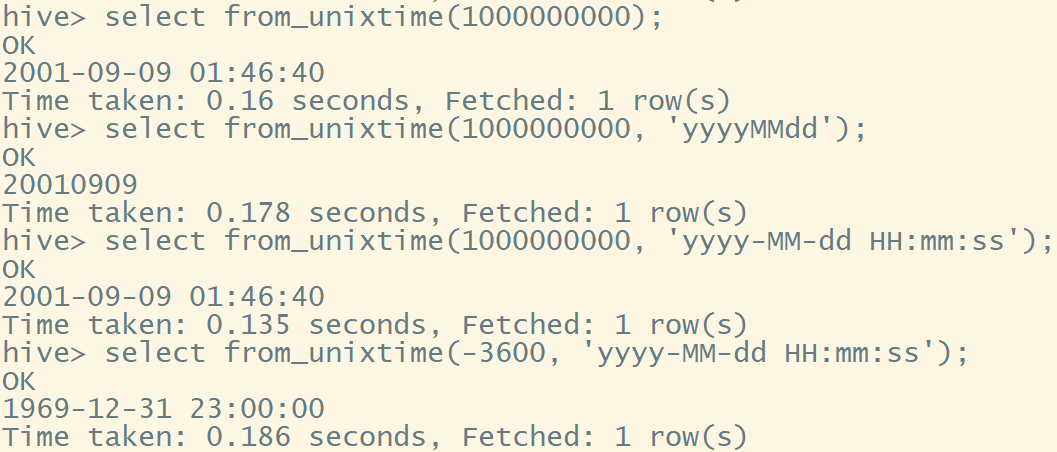
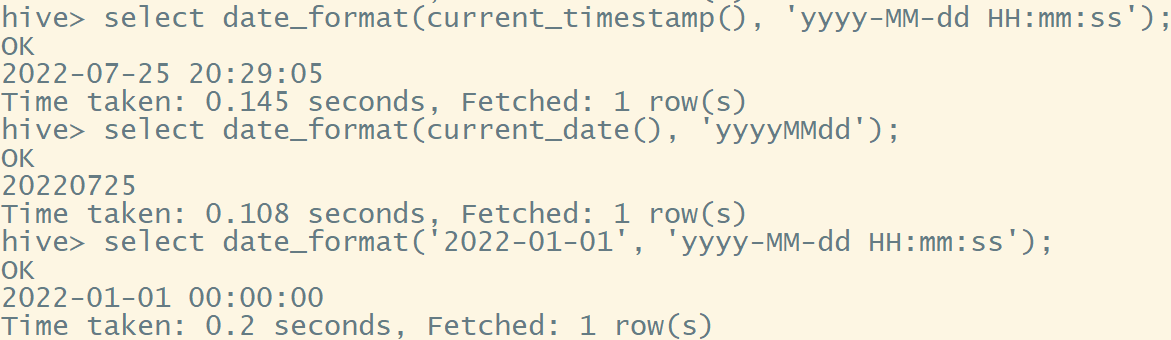
- 日期转字符串(格式化)函数:date_format()
select date_format(current_timestamp(), 'yyyy-MM-dd HH:mm:ss');
select date_format(current_date(), 'yyyyMMdd');
select date_format('2022-01-01', 'yyyy-MM-dd HH:mm:ss');
- 时间差计算函数:datediff()、months_between()
格式:datediff(date1, date2) -- 返回两日期相差天数:date1-date2
select datediff('2022-01-01', '2022-10-01');
select datediff('2022-01-01 00:00:00', '2022-01-01 23:59:59');
格式:moths_between(date1, date2) -- 返回两日期相差月数
select months_between('2022-07-20', '2022-07-01'); -- (20-01)/31
select months_between('2022-07-30', '2022-08-30'); -- (-31)/31
select months_between('2022-07-31', '2022-08-30'); -- (-30)/31
- 日期时间分量函数:year()、 month()、day()、hour()、minute()、second()
select year(current_timestamp());
select month(current_timestamp());
select day(current_timestamp());
select hour(current_timestamp());
select minute(current_timestamp());
select second(current_timestamp());
select dayofmonth(current_date()); -- 返回指定日期属于当月的第几天
select weekofyear(current_date()); -- 返回指定日期属于当年的第几周
- 日期定位函数:last_day()、next_day()
格式:last_day(date) -- 返回指定日期的月末日期
select last_day(current_date());
格式:next_day(date, 'monday') -- 返回指定日期的下周周几的日期
select next_day(current_date(), 'monday');
- 日期加减函数:date_add()、date_sub()、add_months()
格式:
date_add(date, num_days)
date_sub(date, num_days)
add_months(date, num_months)
select date_add(current_date(), 1);
select date_add(current_date(), -1);
select date_sub(current_date(), 10);
select add_months(current_date(), 1);
select add_months(current_date(), -1);
- trunc() 操作日期
select trunc(current_date(), 'YY'); -- 返回当年第一天日期
select trunc(current_date(), 'MM'); -- 返回当月第一天日期
select trunc(current_date(), 'Q'); -- 返回当季第一天日期
1.3 字符串函数
lower() -- 转小写
select lower('ABC');
upper() -- 转大写
select upper('abc');
length() -- 字符串长度
select length('abc');
concat() -- 字符串拼接
select concat("A", 'B');
concat_ws(regex,,,) -- 指定分隔符拼接
select concat_ws('-','a' ,'b','c');
substr(str,m,n) -- 截取字串,从 m 开始 一共 n
个
select substr('abcde',2);
select substr('abcde',2,2);
split(str,regex) -- 按指定分隔符切分字符串
select split("a-b-c-d-e-f","-");
1.4 类型转换函数
格式:cast(value as type)
select cast('10' as int) + 10;

1.5 数学函数
round() -- 四舍五入
select round(0.5);
select round(0.11111,2); -- 保留两位小数,也会四舍五入
select round(0.11999,2);
