
排序算法
2007年,当总统候选人Baeack Obama访问Google公司时,Google的CEO Eric Schmidt问了Obama一个问题,对100万32位整数排序的最有效的方式是什么。Obama回答冒泡算法将不是好的选择。他的回答正确吗?我们先来考察各种排序算法,然后看看他是否正确。
一、插入排序
插入排序重复地将新的元素插入到一个排序好的子线性表中,直到整个线性表排好序。
插入排序( Insertion sort)是一种简单直观且稳定的排序算法。
插入排序的工作方式非常像人们排序一手扑克牌一样。开始时,我们的左手为空并且桌子上的牌面朝下。然后,我们每次从桌子上拿走一张牌并将它插入左手中正确的位置。为了找到一张牌的正确位置,我们从右到左将它与已在手中的每张牌进行比较,如下图所示
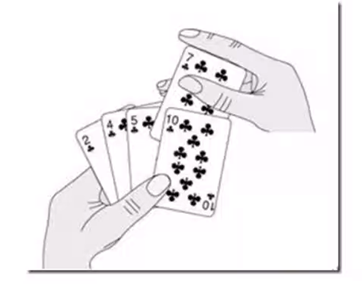
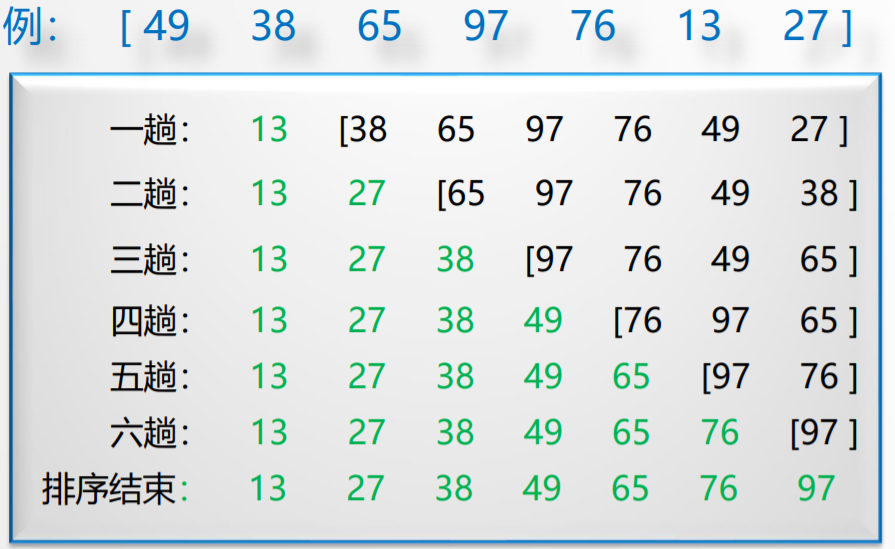
下图描述如何用插入排序法对线性表{49 38 65 97 76 13 27}进行排序。
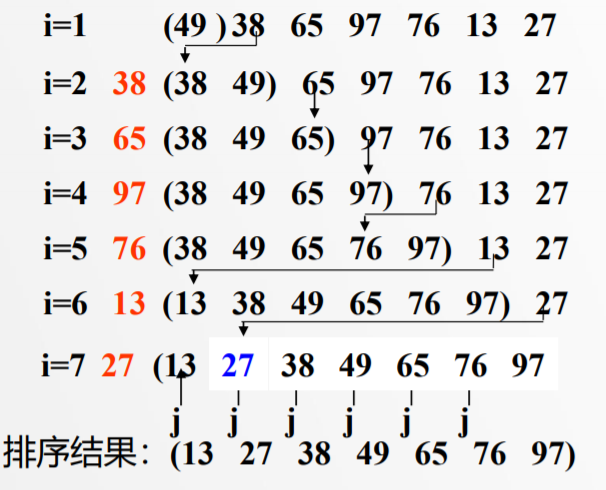
i=1:最开始,排好序的子线性表只包含线性表中第一个元素49。把未排序的第一个元素38插入到该子线性表中
i=2:38比49小,49往后挪一个位置,将38插入到49前面,排好序的子线性表为{38,49},把未排序的第一个元素65插入到子线性表中
i=3:排好序的子线性表为{38,49,65},将未排序的第一个元素97插入到子线性表中
i=4:排好序的子线性表为{38,49,65,97},将未排序的第一个元素76插入到子线性表中
i=5:排好序的子线性表为{38,49,65,76,97},将未排序的第一个元素13插入到子线性表中
i=6:排好序的子线性表为{13,38,49,65,76,97},将未排序的第一个元素27插入到子线性表中
i=7:现在整个线性表已经排好序了
这样,有序子线性表逐渐扩大,未排序的逐渐减少,直到整个线性表已经排好序,我们关心的是你怎么采取直接插入排序就将数据给插入进去了呢,所以我们对最后一个元素27具体是怎么一步步实现插入的进行详细的说明。
首先:27比97要小,我们要插入到这个有序序列中,97就需要向后移动一个位置,向后移动一个位置就会把27给覆盖掉,所以我们需要把27进行暂存(currentElement,我们称为哨兵或者岗哨),然后我把有序序列最后一个元素和哨兵比,如果这个元素比岗哨小,很显然,岗哨就要在它后面,直接写回去就可以了,但是现在27是比97小的,所以j指针所指向的元素向后移动一个位置,接着j指针往前移,直到遇到比它小的元素(如果没有比岗哨小的元素,说明岗哨就在第一个位置)。

