R语言 股票数据获取比较 quantmod、tidyquant、pedquant
金融市场充满数据。这些数据既包括了如各种金融资产(股票、外汇、衍生品、电子货币等)的交易数据、企业的财务数据、经济统计数据等等传统的数据类型,也包括了随着各种新技术而出现的另类数据,如卫星图像、文本和社交媒体情绪、移动通信设备的地理定位信息。市场的参与者,无论是交易者、服务商还是监管机构,如今都要面对随这个时代滚滚而来的数据洪流。善用数据者,必有所获。
从最传统的金融数据——股票价格开始,介绍一些工具和方法。
高质量的金融数据往往来自于付费的渠道:专业的交易软件、资讯软件(如万得)或专业数据库(如国泰安)。这些专业化的数据来源往往价格不菲。从学习或个人化研究的角度,我们还是希望从开源或免费的渠道获取金融数据。使用R语言获取免费金融数据主要由这样一些途径:
- 使用一些R包通过财经网站API获取数据
- 通过一些量化平台数据接口获取免费数据
- 直接进行网络抓取
- 读取交易软件(如通达信)或数据库导出的外部文件
对所有的可能性进行全面总结是很困难的。在本节,我们通过一些示例对这些途径进行探索。
1、使用R包获取数据
(1) quantmod包
有多个可以用来读取金融数据的R包。其中,quantmod包算得上是一种“历史悠久”的传统手段。quantmod包主要通过函数getSymbols(),从多种来源获取多种金融资产的历史数据。下面,我们读取上交所上市公司招商银行(600036)的历史数据,时间从2019年1月1日到2020年9月30日:
library(quantmod)
zsyh_quant<-getSymbols("600036.ss",scr=yahoo,from="2019-01-01",
to="2020-10-01",auto.assign=F)
###查看数据
head(zsyh_quant,n=3)
## 600036.SS.Open 600036.SS.High 600036.SS.Low 600036.SS.Close 600036.SS.Volume
##2019-01-02 25.15 25.20 24.40 24.57 55516612
##2019-01-03 24.40 25.05 24.38 24.88 37410758
##2019-01-04 24.76 25.65 24.65 25.51 66853140
## 600036.SS.Adjusted
##2019-01-02 23.20724
##2019-01-03 23.50005
##2019-01-04 24.09511
tail(zsyh_quant,n=3)
## 600036.SS.Open 600036.SS.High 600036.SS.Low 600036.SS.Close 600036.SS.Volume
##2020-09-28 37.20 37.65 37.05 37.25 35324476
##2020-09-29 37.35 37.45 36.27 36.31 79668910
##2020-09-30 36.30 36.57 35.80 36.00 65466059
## 600036.SS.Adjusted
##2020-09-28 37.25
##2020-09-29 36.31
##2020-09-30 36.00getSymbols函数需要通过股票代码(symbols)读取相应股票的价格数据,数据来源是雅虎财经yahoo!Finance(src = 'yahoo')。在雅虎财经上,中国股票的代码使用“交易代码+市场”的形式,“ss”表示上证,“sz”表示深证,比如,上证指数就是“000001.ss”,招商银行就是“600036.ss”。然后,再指定需要的起止时间(“from”和“to”)。参数auto.assign指派为FALSE,这样可以将结果返回到对象szyh_quant当中;如果不希望出现大段的警告信息,可以将参数warnings指派为FALSE。
可以使用head()(或tail())函数对获取的数据进行查看,返回zsyh_quant的前n行(或后n行,默认是6行)数据。可以看到,对象zsyh_quant共有六列,分别对应股票的开盘价(Open)、最高价(High)、最低价(Low)、收盘价(Close)、成交量(Volumn)以及调整价格(Adjusted,根据拆股、分红调整后的复盘价格)。
使用从quantmod包获取的中国股市的数据需要注意,可能会有一些记录错误或者缺失值的情况(比如,在美国的一些公共假日)出现。
(2)tidyquant包
quantmod包获取的数据zsyh_quant是一个xts对象(可以使用str()进行查看)。xts对象是R语言中较早期出现的一种时间序列数据对象,虽然xts对象在R中的使用曾经相当广泛,但与R中目前主流的tidyverse数据处理框架不兼容,这就给分析的效率带来了一定困扰。tidyquant包的出现,解决了这个问题。
tidyquant使用了基于tidyverse的整洁数据架构,将原本建立在xts对象基础上的xts包(时间序列数据处理)、quantmod包(金融数据获取和处理)、TTR包(股票技术分析)和performanceAnalytics包(投资绩效评价)等工具整合在一起,实现了这些R包与tidyverse的无缝交互。它拥有的核心函数虽然数量不多,但功能强大,同时可以还使用tidyverse系列R包中的数据处理工具对金融数据进行处理和建模,也可以使用ggplot2进行可视化。
tidyquant包获取资产价格数据的函数是tq_get(),它是对getSymbols的封装:
zsyh_tq <- tq_get("600036.ss", get = "stock.prices", from = " 2019-01-01",
to='2020-09-30')
head(zsyh_tq,n=3)
### A tibble: 3 x 8
## symbol date open high low close volume adjusted
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