select round(123,-1); -- 四舍五入到十位
ceil() -- 向上取整
select ceil(1.1);
floor() --向下取整
select floor(1.1);
1.6 其他常用函数
nvl(value, default value) -- if value is null, return default value
isnull()
isnotnull()
case when ... then ... when ... then ... else ... end as col_name
coalesce(c1, c2, c3, ...) -- return first not null,如联系方式(手机、固话)有一即可
2.窗口函数 over()
窗口函数通常用于在查询详细数据的同时能够给出计算某种组下的统计数值:对表中的每条数据通过over()函数单独开了一个窗口(从开始位置到结束位置的全部记录)进行统计计算。
-- 语法
function() over(partition by col_name1 order by col_name2 rows between start_position and end_position)
-- function() 为可与 over() 一起使用的函数,如
聚合函数:sum()、count()、max()、min()、avg()
序列函数:ntile()、first_value()、last_value()、lag()、lead()
排名函数:rank()、dense_rank()、row_number()
其他:cume_dist()、percent_rank()
-- partition by
可理解为 group by,计算时按照指定列进行分组,窗口大小为同一个组的全部记录
-- order by
结合 partition by 使用时,就是对组内记录按照指定列进行排序;单独使用时,会对全部数据进行排序。
(在结合sum()、count()时会随行数增加而累加数值)
-- 窗口子句 rows between ... and ...
指定相对当前记录的计算范围:
PRECEDING 往前
FOLLOWING 往后
CURRENT ROW 当前行
UNBOUNDED 无边界
UNBOUNDED PRECEDING 往前无边界
UNBOUNDED FOLLOWING 往后无边界
sum(cost) over(partition by name order by date rows between 1 PRECEDING
and current row) -- 从前1行到当前行共2行进行sum
sum(cost) over(partition by name order by date rows between 1 PRECEDING
and 1 FOLLOWING) -- 从前1行到当前行到后1行共3行进行sum
sum(cost) over(partition by name order by date rows between UNBOUNDED
PRECEDING and current row ) -- 从起点(第一行)到当前行进行sum
sum(cost) over(partition by name order by date rows between current row and
UNBOUNDED FOLLOWING ) -- 从当前行到终点(最后一行)进行sum
3.序列函数(与窗口函数搭配使用)
NTILE(n) over() -- 将有序的数据记录平均分配至 n 个桶中,给桶中的每一行赋上桶号,如果不能平均分配,则优先分配编号小的桶,每个桶中放置记录数之差不超过1。
LAG(field, num, defaultvalue) over() --在一次查询中取出当前行的同一字段(field参数)的前面第num行的数据,如果没有用defaultvalue代替
LEAD(field, num, defaultvalue) over() --在一次查询中取出当前行的同一字段(field参数)的后面第num行的数据,如果没有用defaultvalue代替
FIRST_VALUE(col_name) over() -- 取所在分组截止当前行的第一行数据记录
LAST_VALUE(col_name) over() -- 取所在分组截止当前行的最后一行数据记录(默认范围为:rows between unbounded preceding and current row,就是取当前行)
4.排名函数
ROW_NUMBER() over() -- 从1开始,按照排序规则,给分组内的记录赋行号,无并列排名
RANK() over() -- 从1开始,按照排序规则,给分组内的记录排名,有并列排名,会留下空位(:1 2 2 4)
DENSE_RANK() over() -- 从1开始,按照排序规则,给分组内的记录排名,有并列排名,不会留下空位(:1 2 2 3)
5.自定义函数UDF,Java实现
1.继承 org.apache.hadoop.hive.ql.exec.UDF
2.编写 evaluate()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号