step1:将27保存到一个临时变量currentElement

step2:将list[5]移到list[6]

step3:将list[4]移到list[5]

step4:将list[3]移到list[4]

step5:将list[2]移到list[3]

step6:将list[1]移到list[2]

step7:将currentElement赋值给list[1]
这个算法可以描述如下:
for(int i = 1; i < list.length;;i++){
将list[i]插入已排好序的子线性表中,这样list[0...i]也是排好序的
}
为了将list[i]插入list[0...i],需要将list[i]存储在一个名为currentElement的临时变量中。如果list[i-1]>currentElement,就将list[i-1]移到list[i];如果list[i-2]>currentElement,就将list[i-2]移到list[i-1],依次类推,直到list[i-k]<=currentElement或者k>i(传递的是排好序的的数列的第一个元素)。将currentElement赋值给list[i-k+1].
算法可以扩展和执行:
public static void insertioinSort(int[] list) {
for(int i = 1; i < list.length; i++) {
int currentElement = list[i];//未排序的第一个元素,称为哨兵
int j;
for(j = i - 1; j >= 0 && currentElement < list[j]; j--)
list[j + 1] = list[j];
list[j + 1] = currentElement;
}
}
算法评价:
插入排序重复地将新的元素插入到一个排序好的子线性表中,直到整个线性表排好序。在第k次次迭代中,为了将一个元素插入到一个大小为k的数组中,将进行k次比较来找到插入的位置,还要进行k次的移动来插入元素。使用T(n)表示插入排序的复杂度,c表示诸如每次迭代中的赋值和额外的比较的操作总数,则
T(n) = (2+c) + (2*2+c)+...+(2*(n-1) +c)
=2(1+2+...n-1)+c(n-1)
=2[(n-1)n/2]+cn=n2 -n+cn-c
=O(n2)
因此,插入排序的时间复杂度为: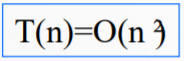
思考
简单插入排序的本质?
比较和交换
序列中逆序的个数 决定交换次数。
平均逆序数量为C(n,2) / 2 ,所以T(n)=O(n2)
简单插入排序复杂度由什么决定?逆序个数
如何改进简单插入排序复杂度?
