

集合-Set
集合(Set)是一个用于存储和处理无重复元素的高效数据结构。映射表(map)类似于目录,提供了使用键值快速查询和获取值的功能。
论文答辩名单是一个由你们导师创建和维护的一张表,列出了本次论文答辩的学生名单。假设我们需要写一个程序,检验一个人是否在名单上,可以使用一个线性表来存储答辩名单上面的名字。然而,用Set集合实现这个程序更加有效。
假设你的程序还需要存储名单上面学生的详细信息,可以使用名字作为键值来获取诸如性别、身高及住址等详细信息。映射表(map)是实现这种任务的有效数据结构。
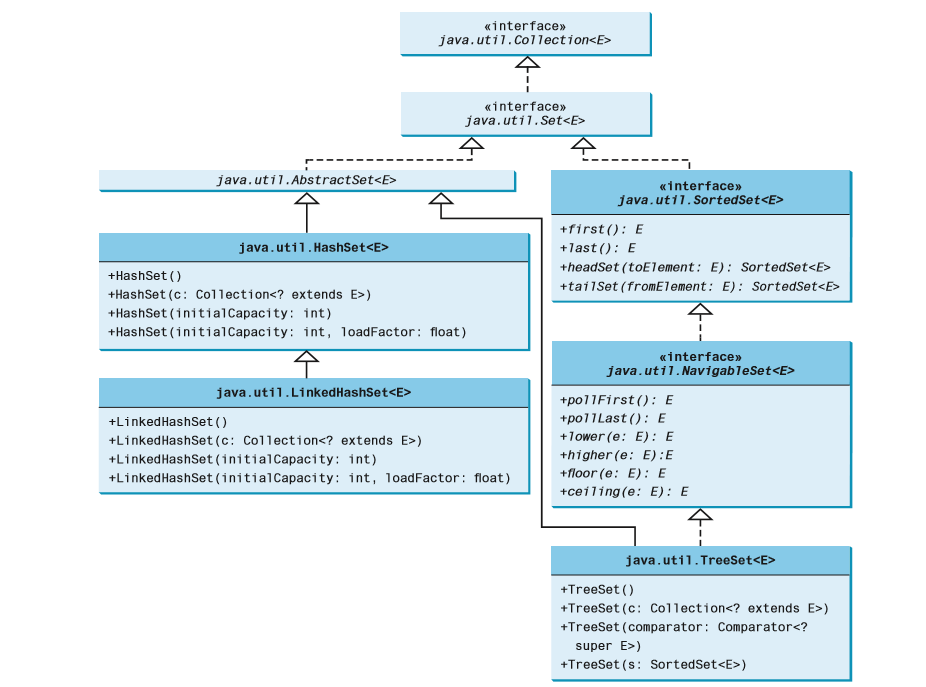
Set接口扩展自Collection接口,如上图所示。它没有引入新的方法或常量,只是规定Set的实例不包含重复元素。实现Set的具体类必须确保不能向这个集合添加重复的元素。Set接口的三个具体实现类为HashSet、LinkedHashSet和TreeSet。
HashSet
HashSet类可以用来存储互不相同的任何元素。考虑到效率因素,添加到散列集中的对象必须以一种正确分散的散列码的方式来实现hashCode方法。回顾在Object类中定义的hashCode,如果两个对象相等,那么这两个对象的散列码必须一样。两个不相等的对象可能会有相同的散列码,因此应该重写hashCode方法以避免出现太多这样的情况。Java API中的大多数类都实现了hashCode方法。
- HashSet()
构造一个空散列集。
- HashSet(Collection<? extends E> elements)
构造一个散列集,并将集合中的所有元素添加到这个散列集中。
- HashSet(int initialCapacity)
构造一个空的具有指定容量(桶数)的散列集。
- HashSet(int initialCapacity,float loadFactor)
构造一个有指定容量和装填因子( 0.0~1.0之间的一个数,确定散列表填充的百分比,当大于这个百分比时,散列表进行再散列)的空散列集。通常情况下,默认的负载系数(装填因子)是0.75,它是在时间开销和空间开销上一个很好的权衡。

/** * HashSet底层使用HashMap实现 * HashMap:散列表 (数组 + 链表) * (1)数组:占用空间连续。寻址容易 ,查询速度快。但是,增加和删除效率非常低 * (2)链表:占用空间不连续。寻址困难 ,查询速度慢。但是,增加和删除效率非常高。 * 1.当存储一个对象(元素)时,首先会基于该对象hashcode值计算出hash值(数组的索引)————快速定位位桶数组 * 2.数组的每个元素存储的是一个链表————增删元素效率较高 * 如果对象的hash碰撞(相同):会调用对象身上的equals方法进行比较对象是否存在,存在就不保存 * 如果对象的hash不同,直接将对象添加进链表 * HashSet无序,元素不重复 * */ public class HashSetTest { public static void main(String[] args) { Set<Circle> circles = new HashSet<>(); circles.add(new Circle(10)); circles.add(new Circle(20)); circles.add(new Circle(30)); circles.add(new Circle(5)); circles.add(new Circle(10)); System.out.println(circles.size()); // // for (var circle : circles) // System.out.println(circle); System.out.println(circles); } }
Circle
public class Circle { private float radius; public Circle(float radius){ this.radius = radius; } public float getRadius() { return radius; } public void setRadius(float radius) { this.radius = radius; } @Override public String toString() { return "Circle{" + "radius=" + radius + '}'; } /** * 如果圆半径相等,圆对象相等 * jdk规定:如果两个对象相等,那么它们的hashcode值一定相等 * 两个不相等的对象可能存在相同的hashcode---hash碰撞(hash冲突) * * HashSet-----> */ @Override public boolean equals(Object o) { System.out.println("如果hash冲突,会调用该equals方法比较链表上是否存在相等对象"); if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Circle circle = (Circle) o; return Float.compare(radius, circle.radius) == 0; } @Override public int hashCode() { System.out.println("保存前都会调用该对象的hashcode方法确定hash值"); return Objects.hashCode(radius); } }
