
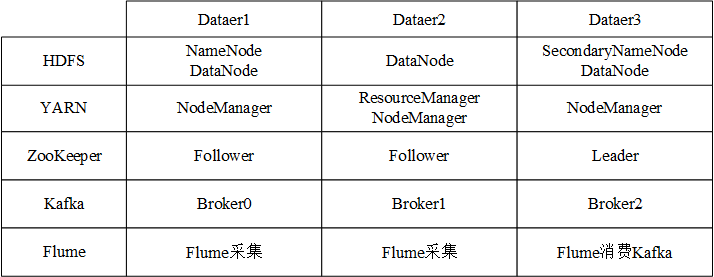
一、大数据环境准备
目录
1.Linux版本选择
2.修改ip
#查看ip
ip addr //hostname -I 仅查看ip地址
#进入配置文件
vi /etc/sysconfig/network-scripts/ifcfg-ens33
#修改
BOOTPROTO=static
ONBOOT=yes
#添加
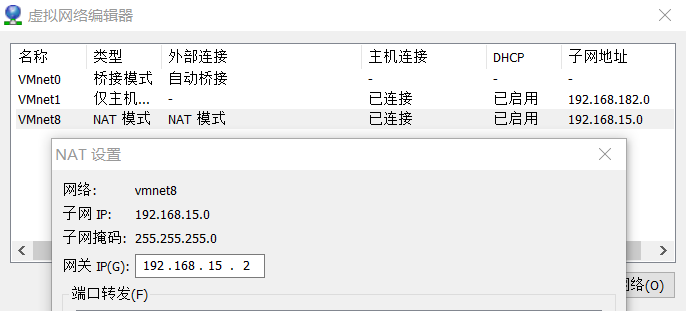
IPADDR=192.168.15.200
NETMASK=255.255.255.0
GATEWAY=192.168.15.2
DNS1=192.168.15.1
DNS2=8.8.8.8
#重启网络服务
systemctl restart network
注意ip信息需要与VM的虚拟网络编辑器中配置一致
3.修改主机名
hostnamectl set-hostname 新主机名 #重启生效
4.安装JDK
/opt/module :安装位置
/opt/software :存放软件包
#解压
tar -zxvf jdk-8u144-linux-x64.tar.gz -C /opt/module/
#修改环境
vi /etc/profile
#添加
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
#使生效
source /etc/profile
#测试
java -version
5.安装Hadoop
#解压
tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/
#修改环境
vi /etc/profile
#添加
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#使生效
source /etc/profile
#测试
hadoop version
配置SSH免密登录
#Dataer1 生成公钥和私钥
ssh-keygen -t rsa //三次回车
#将公钥拷贝到目标机器上,注意使用机器别名时需配置好/etc/hosts
ssh-copy-id dataer1
ssh-copy-id dataer2
ssh-copy-id dataer3
#在Dataer2,Dataer3上重复操作
编写集群分发脚本xsync
cd /usr/local/bin
vi xsync
#写入
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环
for((host=1; host<4; host++)); do
echo ------------------- dataer$host --------------
rsync -rvl $pdir/$fname $user@dataer$host:$pdir ##主要就是使用 rsync 命令进行循环
done
#修改脚本 xsync 具有执行权限
chmod 777 xsync
#调用
xsync /usr/local/bin
6.Hadoop集群配置
cd /opt/module/hadoop-2.7.7/etc/hadoop/
#配置core-site.xml
vi core-site.xml
#在<configuration>与</configuration>中间写入
<!-- 指定NameNode地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://dataer1:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.7/data/tmp</value>
</property>
#配置hadoop-env.sh
vi hadoop-env.sh
#在最后写入
export JAVA_HOME=/opt/module/jdk1.8.0_144
#配置hdfs-site.xml
vi hdfs-site.xml
#在<configuration>与</configuration>中间写入
<!-- 指定副本数量为3 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop.SecondaryNameNode -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>dataer3:50090</value>
</property>
#配置yarn-env.sh
vi yarn-env.sh
#在最后写入
export JAVA_HOME=/opt/module/jdk1.8.0_144
#配置yarn-site.xml
vi yarn-site.xml
#在<configuration>与</configuration>中间写入
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>dataer2</value>
</property>
#配置mapred-env.sh
vi mapred-env.sh
#在最后写入
export JAVA_HOME=/opt/module/jdk1.8.0_144
#配置mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
#在<configuration>与</configuration>中间写入
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
将Hadoop分发
xsync /opt/module/hadoop-2.7.7/
群起集群
#集群添加机器
vi /opt/module/hadoop-2.7.7/etc/hadoop/slaves
#写入
dataer1
dataer2
dataer3
#分发
xsync slaves
#启动集群,如果是第一次启动,需格式化NameNode
cd /opt/module/hadoop-2.7.7/bin
hdfs namenode -format
#启动hdfs
cd /opt/module/hadoop-2.7.7/sbin
start-dfs.sh
#在Dataer2上启动yarn
cd /opt/module/hadoop-2.7.7/sbin
start-yarn.sh
访问地址
NameNode
http://dataer1:50070/dfshealth.html#tab-overview
SecondaryNameNode
http://dataer3:50090/status.html
时间同步
选择Dataer1作为时间服务器,首先需安装ntp
yum -y install ntp
vi /etc/ntp.conf
#添加
restrict 192.168.15.0 mask 255.255.255.0 nomodify notrap
#注释掉
#server 0.centos.pool.ntp.org iburst
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
#添加
server 127.127.1.0
fudge 127.127.1.0 stratum 10 #当该节点丢失网络连接,依然可以采用本地时间作为时间服务器为集群中的其他节点提供时间同步
vi /etc/sysconfig/ntpd
#添加
SYNC_HWCLOCK=yes #让硬件时间与系统时间一起同步
service ntpd start