• 分组,比如C(n,2)/2 > 2C((n/2),2)/2
• 3,2,1有3组逆序对(3,1)(3,2)(2,1)需要交换3次。但相隔较远的 3,1交换一次后1,2,3就没有逆序对了。
• 基本有序的插入排序算法复杂度接近O(n)
二、希尔排序(缩小增量法)
希尔排序是简单插入排序算法的一种更高效的改进版本。
基本思想:分割成若干个较小的子文件,对各个子文件分 别进行直接插入排序,当文件达到基本有序时,再对整个 文件进行一次直接插入排序。
对待排记录序列先作“宏观”调整,再作“微观”调整。
“宏观”调整,指的是,“跳跃式”的插入排序。(前面学习插入排序的时候,我们会发现一个很不友好的事儿,如果已排序的分组元素为{2,5,7,9,10} ,未排序的分组元素为{1,8} ,那么下一个待插入元素为1 , 我们需要着1从后往前,依次和10,9,7,5,2进行交换位置,才能完成真正的插入,每次交换只能和相邻的元素交换位置。那如果我们要提高效率,直观的想法就是一次交换 ,能把1放到更前面的位置,比如一次交换就能把1插到2和5之间,这样一次交换1就向前走了5个位置,可以减少交换的次数,这样的需求如何实现呢?接下来我们来看看希尔排序的原理)。
排序原理:
1.选定一个增长量d ,按照增长量d作为数据分组的依据,对数据进行分组;
2.对分好组的每一组数据完成插入排序;
3.减小增长量,最小减为1 , 重复第二步操作。
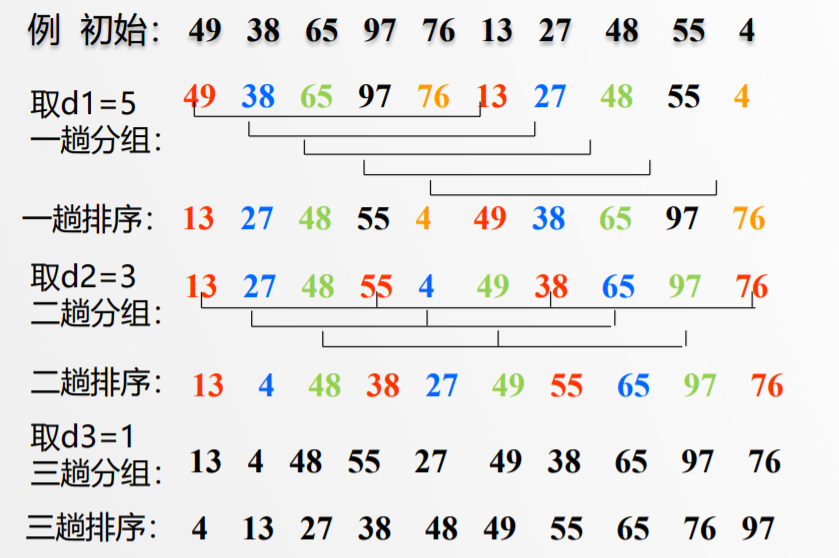
算法示例:
public static void shellSort(int[] list) {
//第一步:确定希尔增量,采用Hibbard’s增量序列(1,3,7.... 2^k -1) int ht = 1; //根据数组的长度确定增量值 while(ht < list.length / 2)ht = ht * 2 + 1; //排序 while(ht >= 1) { //完成每组的插入排序(1.找到待插入的元素,即为ht对应的元素) for(int i = ht;i < list.length; i++) {
int currentElement = list[i]; int j; //将元素插入到有序序列中 for( j = i - ht; j >= 0 && currentElement < list[j];j -= ht) { list[j + ht] = list[j]; } list[j + ht] = currentElement; } //缩减希尔增量 ht /= 2; } }
希尔排序特点
- 子序列的构成不是简单的“逐段分割”,而是将相隔某个增量的记录组成 一个子序列
- 希尔排序可提高排序速度,因为
- 分组后n值减小,n²更小,而T(n)=O(n²),所以T(n)从总体上看是减小了
- 关键字较小的记录跳跃式前移,在进行最后一趟增量为1的插入排序时, 序列已基本有序
- 增量序列取法
- 无除1以外的公因子
- 最后一个增量值必须为1
希尔排序的复杂度和增量序列是相关的
【定理】使用希尔增量的最坏时间复杂度为 O( N2 ).
