数据库相关知识
1.数据库事务ACID特性
数据库事务正确执行的四个基础要素是原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。
- 原子性:是指事务包含的所有操作要么全部成功,要么全部失败回滚,不可能停滞在中间某个环节。事务在执行过程中发生错误,会被回滚到事务开始前的状态,就像这个事务从来没有被执行过一样。
- 一致性:是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
拿转账来说,假设用户A和用户B两者的钱加起来一共是5000,那么不管A和B之间如何转账,转几次账,事务结束后两个用户的钱相加起来应该还得是5000,这就是事务的一致性。
-
隔离性:两个事务之间的隔离程度
-
持久性
持久性是指一个事务一旦被提交了,那么对数据库中的数据的改变就是永久性的,即便是在数据库系统遇到故障的情况下也不会丢失提交事务的操作。
2 丢失更新
在互联网中存在着抢购、秒杀等高并发环境,使得数据库在一个多事务的环境中运行,多个事务的并发会产生一系列的问题,主要的问题之一就是丢失更新,一般而言存在两类丢失更新。
假设一个场景,一个账户存在互联网消费和刷卡消费两种形式,而一对夫妻共用这个账户。老公喜欢刷卡消费,老婆喜欢互联网消费,那么可能产生如下表所示场景
表1 第一类丢失更新
|
时间 |
事务一(老公) |
事务二(老婆) |
|
T1 |
查询账户余额为10000元 |
|
|
T2 |
|
查询账户余额为10000元 |
|
T3 |
|
网购1000元 |
|
T4 |
请客吃饭消费1000元 |
|
|
T5 |
提交事务成功,余额9000元 |
|
|
T6 |
|
取消购买,回滚事务到T2时刻,余额10000元 |
整个过程只有老公消费1000元,而在最后的T6时刻,老婆回滚事务,却恢复了原来的初始值10000元,这显然不符合事实。这样的两个事务并发,一个回滚、一个提交成功导致不一致,称之为第一类丢失更新。大部分数据库(包括Mysql和Oracle)基本都已经消灭了这类丢失更新。
第二类丢失更新是我们真正需要关注的内容,还是上面的例子,如表2所示
表2 第二类丢失更新
|
时间 |
事务一(老公) |
事务二(老婆) |
|
T1 |
查询账户余额为10000元 |
|
|
T2 |
|
查询账户余额为10000元 |
|
T3 |
|
网购1000元 |
|
T4 |
请客吃饭消费1000元 |
|
|
T5 |
提交事务成功,余额9000元 |
|
|
T6 |
|
提交事务,根据之前余额10000元,扣减1000元后,余额为9000元 |
整个过程存在两笔交易,一笔是老公的请客吃饭,一笔是老婆的网购,两者都提交了事务,由于在不同的事务中,无法探知其它事务的操作,导致两者提交后,余额都为9000元,而实际正确的应为8000元,这就是第二类丢失更新。为了克服事务之间协助的一致性,数据库标准规范中定义了事务之间的隔离级别,来在不同程度上减少出现丢失更新的可能性---->数据库隔离级别。
隔离级别
隔离级别可以在不同程度上减少丢失更新,按照SQL的标准规范,把隔离级别定义为4层,分别是:脏读(dirty read)、读/写提交(read commit)、可重复读(repeatable read)和序列化(serializable)。
脏读是最低的隔离级别,允许一个事务去读取另一个事务中未提交的数据。
表3 脏读
|
时间 |