##1 600036.ss 2019-01-02 25.2 25.2 24.4 24.6 55516612 23.2
##2 600036.ss 2019-01-03 24.4 25.0 24.4 24.9 37410758 23.5
##3 600036.ss 2019-01-04 24.8 25.6 24.6 25.5 66853140 24.1
tail(zsyh_tq,n=3)
### A tibble: 3 x 8
## symbol date open high low close volume adjusted
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
##1 600036.ss 2020-09-28 37.2 37.7 37.0 37.2 35324476 37.2
##2 600036.ss 2020-09-29 37.3 37.5 36.3 36.3 79668910 36.3
##3 600036.ss 2020-09-30 36.3 36.6 35.8 36 65466059 36
获取的数据zsyh_tq是一个tibble对象,可以直接使用tidyverse系列R包进行处理。
(3)pedquant包
quantmod和tidyquant对A股的支持不是特别理想。对于A股,pedquant包是一个更好的选择。“pedquant”意指”公共经济数据和量化分析“(Public Economic Data and Quantitative Analysis)。penquant提供了对国内和国际金融数据和经济数据的访问接口,数据来源包括中国国家统计局(NBS)、FRED、雅虎财经、163财经等。同时,pedquant还提供了一些基本的图形和分析工具。
pedquant包使用md_stock()获取股票数据:
library(pedquant)
zsyh_pd163<-md_stock("600036.ss",from='2019-01-01',to='2020-10-01',source="163",adjust=NULL)
##1/1 600036.ss
###转化为tibble对象
zsyh_pd163_tidy<-zsyh_pd163[[1]]%>%
as_tibble()%>%
select(symbol,date,open,high,low,close,volume)
head(zsyh_pd163_tidy,n=3)
### A tibble: 3 x 7
## symbol date open high low close volume
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
##1 600036.SS 2019-01-02 25.2 25.2 24.4 24.6 55516612
##2 600036.SS 2019-01-03 24.4 25.0 24.4 24.9 37410758
##3 600036.SS 2019-01-04 24.8 25.6 24.6 25.5 66853140
tail(zsyh_pd163_tidy,n=3)
### A tibble: 3 x 7
## symbol date open high low close volume
## <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
##1 600036.SS 2020-09-28 37.2 37.6 37.0 37.2 35324476
##2 600036.SS 2020-09-29 37.4 37.4 36.3 36.3 79668910
##3 600036.SS 2020-09-30 36.3 36.6 35.8 36 65466059md_stock()从网易财经(source="163")获取了招商银行的历史价格数据。zsyh_pd163本身是一个列表,我们需要将它的第一个成分取出,然后通过as_tibble()将其转换为tibble对象。注意在参数adjust=NULL时,获取的是未复权的原始数据。adjust的默认值是split(拆股),adjust取值为dividend时,获取的是包含了拆股和分红的前复权数据:
zsyh_pd163_1<-md_stock("600036.ss",from='2019-01-01',to='2020-10-01',source="163",adjust="dividend")
##1/1 600036.ss
zsyh_pd163_tidy1<-zsyh_pd163_1[[1]]%>%
as_tibble()%>%
select(symbol,date,open,high,low,close,volume)
> head(zsyh_pd163_tidy1,n=3)
# A tibble: 3 x 7
symbol date open high low close volume
<chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 600036.SS 2019-01-02 23.0 23.1 22.3 22.4 55516612
2 600036.SS 2019-01-03 22.3 22.9 22.2 22.7 37410758
3 600036.SS 2019-01-04 22.6 23.5 22.5 23.4 66853140
> tail(zsyh_pd163_tidy1,n=3)
# A tibble: 3 x 7
symbol date open high low close volume
<chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl>
1 600036.SS 2020-09-28 37.2 37.6 37.0 37.2 35324476