chkconfig ntpd on #开机自启
其他机器需要向Dataer1进行同步
crontab -e
*/10 * * * * /usr/sbin/ntpdate dataer1 #每10分钟同步一次
Hadoop集成lzo
Hadoop集成lzo(含maven安装) - ADataer - 博客园 (cnblogs.com)
7.安装ZooKeeper
cd /opt/software
tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
vi /etc/profile
#添加
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
source /etc/profile
cd zookeeper-3.4.10/conf/
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
#修改 需要 mkdir -p /opt/module/zkdata
dataDir=/opt/module/zkdata
#添加
server.1=dataer1:2888:3888
server.2=dataer2:2888:3888
server.3=dataer3:2888:3888
cd /opt/module/zkdata
echo 1 > myid
xsync /etc/profile
xsync /opt/module/zookeeper-3.4.10
xsync /opt/module/zkdata
#分别在Dataer2,Dataer3上 source /etc/profile 和 修改 myid
#三台机器上分别启动zk
cd /opt/module/zookeeper-3.4.10/bin
zkServer.sh start
8.安装Kafka
cd /opt/software
tar -zxvf kafka_2.11-0.11.0.0.tgz -C /opt/module/
cd /opt/module/kafka_2.11-0.11.0.0/
mkdir logs
cd /opt/module/kafka_2.11-0.11.0.0/conf
vi server.properties
#添加或修改
broker.id=0 //全局唯一编号,不能重复
delete.topic.enable=true
log.dirs=/opt/module/kafka_2.11-0.11.0.0/logs
zookeeper.connect=dataer1:2181,dataer2:2181,dataer3:2181
vi /etc/profile
#添加
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka_2.11-0.11.0.0
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
xsync /etc/profile
xsync /opt/module/kafka_2.11-0.11.0.0
分别在Dataer2,Dataer3上 source /etc/profile 和 修改 server.properties的broker.id
#群起脚本
vi /usr/local/kfstart
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if [ pcount == 0 ]; then
echo no args;
exit;
fi
#2 获取参数 start/stop
if [ "$1" == "start" ]
then
for i in dataer1 dataer2 dataer3
do
echo "========== $i start =========="
ssh $i '/opt/module/zookeeper-3.4.10/bin/zkServer.sh start'
ssh $i '/opt/module/kafka_2.11-0.11.0.0/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11.0.11.0.0/config/server.properties'
done
else
for i in dataer1 dataer2 dataer3
do
echo "========== $i stop =========="
ssh $i '/opt/module/kafka_2.11-0.11.0.0/bin/kafka-server-stop.sh -stop'
done
fi
chmod 777 kfstart
9.安装MySQL
#CentOS7自安装了mariadb 需卸载
rpm -qa | grep mariadb
rpm -e --nodeps mariadb-libs-5.5.68-1.el7.x86_64
#下载MySQL仓库并安装
wget https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
yum -y install mysql80-community-release-el7-3.noarch.rpm
#默认安装MySQL8,安装5.7 需要修改 /etc/yum.repos.d/mysql-community.repo

#安装MySQL数据库
yum -y install mysql-community-server --nogpgcheck
#开启MySQL服务
systemctl start mysqld.service
#查看mysql默认密码并登陆
grep 'temporary password' /var/log/mysqld.log
mysql -uroot -p
#修改密码
set password = password("****");
#修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
#忘记密码
systemctl stop mysqld.service
vi /etc/my.cnf
写入:skip-grant-tables
systemctl start mysqld.service
mysql -u root -p #直接回车就行
mysql> use mysql;
mysql> update mysql.user set authentication_string=password('new password') where user='root';
mysql> flush privileges;
mysql> exit;
将 /etc/my.cnf 中 skip-grant-tables 删除,重启服务即可
10.安装Hive
tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
vi /etc/profile
#添加
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
#初始化元数据库
bin/schematool -dbType derby -initSchema
Hive元数据配置到MySQL
Hive元数据配置到MySQL - ADataer - 博客园 (cnblogs.com)
Hive集成tez引擎
Hive集成tez引擎 - ADataer - 博客园 (cnblogs.com)
11.安装Flume
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
