

JDBC
JDBC是访问关系型数据库的java API.JDBC给程序员提供访问和操纵众多关系型数据库的一个统一接口。使用JDBC API,程序员可以用java以一种用户友好的接口执行SQL语句、获取结果以及显示数据,并且操纵数据。JDBC API还可用于分布式、异构环境中的多种数据源之间实现交互。
JDBC API是一组规范(java接口和类的集合)用于编写和访问操作关系数据库的Java程序。JDBC驱动程序起一个接口的作用,它使JDBC与具体数据库之间的通信灵活方便(实现了API的规范)。它由具体的数据库供应商提供。下图显示了java程序、JDBC API和JDBC驱动程序和关系数据库之间的关系。
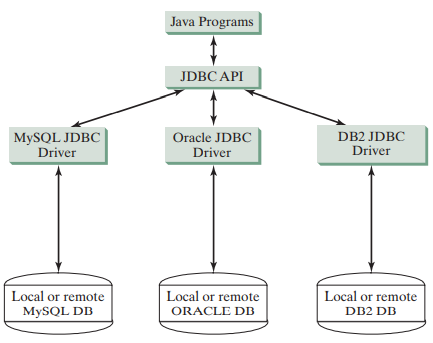
使用JDBC开发数据库应用程序
准备mysql结构数据(学员选课系统)

CREATE DATABASE avatar; -- 切换数据库 USE avatar; /* 学员选课系统 1、课程实体 课程编号(主键) int 自增长 课程名称 varchar(20) 学分 int 课程简介 varchar(50) 2、学员信息 ssn char(9) primary key, stu_name varchar(20) not null, stu_gender enum('MALE','FEMALE') default 'MALE', born_date date, address varchar(60), phone varchar(15) 3、成绩实体 ssn char(9), course_id int, score float(5,2), sc_date date, foreign key(ssn) references student(ssn), foreign key(course_id) references course(course_id), primary key(ssn,course_id) */ CREATE TABLE course( course_id INT PRIMARY KEY AUTO_INCREMENT, course_name VARCHAR(20) NOT NULL, credit INT, course_intro VARCHAR(50) ); CREATE TABLE student( ssn CHAR(9) PRIMARY KEY, stu_name VARCHAR(20) NOT NULL, stu_gender ENUM('MALE','FEMALE') DEFAULT 'MALE', born_date DATE, address VARCHAR(60), phone VARCHAR(15) ); CREATE TABLE score( ssn CHAR(9), course_id INT, score FLOAT(5,2), sc_date DATE, FOREIGN KEY(ssn) REFERENCES student(ssn), FOREIGN KEY(course_id) REFERENCES course(course_id), PRIMARY KEY(ssn,course_id) );
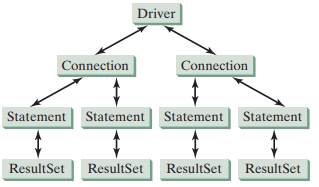 使用java开发任何数据库应用程序都需要4个主要接口:Driver、Connection、Statement和ResultSet。这些接口定义了使用SQL访问数据库的一般架构。JDBC API定义了这些接口。JDBC驱动程序开发商为这些接口提供实现。程序猿使用这些接口。JDBC应用程序使用Driver接口加载一个合适的驱动程序,使用Connection接口连接到数据库,使用Statement接口创建和执行SQL语句,如果语句返回结果,使用ResultSet接口处理结果。
使用java开发任何数据库应用程序都需要4个主要接口:Driver、Connection、Statement和ResultSet。这些接口定义了使用SQL访问数据库的一般架构。JDBC API定义了这些接口。JDBC驱动程序开发商为这些接口提供实现。程序猿使用这些接口。JDBC应用程序使用Driver接口加载一个合适的驱动程序,使用Connection接口连接到数据库,使用Statement接口创建和执行SQL语句,如果语句返回结果,使用ResultSet接口处理结果。
JDBC接口和类是开发java数据库程序的构建模块。开发jdbc程序的典型步骤为:
1、加载驱动程序
在连接到数据库之前,需要加载一个合适的驱动程序
Class.forName("com.mysql.cj.jdbc.Driver");
驱动程序是一个实现接口java.sql.Driver的具体类。java6支持驱动程序的自动加载,因此不需要显示的加载它们,但是并不是所有的驱动程序都有这个特性。为安全起见,应该显式加载驱动程序。
2、建立连接
为了连接到一个数据库,需要使用DriverManager类中的静态方法getConnection(url,username,password).
Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.254.188:3306/avatar", "peppa", "peppa");
其中,url是数据库在Internet上的唯一标识符,username为用户名,password为密码。
| 数据库 | url模式 |
| Mysql | jdbc:mysql://hostname:port/dbname |
| Oracle | jdbc:oracle:thin:@hostname:port:oracleDBSID |
3、创建语句
如果把一个Connection对象想象成一条连接程序和数据库的缆道,那么Statement对象可以看作一辆缆车,它为数据库传输SQL语句用于执行,并把运行结果返回给程序。一旦创建了Connection对象,就可以创建执行SQL语句。
Statement stat = conn.createStatement();
4、执行语句
- execute(sql):可以执行任意类型sql语句,一般比较复杂,很少使用
- executeUpdate(sql):执行DML语句(insert、update、delete),返回的是影响行数
- executeQuery(sql):执行DQL语句(select),返回查询结果----ResultSet
5、处理结果ResultSet
结果集ResultSet维护SQL语句的查询结果,该结果的当前行可以获得。当前行的初始位置是null。可以使用next方法移动到下一行,可以使用各种getter方法从当前行获取值。
6、回收数据库(释放)资源
关闭连接并释放与连接有关的资源,可以使用try-with-resource语法。
package edu.uestc.avatar.sql; import java.sql.Connection; import java.sql.DriverManager; import java.sql.SQLException; import java.sql.Statement; public class SimpleJdbc { public static void addCourse() throws ClassNotFoundException, SQLException { //1、加载驱动程序 Class.forName("com.mysql.cj.jdbc.Driver"); //2、建立连接 Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.254.188:3306/avatar", "peppa", "peppa"); //3、创建语句 Statement stat = conn.createStatement(); //4、发送并执行sql,返回直接结果 String sql = "insert into course(course_name,credit,course_intro) values ('Linux',10,'Linux必知必会')"; int ret = stat.executeUpdate(sql); //5、处理结果 if(ret >= 1) System.out.println("课程添加成功"); //6、回收数据库(释放)资源 conn.close();//bug:应该确保资源的释放 } public static void main(String[] args) throws ClassNotFoundException, SQLException { addCourse(); } }
SQL注入问题
CREATE TABLE `user`( id INT PRIMARY KEY AUTO_INCREMENT, username VARCHAR(12) NOT NULL UNIQUE, `password` VARCHAR(36) NOT NULL ); INSERT INTO `user` VALUES(DEFAULT,'peppa','peppa'), (DEFAULT,'suzy','suzy'),(DEFAULT,'emily','emily');
public static void find(String username,String password) throws Exception{ //java6支持驱动程序的自动加载,因此不需要显示的加载它们,但是并不是所有的驱动程序都有这个特性。为安全起见,应该显式加载驱动程序 Class.forName("com.mysql.cj.jdbc.Driver"); //2、获取连接对象 Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.254.188:3306/avatar", "peppa", "peppa"); //3、通过Connection创建语句对象 Statement stat = conn.createStatement(); String sql = "select id,username,password from user where username='" + username + "' and password='" + password + "'"; ResultSet rs = stat.executeQuery(sql); while(rs.next()) { System.out.println("user id:" + rs.getInt("id")); System.out.println("username:" + rs.getString("username")); System.out.println("password:" + rs.getString("password")); System.out.println("============================================="); } }
这个程序有一个安全漏洞。如果在password字段中输入1' or true or '1就会得到结果,这是因为查询字符串变成了:
SELECT id,username,PASSWORD FROM USER WHERE username='candy' AND PASSWORD='1' OR TRUE OR '1'
可以使用PreparedStatement接口来避免这个问题。
PreparedStatement
一旦建立了一个到特定数据库的连接,就可以用这个连接把程序的SQL语句发送到数据库。Statement接口用于执行不含参数的静态SQL语句。PreparedStatement接口继承自Statement接口,用于执行含有或不含参数的预编译SQL语句。由于SQL语句是预编译的,所以重复执行它们时效率较高。
public static void login(String username, String password) { String sql = "select id,username, password from user where username=? and password=?"; try (Connection conn = DriverManager.getConnection("jdbc:mysql://192.168.254.188:3306/avatar","peppa","peppa")){ Class.forName("com.mysql.cj.jdbc.Driver"); //创建预编译语句对象, PreparedStatement ptst = conn.prepareStatement(sql); //处理预编译语句的参数 ptst.setString(1, username); ptst.setString(2, password); //执行sql语句 ResultSet rs = ptst.executeQuery(); if(rs.next()) { System.out.printf("登录成功,用户名为:%s;密码为:%s", rs.getString("username"), rs.getString("password")); } } catch (ClassNotFoundException | SQLException e) { e.printStackTrace(); } }
这个查询语句有两个问号用作参数的占位符表示用户名和密码的值。PreparedStatement提供了设置参数的方法。总体来看,PreparedStatement比Statement多了三个好处:
- PreparedStatement预编译SQL语句,性能更好
- PreparedStatement无须拼接SQL语句,编程更简单
- PreparedStatement可以防止SQL注入,安全性更好
规范和封装JDBC代码