2 600036.SS 2020-09-29 37.4 37.4 36.3 36.3 79668910quantmod和tidyquant的复权价格只是对收盘价格来做的,而pedquant的前复权数据是对OHLC这四个变量同时来做的。
2、通过量化平台的接口获取数据
A股数据也可以通过国内的一些量化交易服务平台的数据接口来获取。
(1)Tushare
开源金融数据平台Tushare为R语言提供了数据接口,可以通过平台开发的R包Tushare获取数据:https://tushare.pro/document/1?doc_id=133
使用Tushare的数据接口,需要注册并获得token。以Tshuare的pro_bar接口(复权行情)为例,首先需要获取pro_bar接口(此时需要token),再读取数据:
library(Tushare)
bar<-Tpro_bar(token="xxxx")##输入你的token
zsyh_tushare<-bar(ts_code = "600036.SH", start_date = "20190101", end_date = "20200930")
###查看数据情况:
head(zsyh_tushare,n=3)
## ts_code trade_date open high low close pre_close change pct_chg vol
##1 600036.SH 20200930 36.30 36.57 35.80 36.00 36.31 -0.31 -0.8538 654660.59
##2 600036.SH 20200929 37.35 37.45 36.27 36.31 37.25 -0.94 -2.5235 796689.1
##3 600036.SH 20200928 37.20 37.65 37.05 37.25 37.18 0.07 0.1883 353244.76
##amount
##1 2365489.193
##2 2920847.323
##3 1317478.208
tail(zsyh_tushare,n=3)
## ts_code trade_date open high low close pre_close change pct_chg vol
##425 600036.SH 20190104 24.76 25.65 24.65 25.51 24.88 0.63 2.5322 668531.4
##426 600036.SH 20190103 24.40 25.05 24.38 24.88 24.57 0.31 1.2617 374107.58
##427 600036.SH 20190102 25.15 25.20 24.40 24.57 25.20 -0.63 -2.5 555166.12
## amount
##425 1690412.096
##426 929035.565
##427 1368988.405这里获取的是未复盘的原始数据。可见,zsyh_tushare是按时间倒序排列的。获取前复权数据,需设置参数adj = "qfq"(后复权为“hfq”):
zsyh_tushare1<-bar(ts_code = "600036.SH", start_date = "20190101", end_date="2020-09-30,
adj = "qfq")
tail(zsyh_tushare1,n=3)
## ts_code trade_date open high low close pre_close change pct_chg vol
##425 600036.SH 20190104 23.39 24.23 23.28 24.09 23.50 0.63 2.5322 668531.4
##426 600036.SH 20190103 23.05 23.66 23.03 23.50 23.21 0.31 1.2617 374107.58
##427 600036.SH 20190102 23.75 23.80 23.05 23.21 23.80 -0.63 -2.5 555166.12
## amount
##425 1690412.096
##426 929035.565
##427 1368988.405
head(zsyh_tushare1,n=3)
## ts_code trade_date open high low close pre_close change pct_chg vol
##1 600036.SH 20200930 36.30 36.57 35.80 36.00 36.31 -0.31 -0.8538 654660.59
##2 600036.SH 20200929 37.35 37.45 36.27 36.31 37.25 -0.94 -2.5235 796689.1
##3 600036.SH 20200928 37.20 37.65 37.05 37.25 37.18 0.07 0.1883 353244.76
## amount
##1 2365489.193
##2 2920847.323
##3 1317478.208Tushare开源免费,但是采用积分制,使用R接口获取数据有一定的限制。
(2) 聚宽JoinQuant
在线量化交易平台聚宽也提供了面向R的数据接口。使用聚宽的数据接口,需要注册并申请数据使用,聚宽没有开发R包,而是给出了一个请求数据的函数request:
request <- function(method,list=FALSE,...){
#获取调用凭证
url <- "https://dataapi.joinquant.com/apis"
body <- list(
method = "get_token",
mob = "xxxx", #手机号
pwd = "xxxx" #密码
)
r <- POST(url, body = body, encode = "json")
token <- content(r)
body1 <- list(
method = method,
token = token,
...