〖Example〗A bad case:
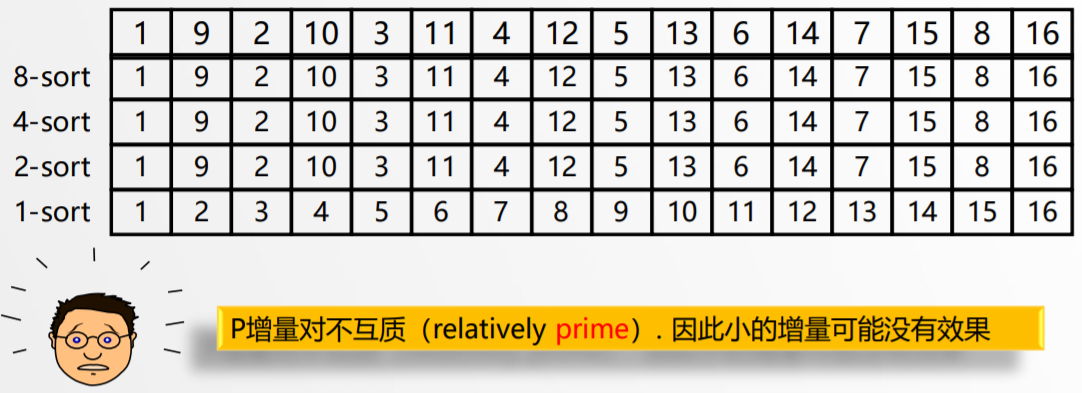
Hibbard’s 增量序列: hk = 2 k - 1 ---- 持续增量没有公共因子.
使用Hibbard’s 增量的最坏时间复杂度 O ( N3/2 ).
Conjectures: Tavg – Hibbard ( N ) = O ( N5/4 ).
Sedgewick’s best sequence is {1, 5, 19, 41, 109, … } in which the terms are either of the form 9 * 4 i – 9 * 2 i + 1 or 4 i – 3 * 2 i + 1.
Tavg ( N ) = O ( N7/6 ) and Tworst ( N ) = O ( N4/3 ).
希尔排序算法本身很简单,但复 杂度分析很复杂. 他适合于中等 数据量大小的排序(成千上万的 数据量).

三、简单选择排序
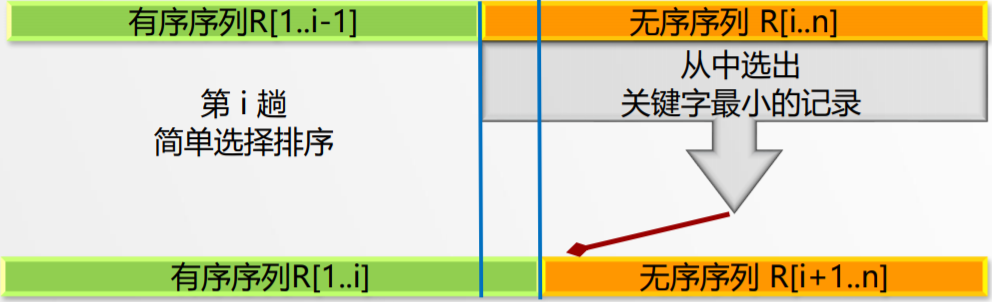
基本思想:从无序子序列中“选择”关键字最小或最大的记录,并将它加入到有序子序列中,以此方法增加记录的有序子序列的长度。
假设排序过程中,待排记录序列的状态为:
排序过程
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与 第一个记录交换
- 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与 第二个记录交换
- 重复上述操作,共进行n-1趟排序后,排序结束
算法描述
public static void selectionSort(int[] list) { for(int i = 0; i < list.length - 1; i++) { int currentMin = list[i]; int currentIndex = i; for(int j = i + 1; j < list.length; j++) { if(currentMin > list[j]) {//选择最小的元素 currentMin = list[j]; currentIndex = j;// } } if(currentIndex != i) { list[currentIndex] = list[i]; list[i] = currentMin; } } }
简单选择排序性能分析
对 n 个记录进行简单选择排序,所需进行的 关键字间的比较次数为:
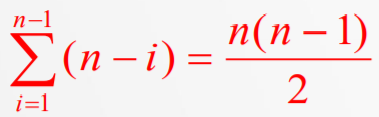
移动记录的次数,最小值为 0, 最大值为3(n-1)
T(n)=O(n2)
稳定性分析
初始数据:3,3,1,4
第一趟排序: 1,3,3,4
1,3,3,4
1,3,3,4
所以选择排序是不稳定排序
四、冒泡排序
冒泡排序算法多层遍历数组,在每次遍历中连续比较相邻的元素,如果元素没有按照顺序排列,则互换他们的值。由于较小的值像“气泡”一样逐渐符向顶部,而较大的值沉向底部,所以称这种技术为冒泡排序(bubble sort)或下沉排序(sinking sort)。第一次遍历后,最后一个元素称为数组中的最大值。在第二次遍历后,倒数第二个元素成为数组中的第二大数。整个过程持续到所有元素都排好序。

算法描述
注意到如果在某次遍历中没有发生交换,那么就不必进行下一次遍历,因为所有的元素都已经排好序了。使用该特征可以改变上述算法:
public static void bubbleSort(int[] list) { boolean needNextPass = true; for(int i = 1; i < list.length && needNextPass; i++) {//如果在某次迭代中没有元素发生交换,不需要进行下一次的比较了 needNextPass = false; for(int j = 0; j < list.length - i; j++) { if(list[j] > list[j + 1]) { int temp = list[j]; list[j] = list[j + 1]; list[j + 1] = temp; needNextPass = true; } } } }
算法分析
在最佳情况下,冒牌排序算法只需要一次遍历就能确定数组已排好序,不需要下一次遍历。由于第一次遍历的比较次数为n-1,因此在最佳情况下,冒泡排序的时间为O(n).在最差情况下,冒泡排序需要进行n-1次遍历。在第一次遍历需要n-1次比较;第二次遍历需要n-2次比较;依次进行,最后一次遍历需要1次比较。因此,总的比较次数为: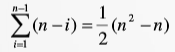 ,因此,在最差情况下,冒泡排序的时间复杂度为O(n2)。