mv apache-flume-1.7.0-bin flume
cd flume/conf/
vi flume-env.sh
#添加
export JAVA_HOME=/opt/module/jdk1.8.0_144
#分发至Dataer2 Dataer3
12.安装Sqoop
tar -zxvf /opt/software/sqoop-1.4.6.bin__hadoop-2.0.4-alpha.tar.gz -C /opt/module/
mv sqoop-1.4.6.bin__hadoop-2.0.4-alpha/ sqoop
cd sqoop/conf/
mv sqoop-env-template.sh sqoop-env.sh
vi sqoop-env.sh
export HADOOP_COMMON_HOME=/opt/module/hadoop-2.7.7
export HADOOP_MAPRED_HOME=/opt/module/hadoop-2.7.7
export HBASE_HOME=/opt/module/hbase
export HIVE_HOME=/opt/module/hive
export ZOOKEEPER_HOME=/opt/module/zookeeper-3.4.10
export ZOOCFGDIR=/opt/module/zookeeper-3.4.10/conf
tar -zxvf /opt/software/mysql-connector-java-5.1.27.tar.gz
cp /opt/software/mysql-connector-java-5.1.27/mysql-connector-java-5.1.27-bin.jar /opt/module/sqoop/lib
cd /opt/module/sqoop
#测试连接MySQL
bin/sqoop list-databases --connect jdbc:mysql://dataer1:3306/ --username root --password ****
13.安装HBase
tar -zxvf /opt/software/hbase-1.3.1-bin.tar.gz -C /opt/module/
cd /opt/module/hbase-1.3.1/conf
vim hbase-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
export HBASE_MANAGES_ZK=false #启动HBase时不启动zookeeper
vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://dataer1:9000/HBase</value> #HMaster
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 0.98 后的新变动,之前版本没有.port,默认端口为 60000 -->
<property>
<name>hbase.master.port</name>
<value>16000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>dataer1,dataer2,dataer3</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/module/zookeeper-3.4.10/zkdata</value>
</property>
</configuration>
vim regionservers #HRegionServer
dataer1
dataer2
dataer3
#软连接 hadoop 配置文件到 HBase
ln -s /opt/module/hadoop-2.7.7/etc/hadoop/core-site.xml /opt/module/hbase-1.3.1/conf/core-site.xml
ln -s /opt/module/hadoop-2.7.7/etc/hadoop/hdfs-site.xml /opt/module/hbase-1.3.1/conf/hdfs-site.xml
#分发
xsync /opt/module/hbase-1.3.1
#启动/停止HBase
bin/start-hbase.sh
bin/stop-hbase.sh
HBase管理页面
dataer1:16010
14.安装Spark(yarn模式)
tar -zxvf /opt/software/spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module
mv spark-3.0.0-bin-hadoop3.2 spark-yarn
#修改 hadoop 配置文件 yarn-site.xml
vi /opt/module/hadoop-2.7.7/etc/hadoop/yarn-site.xml
#添加以下配置
<!--是否启动一个线程检查每个任务正使用的物理内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认
是 true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
#分发
xsync /opt/module/hadoop-2.7.7/etc/hadoop/yarn-site.xml
#修改 spark-env.sh,添加
export JAVA_HOME=/opt/module/jdk1.8.0_144
YARN_CONF_DIR=/opt/module/hadoop-2.7.7/etc/hadoop
#启动 Hadoop、yarn
#提交任务
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10
配置历史服务器
cd /opt/module/spark-yarn/conf
mv spark-defaults.conf.template spark-defaults.conf
vi spark-defaults.conf
#添加
spark.eventLog.enabled true
spark.eventLog.dir hdfs://dataer1:9000/directory (需在hdfs上新建该目录)
spark.yarn.historyServer.address=dataer1:18080
spark.history.ui.port=18080
vi spark-env.sh
#添加
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080 #WEB 访问的端口号为 18080
-Dspark.history.fs.logDirectory=hdfs://dataer1:9000/directory
-Dspark.history.retainedApplications=30" #保存 Application 历史记录的个数
#启动历史服务器
./sbin/start-history-server.sh
#提交应用
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn --deploy-mode client \
./examples/jars/spark-examples_2.12-3.0.0.jar \
10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号