目前存在的问题:
1、每执行一个JDBC方法都要注册驱动,驱动应该只注册一次且在系统启动时注册
2、数据库连接属性是硬编码在代码中,应该可配置完成解耦
3、像公共的获取连接及释放资源(可使用try-with-resource语法)应该抽取为公共的方法,避免在方法中键入相关属性
解决方案:提供一个JDBC的助手类
package edu.uestc.avatar.commons; import java.io.IOException; import java.io.InputStream; import java.sql.Connection; import java.sql.DriverManager; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; /** * jdbc助手(工具类) * */ public class JdbcHelper { //数据库驱动类 private static String driverClassName; //数据库唯一标识符 private static String url; //数据库用户账户名 private static String username; //账户密码 private static String password; //private static JdbcHelper instance = new JdbcHelper(); private static JdbcHelper instance; /** * 完成JDBC相关初始化,只初始化一次 */ static { try { //初始化类变量信息,读取类路径下的jdbc.properties文件 Properties prop = new Properties(); //通过类加载器读取位于classPath下的文件,将其转为InputStream InputStream in = JdbcHelper.class.getClassLoader().getResourceAsStream("jdbc.properties"); prop.load(in); driverClassName = prop.getProperty("driverClassName"); url = prop.getProperty("url"); username = prop.getProperty("username"); password = prop.getProperty("password"); //加载数据库驱动 Class.forName(driverClassName); } catch (ClassNotFoundException | IOException e) { e.printStackTrace(); } } /** * 单例模式: * 1、构造方法私有化,外部不能创建其实例 * 2、内部创建其唯一的实例对外提供 * 饥汉模式:开始就创建其实例 * 懒汉模式:开始不创建,在系统第一次获取该实例进行创建 */ private JdbcHelper() { } /** * 获取数据库连接对象 * @return Connection * @throws SQLException */ public Connection getConnection() throws SQLException { return DriverManager.getConnection(url, username, password); } /** * 释放jdbc相关资源 * @param rs 结果集 * @param stat 语句对象 * @param conn 连接对象 */ public void free(ResultSet rs, Statement stat, Connection conn) { try { if(rs != null) rs.close(); } catch (SQLException e) { e.printStackTrace(); } finally { try { if(stat != null) stat.close(); } catch (SQLException e) { e.printStackTrace(); } finally { try { if(conn != null) conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } /** * 提供一个公共的静态方法,对外返回该类的唯一实例 * @return 该类的唯一实例 */ // public static JdbcHelper getInstance() { // return instance; // } // public synchronized static JdbcHelper getInstance() { // if(instance == null) { // instance = new JdbcHelper(); // } // return instance; // } public static JdbcHelper getInstance() { if(instance == null) { synchronized (JdbcHelper.class) { if(instance == null) //双重检查 instance = new JdbcHelper(); } } return instance; } }
CallableStatement
可以使用CallableStatement执行SQL存储过程。存储过程可能会有IN、OUT或IN OUT参数。调用过程时,参数IN接收传递给存储过程的值。在过程结束后,参数OUT返回一个值,但是当调用过程时,它不包含任何值。当过程被调用时,IN OUT参数包含传递给过程的值,在它完成后返回一个值。在Mysql数据库中创建一个存储过程
delimiter // create procedure compute_average(in p_ssn char(9),out p_score float(5,2)) begin select avg(score) into p_score from score where ssn = p_ssn; end; //
可以使用Connection接口中的prepareCall()方法来创建CallableStatement对象
var call = conn.prepareCall("{call compute_average(?,?)}");
{call compute_average(?,?)}指的是SQL转义语法,它通知驱动程序其中的代码应该被不同处理。驱动程序解析转义语法,并且将它翻译成数据库可以理解的代码。
compute_average为存储过程名称。
CallableStatement继承自PreparedStatement。此外,CallableStatement接口提供了注册OUT参数的方法以及从OUT参数获取值的方法。
public class CallableStatementDemo { public static void main(String[] args) { try(var conn = JdbcHelper.getInstance().getConnection()){ /* * call compute_average(?,?)是SQL转义语法 */ var call = conn.prepareCall("{call compute_average(?,?)}"); call.setString(1, "201810001"); //输出参数注册 call.registerOutParameter(2, Types.FLOAT); //执行存储过程 call.execute(); System.out.println(call.getFloat(2)); }catch (SQLException e) { e.printStackTrace(); } } }
管理结果集
JDBC使用ResultSet来封装执行查询得到的查询结果。然后通过移动ResultSet的记录指针来取出结果集的内容,除此之外,JDBC还允许通过ResultSet来更新记录。
可滚动可更新的结果集。