事务一(老公) |
事务二(老婆) |
备注 |
|
T1 |
查询余额10000元 |
|
|
|
T2 |
|
查询余额10000元 |
|
|
T3 |
|
网购1000元,余额9000元 |
|
|
T4 |
请客吃饭消费1000元,余额8000元 |
|
读取到事务二,未提交余额为9000元,所以余额为8000元 |
|
T5 |
提交事务 |
|
余额为8000元 |
|
T6 |
|
回滚事务 |
由于第一类丢失更新已经克服,所以余额为错误的8000元 |
由于在T3时刻老婆启动了消费,导致余额为9000元,老公在T4时刻消费,因为用了脏读,所以能够读取老婆消费的余额(事务二未提交的)为9000元,这样余额就为8000元了,于是T5时刻老公提价事务,余额变为了8000元,老婆在T6时刻回滚事务,由于第一类丢失更新已经克服,所以余额为错误的8000元,显然这是一个错误的余额,产生这个错误的根源来自于T4时刻,也就是事务一读取到事务二未提交的事务,这样的场景称之为脏读。
为了克服脏读,SQL标准提出了第二个隔离级别----读/写提交。所谓读写提交,就是说一个事务只能读取另一个事务已经提交的数据。
表4 读/写提交
|
时间 |
事务一(老公) |
事务二(老婆) |
备注 |
|
T1 |
查询余额10000元 |
|
|
|
T2 |
|
查询余额10000元 |
|
|
T3 |
|
网购1000元,余额9000元 |
|
|
T4 |
请客吃饭消费1000元,余额9000元 |
|
由于事务二的余额未提交,采取读/写提交时不能读出,所以余额为9000元 |
|
T5 |
提交事务 |
|
余额为9000元 |
|
T6 |
|
回滚事务 |
由于第一类丢失更新已经克服,所以余额依旧为正确的9000元 |
在T3时刻由于事务采取读/写提交的隔离级别,所以老公无法读取老婆未提交的9000元余额,他只能读取到10000元,所以在消费后余额依旧为9000元。T5时刻提交事务,而T6时刻老婆回滚事务,所以结果为正确的9000元,这样就消除了脏读带来的问题,但是也会引发其它问题,如下表所示。
表5 不可重复读
|
时间 |
事务一(老公) |
事务二(老婆) |
备注 |
|
T1 |
查询余额10000元 |
|
|
|
T2 |
|
查询余额10000元 |
|
|
T3 |
|
网购1000元,余额9000元 |
|
|
T4 |
请客吃饭消费2000元,余额8000元 |
|
由于采取读/写提交,不能读取事务二中未提交的余额9000元 |
|
T5 |
|
继续购物8000元,余额1000元 |
由于采取读/写提交,不能读取事务一中未提交的余额8000元 |
|
T6 |
|
提交事务,余额1000元 |
老婆提交事务,余额更新为1000元 |
|
T7 |
提交事务发现余额为1000元,不足以买单 |
由于采取读/写提交,因此此时事务一可以知道余额不足 |
由于T7时刻事务一知道事务二提交的结果----余额为1000元,导致老公无钱买单的尴尬。对于老公而言,他并不知道老婆做了什么事情,但是账户余额却莫名其妙地从10000元变为了1000元,对他来说,账户余额是不能重复读取的,而是一个会变化的值,这样的场景称之为不可重复读(unrepeatable read),这是读/写提交存在的问题。
