
transformer-3
1. Self Attention
-
先计算权重:

-
再计算加权和

假设某个句子拆分词,每个词对应(k,q,v),那就是该词和剩余词的attention_score加权v, attention_score就是当前词k和其他词的v计算的标量。
2. Scaled-dot-product

主要解释一下为何要scaled:
softmax求导:
从上面性质可以知道,softmax一般和交叉熵损失函数搭配
softmax函数引入指数,会拉大差距;某个值比较大,越接近1
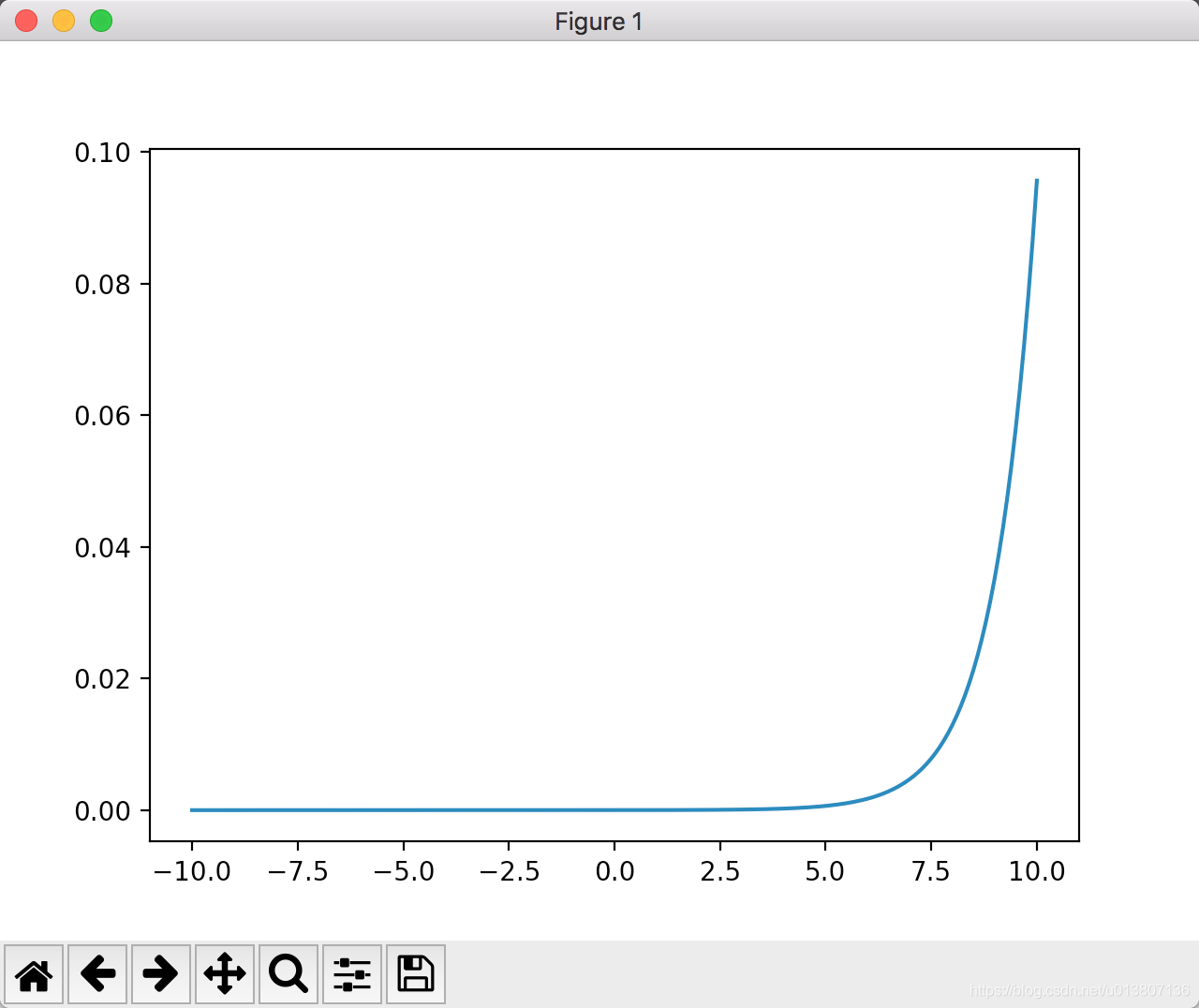
所以对
仅以第i行进行讨论, 当
3. Multihead Attention
多头注意力机制,多头类似图像中的多个channel,对应不同的功能。有点类似于多个专家头一样,聚焦于不同的核心。
4. 代码部分
import numpy as np import torch from torch import Tensor from typing import Optional, Any, Union, Callable import torch.nn as nn import torch.nn.functional as F import math, copy, time class MultiHeadedAttention(nn.Module): def __init__(self, num_heads: int, d_model: int, dropout: float=0.1): super(MultiHeadedAttention, self).__init__() assert d_model % num_heads == 0, "d_model must be divisible by num_heads" # Assume v_dim always equals k_dim self.k_dim = d_model // num_heads self.num_heads = num_heads self.proj_weights = clones(nn.Linear(d_model, d_model), 4) # W^Q, W^K, W^V, W^O self.attention_score = None self.dropout = nn.Dropout(p=dropout) def forward(self, query:Tensor, key: Tensor, value: Tensor, mask:Optional[Tensor]=None): """ Args: query: shape (batch_size, seq_len, d_model) key: shape (batch_size, seq_len, d_model) value: shape (batch_size, seq_len, d_model) mask: shape (batch_size, seq_len, seq_len). Since we assume all data use a same mask, so here the shape also equals to (1, seq_len, seq_len) Return: out: shape (batch_size, seq_len, d_model). The output of a multihead attention layer """ if mask is not None: mask = mask.unsqueeze(1) batch_size = query.size(0) # 1) Apply W^Q, W^K, W^V to generate new query, key, value query, key, value \ = [proj_weight(x).view(batch_size, -1, self.num_heads, self.k_dim).transpose(1, 2) for proj_weight, x in zip(self.proj_weights, [query, key, value])] # -1 equals to seq_len # 2) Calculate attention score and the out