LinkedHashSet
LinkedHashSet用一个链表来扩展HashSet类,它支持对集合内的元素排序。HashSet中的元素是没有顺序的,而LinkedHashSet中的元素可以按照它们插入集合的顺序提取。
package edu.uestc.avatar; import java.util.LinkedHashSet; import java.util.Set; public class LinkedHashSetTest { public static void main(String[] args) { Set<String> set = new LinkedHashSet<>(); set.add("peppa"); set.add("emily"); set.add("pedro"); set.add("jorge"); set.add("peppa"); System.out.println(set); for (var e : set) System.out.println(e.toUpperCase()); } }
TreeSet
TreeSet可以确保集合中的元素是有序的。
package edu.uestc.avatar; import edu.uestc.avatar.pojo.Circle; import java.util.Set; import java.util.TreeSet; public class TreeSetTest { public static void main(String[] args) { Set<String> set = new TreeSet<>(); //String: Comparable<String> set.add("peppa"); set.add("emily"); set.add("pedro"); set.add("jorge"); set.add("peppa"); System.out.println(set); Set<Circle> circles = new TreeSet<>(); circles.add(new Circle(5)); circles.add(new Circle(3)); circles.add(new Circle(20)); circles.add(new Circle(15)); circles.add(new Circle(20)); System.out.println(circles); //ClassCastException: Circle ----> Comparable /** * 1. Circle本身是可排序的,实现Comparable--->按照半径进行升序排序 * 2. 比较排序,创建set实例时提供外部比较器---->按照半径进行降序排序 */ Set<Circle> circles2 = new TreeSet<>((c1,c2)->c1.getRadius() == c2.getRadius() ? 0 : c1.getRadius() < c2.getRadius() ? 1 : -1); circles2.add(new Circle(5)); circles2.add(new Circle(3)); circles2.add(new Circle(20)); circles2.add(new Circle(15)); circles2.add(new Circle(20)); System.out.println(circles2); //treeSet实现了SortedSet接口 System.out.println("treeSet中第一个元素:" + ((TreeSet<String>) set).first()); System.out.println("treeSet最后一个元素:" + ((TreeSet<String>) set).last()); System.out.println("pedro元素前的元素" + ((TreeSet<String>) set).headSet("pedro")); System.out.println("pedro元素后的元素" + ((TreeSet<String>) set).tailSet("pedro")); } }
你可能很想知道是否应该总是用TreeSet而不是HashSet。毕竟,添加一个元素所花费的时间看上去并不很长,而且元素是自动排序的。到底应该怎样做取决于所要收集的数据。如果不需要数据是有序的,就没有必要付出排序的开销。更重要的是,对于某些数据来说,对其进行排序要比给出一个散列函数更加困难。散列函数只需要将对象适当地打乱存放而比较函数必须精确地区分各个对象。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· AI与.NET技术实操系列:基于图像分类模型对图像进行分类
· go语言实现终端里的倒计时
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· 零经验选手,Compose 一天开发一款小游戏!
· 一起来玩mcp_server_sqlite,让AI帮你做增删改查!!