package edu.uestc.monster; import java.sql.ResultSet; import java.sql.SQLException; import edu.uestc.monster.commons.JdbcHelper; /** * ResultSet来更新记录 * prepareStatement(String sql, int resultSetType,int resultSetConcurrency) * resultSetType: * ResultSet.TYPE_FORWARD_ONLY:结果集不能滚动(默认值) * ResultSet.TYPE_SCROLL_INSENSITIVE:结果集可以滚动,但是对数据库变化不敏感 * ResultSet.TYPE_SCROLL_SENSITIVE:结果集可以滚动,对数据库变化敏感 * resultSetConcurrency * ResultSet.CONCUR_READ_ONLY:只读,结果集不能更新(默认值) * ResultSet.CONCUR_UPDATABLE:结果集可以用于更新数据库 * */ public class ScrollAndUpdateTest { public static void main(String[] args) { var sql = "select cou_id,cou_name,credit,intro from course"; var helper = JdbcHelper.getInstance(); try (var conn = helper.getConnection(); var ptst = conn.prepareStatement(sql,ResultSet.TYPE_SCROLL_SENSITIVE,ResultSet.CONCUR_UPDATABLE)){ var rs = ptst.executeQuery(); rs.afterLast();//将游标移动到结果集的末尾 while(rs.previous()) { System.out.println("课程编号:" + rs.getInt("cou_id")); System.out.println("课程名称:" + rs.getString("cou_name")); System.out.println("课程学分:" + rs.getInt("credit")); System.out.println("课程简介:" + rs.getObject("intro")); System.out.println("--------------------------------------"); } System.out.println("========================="); rs.absolute(3);//滚动到第三条记录 System.out.println("课程编号:" + rs.getInt("cou_id")); System.out.println("课程名称:" + rs.getString("cou_name")); System.out.println("课程学分:" + rs.getInt("credit")); System.out.println("课程简介:" + rs.getObject("intro")); rs.absolute(2); var credit = rs.getInt("credit"); rs.updateInt(3, credit + 3); //可更新记录结果集 rs.updateRow();//将更新的记录提交到数据库 } catch (SQLException e) { e.printStackTrace(); } } }
处理大数据类型数据
利用Clob处理大的文本数据及利用Blob处理长二进制数据
package edu.uestc.avatar.sql; import java.io.BufferedInputStream; import java.io.BufferedOutputStream; import java.io.BufferedWriter; import java.io.File; import java.io.FileInputStream; import java.io.FileOutputStream; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.sql.SQLException; import edu.uestc.avatar.commons.JdbcHelper; public class LargerDataDemo { /** * 添加文本文件 * @param ssn 学号 * @param file 文本文件===>学生简历 */ private static void updateStudentResume(String ssn, File file) { String sql = "update student set resume=? where ssn=?"; try(var conn = JdbcHelper.getInstance().getConnection(); var reader = new FileReader(file)){ var ptst = conn.prepareStatement(sql); ptst.setClob(1, reader, file.length());//设置文本内容,将文本转为reader进行传输 ptst.setString(2, ssn); int ret = ptst.executeUpdate(); if(ret == 1) System.out.println(ssn + "学员个人简历更新成功"); }catch(SQLException | IOException e) { e.printStackTrace(); } } public static void main(String[] args) { //updateStudentResume("201810001",new File("D:\\test\\clock.html")); //readStudentResume("201810001"); //updateStudentPhoto("201810001", new File("C:/Users/Adan/Pictures/sufei.jpg")); readStudentPhoto("201810001"); } private static File readStudentResume(String ssn) { var file = new File(ssn + ".txt"); String sql = "select resume from student where ssn = ?"; try(var conn = JdbcHelper.getInstance().getConnection(); var out = new BufferedWriter(new FileWriter(file))){ var ptst = conn.prepareStatement(sql); ptst.setString(1, ssn); var rs = ptst.executeQuery(); if(rs.next()) { var clob = rs.getClob("resume"); var in = clob.getCharacterStream(); char[] buff = new char[1024]; var len = -1; while((len = in.read(buff)) != -1) out.write(buff, 0, len); in.close(); } }catch(SQLException | IOException e) { e.printStackTrace(); } return file; } private static void updateStudentPhoto(String ssn,File image) { String sql = "update student set photo=? where ssn=?"; try(var conn = JdbcHelper.getInstance().getConnection(); var input = new BufferedInputStream(new FileInputStream(image))){ var ptst = conn.prepareStatement(sql); ptst.setBlob(1, input);//blob对应的二进制IO流 ptst.setString(2, ssn); int ret = ptst.executeUpdate(); if(ret == 1) System.out.println(ssn + "学员头像更新成功"); }catch(SQLException | IOException e) { e.printStackTrace(); } } private static File readStudentPhoto(String ssn) { var file = new File(ssn + ".jpg"); String sql = "select photo from student where ssn=?"; try(var conn = JdbcHelper.getInstance().getConnection(); var output = new BufferedOutputStream(new FileOutputStream(file))){ var ptst = conn.prepareStatement(sql); ptst.setString(1, ssn); var rs = ptst.executeQuery(); if(rs.next()) { var blob = rs.getBlob("photo"); byte[] buff = new byte[1024]; var input = blob.getBinaryStream(); int len = -1; while((len = input.read(buff)) != -1) { output.write(buff, 0, len); } } }catch(SQLException | IOException e) { e.printStackTrace(); } return file; } }