,因此,在最差情况下,冒泡排序的时间复杂度为O(n2)。
五、归并排序
归并排序将数组分为两半,对每部分递归地应用归并排序,在两部分都排好序后,对它们进行合并
算法描述
public static void mergeSort(int[] list) {
if(list.length > 1) {
//将数组拆分成两个子数组
int[] firstList = new int[list.length / 2];
System.arraycopy(list, 0, firstList, 0, list.length / 2);
mergeSort(firstList);
int secondSize = list.length - list.length / 2;
int[] secondList = new int[secondSize];
System.arraycopy(list, list.length / 2, secondList, 0, secondSize);
mergeSort(secondList);
//合并两个子数组
merge(firstList, secondList, list);
}
}
private static void merge(int[] list1,int[] list2,int[] temp) {
int index1 = 0;
int index2 = 0;
int index3 = 0;
while(index1 < list1.length && index2 < list2.length) {
if(list1[index1] < list2[index2]) {
temp[index3++] = list1[index1++];
}else {
temp[index3++] = list2[index2++];
}
}
while(index1 < list1.length) {//如果list1中还有没有移动到临时数组中的元素
temp[index3++] = list1[index1++];
}
while(index2 < list2.length) {//如果list21中还有没有移动到临时数组中的元素
temp[index3++] = list2[index2++];
}
}
下图演示了归并排序。
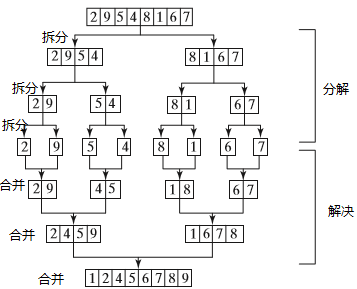
递归调用持续将数组划分为子数组,直到每个子数组只包含一个元素。然后,该算法将这些小的子数组归并为稍大的子数组,直到最后形成一个有序的数组。
算法实现
合并两个有序数组
current1和current2指向list1和list2中要考虑的当前元素,重复的比较list1和list2中当前元素。并将较小的元素移动到temp中,如果较小元素在list1中,current1和current3增加1,如果较小元素在list2中,current2和current3增加1。最后,其中一个数组中的所有元素都都被移动到temp中。如果list1中还有未移动的元素,就将它们复制到temp中,同理如果list2中还有未移动的元素,就将它们复制到temp中。如下图所示:
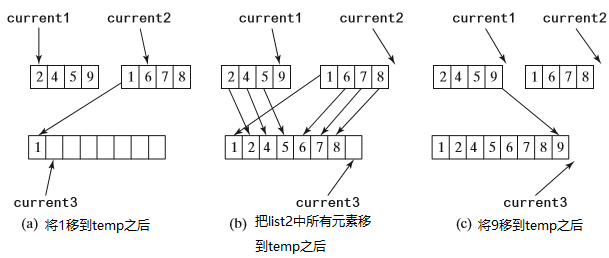
算法评价
时间复杂度:每一趟归并的时间复杂度为O(n), 总共需要归并 log2n趟,因而,总的时间复杂度为O(nlog2n)。
空间复杂度:归并排序过程中,需要一个与表等长的存储单 元数组空间,因此,空间复杂度为O(n)。

归并排序并行版
归并排序可以使用并行处理高效执行。JDK7引入了新的Fork/Join框架用于并行编程,从而利用多核处理器。它可以实现线程池中任务的自动调度,并且这种调度对用户来说是透明的。为了达到这种效果,必须按照用户指定的方式对任务进行分解,然后再将分解出的小型任务的执行结果合并成原来任务的执行结果。这显然是运用了分治法(divide-and-conquer)的思想。
import java.util.Arrays; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.RecursiveAction;
/**
* Fork/Join框架高效地自动执行和协调所有任务