为了克服不可重复读带来的错误,SQL标准又提出了一个可重复读的隔离级别来解决问题。注意,可重复读针对的是数据库同一条记录而言的,换句话说,可重复读会使得同一条记录的读/写按照一个序列化进行操作,不会产生交叉情况,这样就能保证同一条数据的一致性,进而保证上述场景的正确性。但是由于数据库并不是只能针对一条数据进行读/写操作,在很多场景,数据库需要同时对多条记录进行读/写,这个时候会产生下面的情况。如下表所示
表6 幻读
|
时间 |
事务一(老公) |
事务二(老婆) |
备注 |
|
T1 |
|
查询消费记录为10条,准备打印 |
初始状态 |
|
T2 |
启用消费一笔 |
|
|
|
T3 |
提价事务 |
|
|
|
T4 |
|
打印消费记录得到11条 |
老婆发现打印了11条消费记录,比查询的10条多了一条。她会认为这条是多余不存在的,这样的场景称之为幻读。 |
老婆在T1查询得到10条记录,到T4打印记录时,并不知道老公在T2和T3时刻进行了消费,导致多一条(可重复读针对的是同一条记录,而这里不是同一条记录)消费记录的产生,她会质疑这条多出来的记录是不是幻读出来的,这样的场景称之为幻读。
为了克服幻读,SQL标准又提出了序列化的隔离级别。它是一种让SQL按照顺序读/写的方式,能够消除数据库事务之间并发产生数据不一致的问题。
表7 各类隔离级别和产生的现象
|
隔离级别 |
脏读 |
不可重复读 |
幻读 |
|
脏读 |
√ |
√ |
√ |
|
读/写提交 |
× |
√ |
√ |
|
可重复读 |
× |
× |
√ |
|
序列化 |
× |
× |
× |
MySQL的事务和MVCC
MySQL中并不是所有的存储引擎都支持事务的功能,目前只有InnoDB和NDB存储引擎支持事务,MyISAM不支持事务。一致性是事务的最终目标,由原子性,隔离性即持久性共同保证。原子性通过undo_log日志实现。持久性由redo_log重做日志实现。而隔离性主要由MVCC机制和锁机制实现。
事务的隔离性是通过锁和MVCC共同实现的。InnoDB与锁配合,同时采用另一种事务隔离性的实现机制MVCC,即 Multi-VersionedConcurrencyControl 多版本并发控制,用来解决脏读、不可重复读等事务之间读写问题,MVCC在某些场景中替代了低效的锁,在保证了隔离性的基础上,提升了读取效率和并发性。
MVCC
MVCC(Multi-Version Concurrency Control),即多版本并发控制,指的是在使用READ COMMITTED和 REPEATABLE READ 这两种隔离级别的事务在执行普通的 SELECT 操作时,访问记录的版本链的过程。通过 MVCC,可以使不同事务的读-写、写-读操作并发执行,从而提升系统性能。
版本链
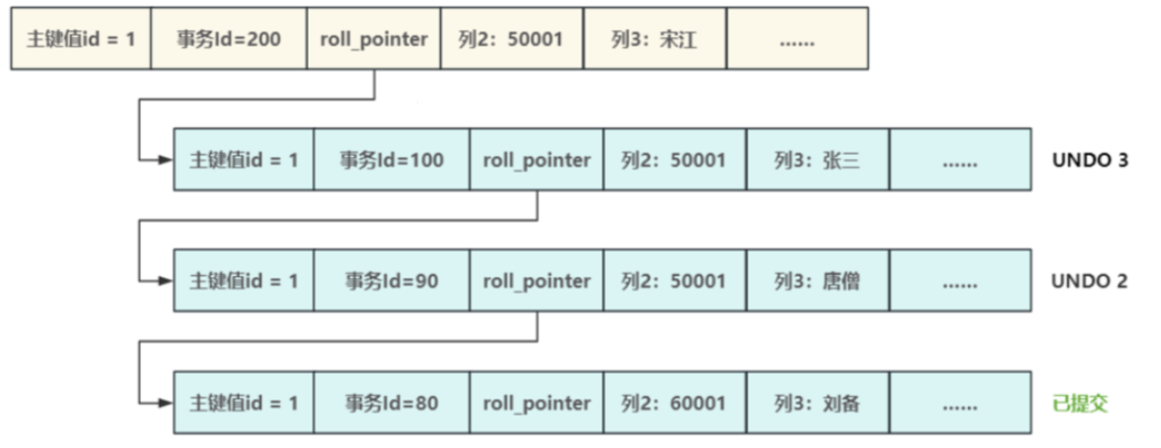
对于使用 InnoDB 存储引擎的表来说,它的聚簇索引记录中都包含两个必要的隐藏列(row_id 并不是必要的,当创建的表中有主键或者非 NULL 的 UNIQUE 键时都不会包含 row_id 列)
trx_id:每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务 id 赋值给trx_id隐藏列。roll_pointer:每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
MySQL中,每次对记录进行改动,都会记录一条 undo 日志,每条 undo 日志也都有一个 roll_pointer 属性(INSERT 操作对应的 undo 日志没有该属性,因为该记录并没有更早的版本),可以将这些 undo 日志都连起来,串成一个链表,形成「版本链」,如下图所示。