获取元数据
利用数据库元数据可以动态获取数据库相关信息
1、数据库元数据
public class DatabaseMetaDemo { public static void main(String[] args) { try(var conn = JdbcHelper.getInstance().getConnection()){ var dbMeta = conn.getMetaData(); System.out.println("url:" + dbMeta.getURL()); System.out.println("database product name:" + dbMeta.getDatabaseProductName()); System.out.println("dababase major version:" + dbMeta.getDatabaseMajorVersion()); System.out.println("dababase minor version:" + dbMeta.getDatabaseMinorVersion()); System.out.println("jdbc driver name:" + dbMeta.getDriverName()); System.out.println("jdbc driver version:" + dbMeta.getDriverVersion()); System.out.println("max number of connections:" + dbMeta.getMaxConnections()); System.out.println("=======================结果集数据库表================="); var rsTables = dbMeta.getTables(null, null, null, new String[] {"TABLE"}); System.out.println("user tables:"); while(rsTables.next()) System.out.println(rsTables.getString("TABLE_NAME")); }catch (SQLException e) { e.printStackTrace(); } } }
2、结果集元数据
public class ResultSetMetaDataDemo { public static void main(String[] args) { try(var conn = JdbcHelper.getInstance().getConnection()){ var sql = "select course_id id,course_name name,credit,course_intro intro from course"; var ptst = conn.prepareStatement(sql); var rs = ptst.executeQuery(); //获取结果集的元数据 var meta = rs.getMetaData(); for(int i = 1; i <= meta.getColumnCount(); i++) //列名:getColumnName() System.out.print(meta.getColumnLabel(i) + "\t"); System.out.println(); while(rs.next()) { for(int i = 1; i <= meta.getColumnCount(); i++) System.out.print(rs.getObject(i) + "\t"); System.out.println(); } }catch (SQLException e) { e.printStackTrace(); } } }
RowSet
RowSet接口继承自ResultSet接口,RowSet接口下包含JdbcRowSet、CachedRowSet、FilteredRowSet、JoinRowSet和WebRowSet常用子接口。除了JdbcRowSet需要保持与数据的连接外,其余4个子接口都是离线的RowSet,无须保持与数据库的连接。
与ResultSet相比,RowSet默认时可滚动、可更新、可序列化的结果集,而且作为javaBean使用,因此能方便地在网络上传输,用于同步两端的数据。对于离线RowSet而言,程序创建RowSet时已经把数据从数据库读取到了内存,因此可以充分利用计算机的内存,从而降低数据库服务器的负载,提高程序性能。
通过RowSetFactory把应用程序和RowSet实现类分离开,下例演示可滚动、可更新的特性
离线RowSet
在使用ResultSet的时代,程序查询得到ResultSet之后必须立即读取或处理它对应的记录,否则一旦Connection关闭,再取通过ResultSet读取记录就会引发异常。在这种模式下,JDBC编程十分痛苦,假设应用程序分为数据访问层和视图显式层,当应用程序在数据访问层查询得到ResultSet后,对ResultSet的处理有如下两种常见的方式:
- 使用迭代访问ResultSet里的记录,并将这些记录转成JavaBean。再将多个JavaBean封装到一个List集合(参考另一篇博文:策略模式)。处理完成后就可以关闭Connection等资源,然后再将JavaBean集合传到视图显示层。
- 直接将ResultSet传到视图显示层——这要求当视图显示层显示数据时,底层Connection必须一直处于打开状态,否则ResultSet无法读取数据。
第一种方式比较安全,但编程要求较高,对各种类型转换处理也比较繁琐;第二种方式则需要Connection一直处于打开状态,这样不仅不安全,而且对程序性能也有很大影响。通过使用离线RowSet可以十分"优雅"地处理上面的问题,离线RowSet会直接将底层数据读入内存中,封装成RowSet对象,而RowSet对象可以完全当成JavaBean来使用。因此不仅安全而且编程十分简单。CachedRowSet是所有离线RowSet的父接口,因此以CachedRowSet为例作为介绍:
/** * DQL语句的顶层逻辑 * 使用离线结果集 * RowSet是ResultSet的子接口,RowSet默认是可滚动,可更新的 * JdbcRowSet * CachedRowSet * FilteredRowSet * JoinRowSet * WebRowSet * 除了JdbcRowSet需要与数据库保持连接之外,其余的都是离线RowSet * @param sql 要执行的查询语句 * @param params 可变参数 * @return 离线结果集 */ public RowSet executeQuery(String sql, Object...params){ Connection conn = null; PreparedStatement ptst = null; ResultSet rs = null; try{ conn = helper.getConnection(); ptst = conn.prepareStatement(sql); //对sql语句中的?占位参数进行设值 for (var i = 0; params != null && i < params.length; i++) ptst.setObject(i + 1, params[i]); rs = ptst.executeQuery(); //使用RowSetProvider创建RowSetFactory RowSetFactory factory = RowSetProvider.newFactory(); //创建默认的CachedRowSet实例 CachedRowSet crs = factory.createCachedRowSet(); //使用ResultSet填充RowSet crs.populate(rs); return crs; }catch (SQLException e){ LOGGER.debug(e.getMessage(),e); }finally { helper.free(rs,ptst,conn); } return null; }