*/ public class ParallelMergeSort { public static final int SIZE = 5_000_0000; public static void main(String[] args) { int[] list1 = new int[SIZE]; int[] list2 = new int[SIZE]; for(var i = 0; i < SIZE; i++) { list1[i] = list2[i] = (int)(Math.random() * 1000000000); } var startTime = System.currentTimeMillis(); SelectionSort.mergeSort(list1); System.out.println("归并排序所花时间:" + (System.currentTimeMillis() - startTime)); startTime = System.currentTimeMillis(); parallelMergeSort(list2); System.out.println("并行归并排序所花时间:" + (System.currentTimeMillis() - startTime)); } private static void parallelMergeSort(int[] list) { var action = new SortTask(list);
//巨量的子任务可以在池中创建和执行 var pool = new ForkJoinPool();
//主任务执行完后将返回 pool.invoke(action); } private static class SortTask extends RecursiveAction{ private static final long serialVersionUID = 1L; private int[] list; public SortTask(int[] list) { this.list = list; } @Override protected void compute() { if(list.length < 500) {//当问题分解到可求解程度时直接计算结果 Arrays.sort(list); }else { int[] firstHalf = new int[list.length / 2]; System.arraycopy(list, 0, firstHalf, 0, firstHalf.length); int[] secondHalf = new int[list.length - list.length / 2]; System.arraycopy(list, list.length / 2, secondHalf, 0, secondHalf.length);
//执行主任务时,任务分为子任务,通过使用invokeAll调用子任务,该方法在所有子任务都完成后将返回(每个子任务又递归地分为更加小的任务) invokeAll(new SortTask(firstHalf),new SortTask(secondHalf)); SelectionSort.merge(firstHalf, secondHalf, list); } } } }
快速排序
实际使用中已知最快的算法,快速排序工作机制如下,该算法在数组中选择一个称为主元(pivot)的元素,将数组分为两部分,使得第一部分中的所有元素都小于或等于主元,而第二部分中的所有元素都大于主元。对第一部分递归地应用快速排序算法,然后对第二部分递归地应用快速排序算法。
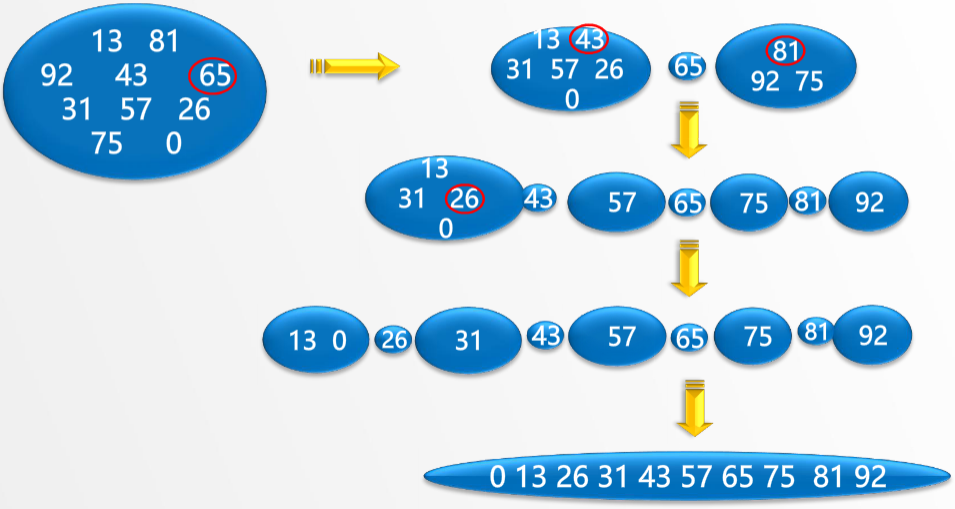
算法描述
public static void quickSort(int[] list) { if (1ist.1ength > 1) { select a pivot; partition list into list1 and list2 such that all elements in list1 <= pivot and all elements in 1ist2 > pivot; quickSort(list1); quickSort(1ist2); } }
主元
该算法的每次划分都将主元放在了恰当的位置。主元的选择会影响算法的性能。在理想情况下,应该选择能平均划分两部分的主元。
- 错误的方法: pivot= list[0 ]
最糟糕的情况: list[ ]有序或者逆序 quicksort= O( N2)
- 安全的方法: pivot = random select from list[ ]
随机数生成很花时间(expensive)
- 3者取中法:
pivot = median ( left, center, right )
这种方法能够排除序列有序的枢纽是最小或者最大值情况,实际运行时间能够减少约5%.