ReadView的作用
MySQL 中引入 ReadView的概念,来解决「当使用 READ COMMITTED 和 REPEATABLE READ 隔离级别的事务时,普通的 SELECT 查询时如何判断版本链中的哪个版本是当前事务可见的」问题。
什么是ReadView
对于使用 READ COMMITTED 和 REPEATABLE READ 隔离级别的事务来说,都必须保证读到已经提交了的事务修改过的记录,也就是说假如另一个事务已经修改了记录但是尚未提交,是不能直接读取最新版本的记录的。因此,核心问题就是需要判断一下版本链中的哪个版本是当前事务可见的。
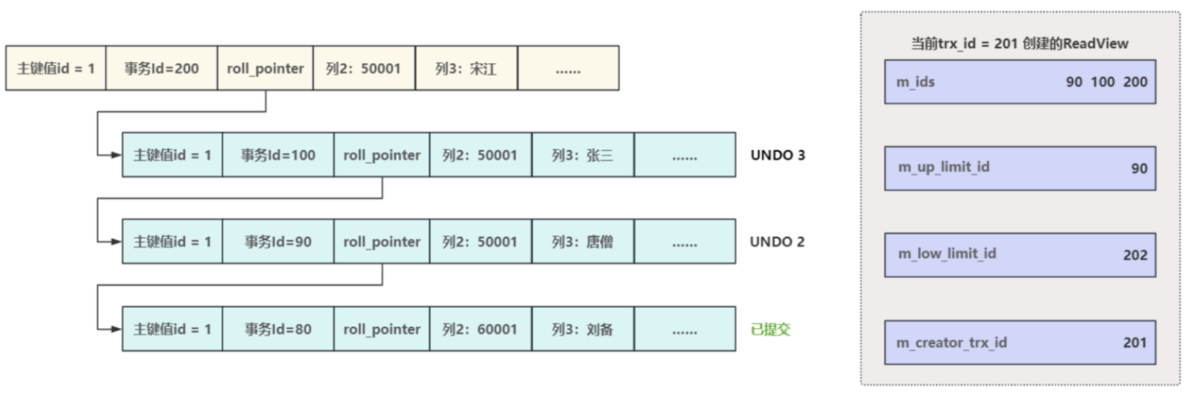
为此,引入了一个 ReadView 的概念,ReadView 中主要包含 4 个比较重要的内容
m_ids:表示在生成 ReadView 时当前系统中活跃的读写事务的事务 id 列表。min_trx_id:表示在生成 ReadView 时当前系统中活跃的读写事务中最小的事务 id,也就是m_ids中的最小值。max_trx_id:表示生成 ReadView 时系统中应该分配给下一个事务的 id 值。- creator_trx_id:创建当前 ReadView 的事务 ld,当前事务 ld
ReadView的使用
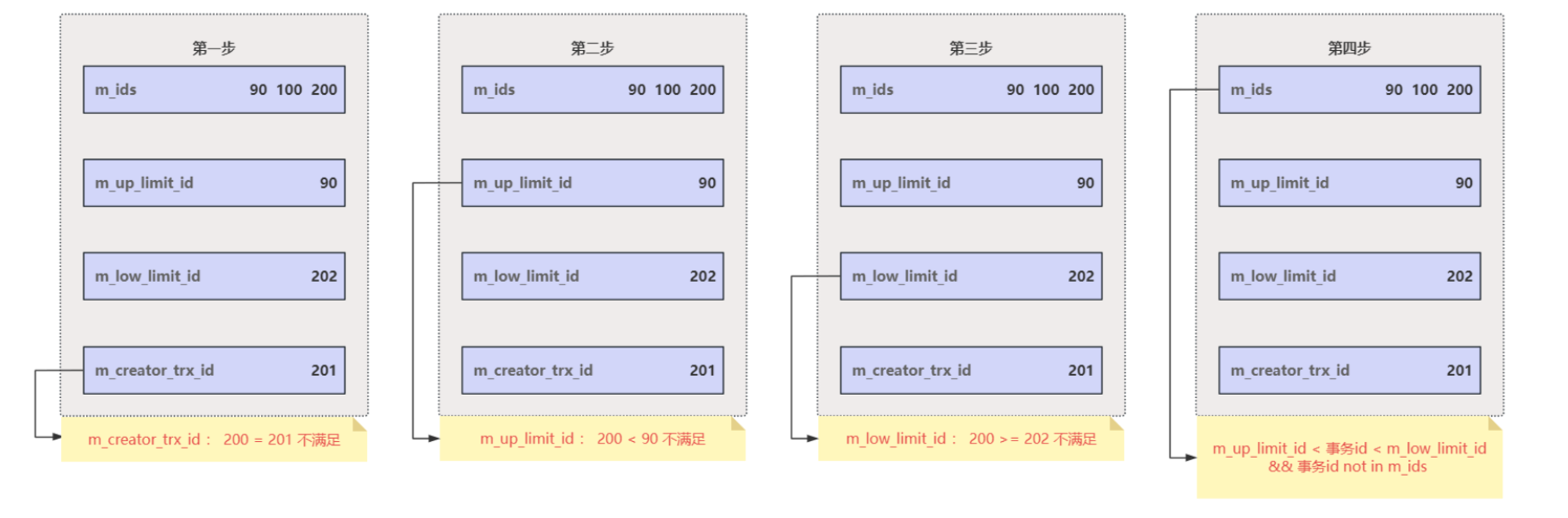
有了这个 ReadView,这样在访问某条记录时,只需要按照下边的步骤判断记录的某个版本是否可见
-
如果被访问版本的
trx_id属性值 等于(=)ReadView 中的creator_trx_id值,意味着当前事务在访问它自己修改过的记录,所以该版本可以被当前事务访问。 -
如果
trx_id小于min_trx_id,表明生成该版本的事务在当前事务生成 ReadView 前已经提交,所以该版本可以被当前事务访问。 -
如果
trx_id大于等于min_trx_id,表明生成该版本的事务在当前事务生成 ReadView 后才开启,所以该版本不可以被当前事务访问。 -
如果
trx_id属性值在min_trx_id和max_trx_id之间,那就需要判断一下trx_id属性值是不是在m_ids列表中。 - 如果在,说明创建 ReadView 时生成该版本的事务还是活跃的,该版本不可以被访问;
- 如果不在,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
ReadView的生成时机
在 MySQL 中,READ COMMITTED 和 REPEATABLE READ 隔离级别的的一个非常大的区别就是它们生成 ReadView 的时机不同
READ COMMITTED:每次读取数据前都生成一个 ReadViewREPEATABLE READ:在第一次读取数据时生成一个 ReadView
MySQL中默认使用REPEATABLE-READ的事务隔离级别,可以避免脏读,不可重复读但是仍然会出现幻读现象。确切的说,MySQL的InnoDB可以在一定程度上防止幻读,但是不能完全避免。
Oracle默认使用READ COMMITTED事务隔离级别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号