离线RowSet的查询分页
由于CachedRowSet会将数据记录直接装载到内存中,因此如果SQL查询返回的记录过大,CachedRowSet就会占用大量的内存,在某些极端的情况下,甚至会导致内存溢出。为了解决该问题,CachedRowSet提供了分页功能。所谓分页就是一次装载ResultSet中的某几条记录,这样就可以避免CachedRowSet占用内存过大的问题。CachedRowSet通过如下方法控制分页:
populate(ResultSet rs, int startRow):从给定的rs的第startRow条记录开始填充
setPageSize(int pageSize):设置CachedRowSet每次返回多少条记录
previousPage():在底层ResultSet可用的情况下,让CachedRowSet读取上一页的记录
nextPage():在底层ResultSet可用的情况下,让CachedRowSet读取下一页的记录
/** * 封装分页DQL顶层逻辑 * @param sql sql语句 * @param offset 数据起始偏移量 * @param pageSize 加载数据量 * @param params 查询参数 * @return 离线RowSet */ public RowSet executeQuery(String sql, int offset,int pageSize,Object...params){ try( var conn = helper.getConnection(); var ptst = conn.prepareStatement(sql)){ //对sql语句中的?占位参数进行设值 for (var i = 0; params != null && i < params.length; i++) ptst.setObject(i + 1, params[i]); var rs = ptst.executeQuery(); //使用RowSetProvider创建RowSetFactory RowSetFactory factory = RowSetProvider.newFactory(); //创建默认的CachedRowSet实例 CachedRowSet crs = factory.createCachedRowSet(); //设置每页显示pageSize记录数 crs.setPageSize(pageSize); //使用ResultSet填充RowSet,从第几条记录开始桩头 crs.populate(rs,offset); return crs; }catch (SQLException e){ LOGGER.debug(e.getMessage(),e); } return null; }
事务处理
事务:代表一个业务边界(业务逻辑的多条语句组成),这系列操作要么全部执行,要么全部放弃执行。是保证数据完整的重要手段。
事务具备4个特性:
- 原子性(Atomicity):事务是一个整体的工作单元,事务对数据库所做的操作要么全部执行,要么全部取消。如果某条语句执行失败,则所有语句全部回滚。
- 一致性(Consistency):事务在完成时,必须使所有的数据都保持一致状态。在相关数据库中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。如果事务成功,则所有数据将变为一个新的状态;如果事务失败,则所有数据将处于开始之前的状态。
- 隔离性(Isolation):事务与事务之间是相互隔离的
由事务所作的修改必须与其他事务所作的修改隔离。事务查看数据时数据所处的状态,要么是另一并发事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看中间状态的数据。
- 持久性(Durability):事务提交后,对数据库数据的影响是持久性(永久的)
JDBC连接也提供了事务的支持。默认情况下,新连接是自动提交模式,并且每条sql语句都作为一个单独的事务执行和提交。可以用setAutoCommit(false)方法取消自动提交,此时,调用commit()或rollback()之前的所有语句都被组织成一个事务。
public class TransactionalDemo { public static void main(String[] args) { Connection conn = null; Savepoint sp = null; try { conn = JdbcHelper.getInstance().getConnection(); /* * 开启事务就是将默认的自动提交关闭 */ conn.setAutoCommit(false); String sql = "insert into course(course_name) values ('Linux')"; var ptst = conn.prepareStatement(sql); ptst.executeUpdate(); //可以在程序中设置多个事务保存点,可以将事务回滚到指定的保存点 sp = conn.setSavepoint(); sql = "delete from student where ssn = '201810001'"; ptst = conn.prepareStatement(sql); ptst.executeUpdate(); //违反约束,会发生异常 sql = "insert into score(ssn,course_id,score) values('9527',10,78)"; ptst = conn.prepareStatement(sql); ptst.executeUpdate(); //如果没有异常,提交事务 conn.commit(); }catch (SQLException e) { try { System.out.println("回滚事务"); if(conn != null) { //conn.rollback();//全部回滚 //回滚到指定的保存点 conn.rollback(sp); //保存点前的操作进行提交 conn.commit(); } e.printStackTrace(); } catch (SQLException e1) { e1.printStackTrace(); } } finally { JdbcHelper.getInstance().free(null, null, conn); } } }
批量更新
多条SQL语句被作为一批操作被同时收集,并同时提交
package edu.uestc.canary.jdbc; import java.sql.Connection; import java.sql.SQLException; public class BatchUpdatesDemo { public static void main(String[] args) { Connection conn = null; try{ conn = JdbcHelper.getInstance().getConnection(); /* * 开启事务就是将默认的自动提交关闭 */ conn.setAutoCommit(false); var sql = "insert into user(username,password) values(?,?)"; var ptst = conn.prepareStatement(sql); for(var i = 1; i <= 8650; i++) { ptst.setString(1, "batch_" + i); ptst.setString(2, "pass_" + i); ptst.addBatch(); //收集sql语句 if(i % 1000 == 0) ptst.executeLargeBatch();//一次提交所收集到的sql语句 } //提交剩余的sql语句 ptst.executeLargeBatch(); //没有异常,执行成功,提交事务 conn.commit(); }catch(SQLException e) { //有异常,回滚事务 try { System.out.println("发生异常,事务回滚:" + e.getMessage()); conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } } finally { //最终确保连接释放 JdbcHelper.getInstance().free(conn); } } }