为了简单起见,假定将数组中的第一个元素作为主元进行说明
排序过程:
- 对list[first.....last]中记录进行一趟快速排序 ,附设两个指针low和high,设划分元记录pivot=list[first]
- 初始时令low=first+1,high=last
- 首先从high所指位置向前搜索第一个小于pivot的记录,并和pivot交换(主元频繁参与交换时很不划算的,思考如何改进)
- 再从low所指位置起向后搜索,找到第一 个大于pivot的记录,和pivot交换
- 重复上述两步,直至low==high为止
-
再分别对两个子序列进行快速排序,直到每个子序列只含有一个记录为止
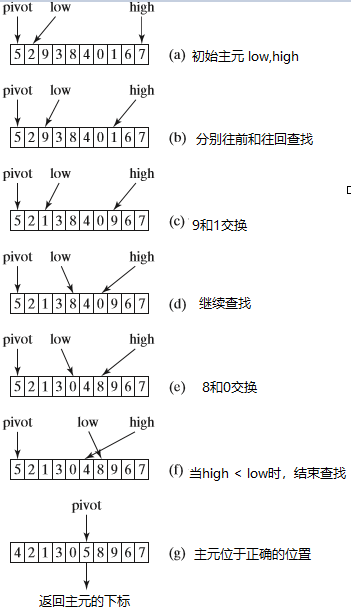
算法实现
/** * 快速排序 * */ public class QuickSort { public static void quickSort(int[] list) { quickSort(list,0,list.length - 1); } public static void quickSort(int[] list,int first,int last) { if(last > first) { //划分左右子数组,返回主元的索引 int pivotIndex = patition(list,first,last); quickSort(list,first,pivotIndex - 1); quickSort(list,pivotIndex + 1,last); } } //partition list into list1 and list2 private static int patition(int[] list, int first, int last) { //选择主元元素pivot,为了便于理解,选择数组中的第一个元素作为主元元素 int pivot = list[first]; int low = first + 1; int high = last; while(high > low) { //从左侧查找第一个大于主元的元素 while(low <= high && list[low] <= pivot) low++; //从右侧查找第一个小于主元的元素 while(low <= high && list[high] > pivot) high--; //交换着两个元素 if(high > low) { int temp = list[high]; list[high] = list[low]; list[low] = temp; } } while(high > first && list[high] >= pivot) high--; if(pivot > list[high]) {//判定是否交换主元 list[first] = list[high]; list[high] = pivot; return high; } return first; } }
算法评价
- 快速排序算法是不稳定的
对待排序序列 49 49' 38 65, 快速排序结果为: 38 49' 49 65
- 快速排序的性能跟初始序列中关键字的排列和选取的枢纽有关
- 当初始序列按关键字有序(正序或逆序)时,性能最差,蜕化为冒泡 排序,时间复杂度为O(n2 )
- 常用“三者取中”法来选取划分记录,即取首记录list[first].尾记录 list[last]和中间记录list[(first + last) / 2]三者的中间值为划分记录。
- 快速排序算法的平均时间复杂度为O(nlogn)
请尝试用三者取中法完成快速排序,并编写程序与取第一个元素为枢纽的快速排序方法进行比较测试。然后仔细研究快排还可以做哪些改进!

桶排序
基数排序
外部排序