out, self.attention_score = attention(query, key, value, mask=mask, dropout=self.dropout) # 3) "Concat" output out = out.transpose(1, 2).contiguous() \ .view(batch_size, -1, self.num_heads * self.k_dim) # 4) Apply W^O to get the final output out = self.proj_weights[-1](out) return out def clones(module, N): "Produce N identical layers." return nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) def attention(query: Tensor, key: Tensor, value: Tensor, mask: Optional[Tensor] = None, dropout: float = 0.1): """ Define how to calculate attention score Args: query: shape (batch_size, num_heads, seq_len, k_dim) key: shape(batch_size, num_heads, seq_len, k_dim) value: shape(batch_size, num_heads, seq_len, v_dim) mask: shape (batch_size, num_heads, seq_len, seq_len). Since our assumption, here the shape is (1, 1, seq_len, seq_len) Return: out: shape (batch_size, v_dim). Output of an attention head. attention_score: shape (seq_len, seq_len). """ k_dim = query.size(-1) # shape (seq_len ,seq_len),row: token,col: that token's attention score scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(k_dim) if mask is not None: scores = scores.masked_fill(mask == 0, -1e10) attention_score = F.softmax(scores, dim = -1) if dropout is not None: attention_score = dropout(attention_score) out = torch.matmul(attention_score, value) return out, attention_score # shape: (seq_len, v_dim), (seq_len, seq_lem) if __name__ == '__main__': d_model = 8 seq_len = 3 batch_size = 6 num_heads = 2 # mask = None mask = torch.tril(torch.ones((seq_len, seq_len)), diagonal = 0).unsqueeze(0) input = torch.rand(batch_size, seq_len, d_model) multi_attn = MultiHeadedAttention(num_heads = num_heads, d_model = d_model, dropout = 0.1) out = multi_attn(query = input, key = input, value = input, mask = mask) print(out.shape)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 从HTTP原因短语缺失研究HTTP/2和HTTP/3的设计差异
· 三行代码完成国际化适配,妙~啊~