使用连接池管理连接
数据库连接的建立及关闭是极耗费系统资源的操作,在多层结构的应用环境中,这种资源的耗费对系统性能影响尤为明显。通过DriverMananger获取数据库的连接均对应一个物理数据库的连接,每次操作都打开一个物理连接,使用完后立即关闭连接。频繁的打开、关闭连接将造成系统性能低下。
数据库连接池的解决方案:当应用程序启动时,系统主动建立足够的数据库连接,并将这些连接放入连接池。每次应用程序请求数据库连接时,无须重新打开连接,而是从连接池中取出已有的连接使用,使用完后归还给连接池。为了解决数据库连接的频繁请求、释放,JDBC2.0规范引入了数据库连接池技术。使用javax.sql.DataSource来表示,DataSource只是一个规范,该规范通常由商用服务器及开源组织提供实现。
package edu.uestc.avatar.commons; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; import java.util.Properties; import javax.sql.DataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; /** * jdbc工具类 * 采用数据源(jdbc扩展规范)来获取连接 * 传统方式:DriverManager.getConnection(url,username,password);使用完毕后进行释放 * 创建数据库连接是非常消耗系统资源,频繁创建及释放连接,对系统性能影响很大 * 连接池参数 * 初始化连接数 * 最大连接数 * 最大等待时间 * 最大空闲数 * 最小空闲数 * * 选用产品: * dbcp2、c3p0、druid、boneCP、hikari ....... * */ @SuppressWarnings("static-access") public class JdbcUtil { //数据源 private static DataSource dataSource; private static JdbcUtil instance; static { try {//初始化数据源 var prop = new Properties(); prop.load(JdbcUtil.class.getClassLoader().getResourceAsStream("jdbc.properties")); //通过工厂创建数据源,只要properties中的property的名称为DruidDataSourceFactory里的属性名相同,会自动将对应的属性值设置给对应的属性 var factory = new DruidDataSourceFactory(); dataSource = factory.createDataSource(prop); } catch (Exception e) { e.printStackTrace(); } } private JdbcUtil() { } /** * 通过数据源获取连接对象 * @return 数据库连接对象 * @throws SQLException */ public Connection getConnetion() throws SQLException { return dataSource.getConnection(); } /** * 释放jdbc相关资源 * @param rs 结果集 * @param stat 语句对象 * @param conn 连接对象 */ public void free(ResultSet rs, Statement stat, Connection conn) { try { if(rs != null) rs.close(); } catch (SQLException e) { e.printStackTrace(); } finally { try { if(stat != null) stat.close(); } catch (SQLException e) { e.printStackTrace(); } finally { try { if(conn != null) conn.close(); } catch (SQLException e) { e.printStackTrace(); } } } } public static JdbcUtil getInstance() { if(instance == null) { synchronized (JdbcUtil.class) { if(instance == null) instance = new JdbcUtil(); } } return instance; } }
DAO模式
DAO(Data Access Object)顾名思义是一个为数据库或其他持久化机制提供了抽象接口的对象,在不暴露底层持久化方案实现细节的前提下提供了各种数据访问操作。
在实际的开发中,应该将所有对数据源的访问操作进行抽象化后封装在一个公共API中。
用程序设计语言来说,就是建立一个接口,接口中定义了此应用程序中将会用到的所有事务方法。在这个应用程序中,当需要和数据源进行交互的时候则使用这个接口,并且编写一个单独的类来实现这个接口,在逻辑上该类对应一个特定的数据存储。
DAO模式实际上包含了两个模式,一是Data Accessor(数据访问器),二是Data Object(数据对象),前者要解决如何访问数据的问题,而后者要解决的是如何用对象封装数据。
package edu.uestc.avatar.domain; import java.time.LocalDate; /** * 学生实体类----pojo * 用于Student对象封装数据 * */ public class Student { private String ssn; private String name; //后期使用枚举 private String gender = "MALE"; private String address; private String phone; private LocalDate bornDate; //setter and getter @Override public String toString() { return "Student [ssn=" + ssn + ", name=" + name + ", gender=" + gender + ", address=" + address + ", phone=" + phone + ", bornDate=" + bornDate + "]"; } }
针对Student的是Data Accessor(数据访问器)
package edu.uestc.avatar.dao; import java.util.List; import edu.uestc.avatar.domain.Student; public interface StudentDao { /** * 保存学生信息 * @param student {@link Student} */ void save(Student student); /** * 根据学号删除学生信息 * @param ssn 学号 */ void removeBySsn(String ssn); /** * 根据学号修改学生信息 * @param student 修改后的学员信息,学号不允许被修改 */ void modify(Student student); /** * 根据学号加载学员信息 * @param ssn 学号 * @return 学员信息,没有找到,返回null */ Student findBySsn(String ssn); /** * 加载学生总数 * @return 学生总数 */ long count(); /** * 分页加载学生信息 * limit offset, size * @param offset 起始偏移量,基于0 * @param size 加载大小 * @return 学生列表 */ List<Student> paging(int offset, int size); }
单独的类来实现这个数据访问接口,后期使用模板方法模式及策略模式改写
package edu.uestc.avatar.dao.impl; import java.sql.Connection; import java.sql.SQLException; import java.util.ArrayList; import java.util.List; import edu.uestc.avatar.commons.JdbcUtil; import edu.uestc.avatar.dao.StudentDao; import edu.uestc.avatar.domain.Student; /** * StudentDao实现类 * */ public class StudentDaoImpl implements StudentDao { private JdbcUtil util = JdbcUtil.getInstance(); @Override public void save(Student student) { Connection conn = null; try { conn = util.getConnetion(); var sql = "insert into student(ssn,stu_name,stu_gender,born_date,address,phone)" + " values (?,?,?,?,?,?)"; var ptst = conn.prepareStatement(sql); //设置预编译参数 ptst.setString(1, student.getSsn()); ptst.setString(2, student.getName()); ptst.setString(3, student.getGender()); ptst.setObject(4, student.getBornDate()); ptst.setString(5, student.getAddress()); ptst.setString(6, student.getPhone()); ptst.executeUpdate(); }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } } @Override public void removeBySsn(String ssn) { Connection conn = null; try { conn = util.getConnetion(); var sql = "delete from student where ssn=?"; var ptst = conn.prepareStatement(sql); ptst.setString(1, ssn); ptst.executeUpdate(); }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } } @Override public void modify(Student student) { Connection conn = null; try { conn = util.getConnetion(); var sql = "update student set stu_name=?,stu_gender=?,born_date=?," + "address=?,phone=? where ssn=?"; var ptst = conn.prepareStatement(sql); ptst.setString(1, student.getName()); ptst.setString(2, student.getGender()); ptst.setObject(3, student.getBornDate()); ptst.setString(4, student.getAddress()); ptst.setString(5, student.getPhone()); ptst.setString(6, student.getSsn()); ptst.executeUpdate(); }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } } @Override public Student findBySsn(String ssn) { Student student = null; Connection conn = null; try { conn = util.getConnetion(); var sql = "select ssn,stu_name,stu_gender,born_date,address,phone from student where ssn=?"; var ptst = conn.prepareStatement(sql); ptst.setString(1, ssn); var rs = ptst.executeQuery(); if(rs.next()) { student = new Student(); student.setSsn(rs.getString("ssn")); student.setGender(rs.getString("stu_gender")); student.setAddress(rs.getString("address")); student.setName(rs.getString("stu_name")); student.setPhone(rs.getString("phone")); if(rs.getDate("born_date") != null) student.setBornDate(rs.getDate("born_date").toLocalDate());//java.sql.Date } }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } return student; } @Override public long count() { Connection conn = null; try { var sql = "select count(ssn) from student"; conn = util.getConnetion(); var ptst = conn.prepareStatement(sql); var rs = ptst.executeQuery(); if(rs.next()) { return rs.getLong(1); } }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } return 0; } @Override public List<Student> paging(int offset, int size) { List<Student> students = new ArrayList<Student>(); Connection conn = null; try { var sql = "select ssn,stu_name,stu_gender,born_date,address,phone from student limit ?,?"; conn = util.getConnetion(); var ptst = conn.prepareStatement(sql); ptst.setInt(1, offset); ptst.setInt(2, size); //执行查询,处理结果集 var rs = ptst.executeQuery(); while(rs.next()) { Student student = new Student(); student.setSsn(rs.getString("ssn")); student.setGender(rs.getString("stu_gender")); student.setAddress(rs.getString("address")); student.setName(rs.getString("stu_name")); student.setPhone(rs.getString("phone")); if(rs.getDate("born_date") != null) student.setBornDate(rs.getDate("born_date").toLocalDate());//java.sql.Date students.add(student); } }catch(SQLException e) { e.printStackTrace(); } finally { util.free(null, null, conn); } return students; } }


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!
2020-04-21 高可用并发解决方案Nginx+keepalived