)
r1 <- POST(url, body = body1, encode = 'json')
if(method == 'get_fund_info'){
result = fromJSON(content(r1))
return(result)
}else{
if(list==F){
df <- data.frame(read_csv(content(r1)),check.names = T)
return(df)
}else{
l <- strsplit(content(r1),'\n')
return(l)
}
}
}下面分别获取未复权和前复权(需指定复权基准日)的历史数据:
###未复权
zsyh_jq <- request('get_price',code='600036.XSHG',count=427,unit='1d',
end_date='2020-09-30')
head(zsyh_jq,n=3)
## date open close high low volume money paused high_limit low_limit
##1 2019-01-02 25.15 24.57 25.20 24.40 55516612 1368988405 0 27.72 22.68
##2 2019-01-03 24.40 24.88 25.05 24.38 37410758 929035565 0 27.03 22.11
##3 2019-01-04 24.76 25.51 25.65 24.65 66853140 1690412096 0 27.37 22.39
## avg pre_close
##1 24.66 25.20
##2 24.83 24.57
##3 25.29 24.88
###前复权
zsyh_jq1 <- request('get_price',code='600036.XSHG',count=427,unit='1d',
end_date='2020-09-30',fq_ref_date='2020-09-30')
head(zsyh_jq,n=3)
## date open close high low volume money paused high_limit low_limit
##1 2019-01-02 23.76 23.21 23.80 23.05 58776605 1368988405 0 26.18 21.42
##2 2019-01-03 23.05 23.50 23.66 23.03 39607556 929035565 0 25.53 20.88
##3 2019-01-04 23.39 24.10 24.23 23.28 70778826 1690412096 0 25.85 21.15
## avg pre_close
##1 23.29 23.80
##2 23.46 23.21
##3 23.88 23.50聚宽提供的数据种类比较多,问题是免费期限只有1年。
3、数据质量的讨论
在前面两个小节,我们不厌其烦地将获取的数据内容进行了展示。这样做的目的既是为了展示所获取的每个数据集的具体情况,也是为了对这些从不同渠道获取的股票价格数据进行比较。
我们讨论这些数据中的两个问题。
(1)quantmod/tidyquant的缺陷
使用quantmod/tidyquant获取A股股票数据是可能存在缺陷的。对我们的例子,使用nrow()可以发现这两种方法获取的招商银行股价只有425行,而其余几种方法有427行。这就意味着由这两种方法所获取的来自yahoo的A股数据存在缺失值。那么,缺失的是哪两天的数据呢?
zsyh_pd163_tidy$date[which(zsyh_pd163_tidy$date %in%zsyh_tq$date==F)]
##[1] "2019-04-29" "2019-04-30"(2)前复权的问题
再来看pedquant、Tushare、聚宽三种方法。从上一小节所展示的数据结果可见,我们对这三种方法都取了复权数据(都是前复权),其中Tushare和聚宽的结果是一致的,而pedquant的结果则明显不同。通过一个可视化的比较,这种差异会相当明显(图1):
box_adj%>%
pivot_longer(everything())%>%
ggplot(aes(x=name,y=value))+
geom_boxplot(aes(col=name))+
theme_bw()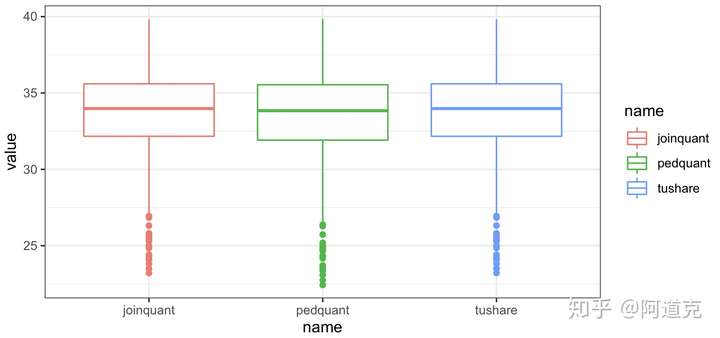 图1
图1
由这三个箱形图可见,pedquant包获取的招商银行前复权数据明显取值要低一些。
前复盘是有多种方法的。显然,pedquant采用的前复权和Tusahre、聚宽的前复权方法是不同的。在讨论之前,我们需要有招商银行的分红配股情况。使用网络抓取的方法(利用R包rvest),可以从新浪财经获取招商银行的分红配股情况(参见图2):
library(rvest)
##链接
url<-'http://money.finance.sina.com.cn/corp/go.php/vISSUE_ShareBonus/stockid/600036.phtml'
##抓取
dividend_sina<-read_html(url)
##分红
dividend_sinatable<-dividend_sina%>%
html_nodes("#sharebonus_1")%>%
html_table(fill=T)
dividend_sinatable
##[[1]]
## 分红 分红 分红 分红 分红 分红
##1 公告日期 分红方案(每10股) 分红方案(每10股) 分红方案(每10股) 进度 除权除息日
##2 公告日期 送股(股) 分红方案(每10股) 分红方案(每10股) 进度 除权除息日
##3 2020-07-03 0 0 12 实施 2020-07-10
##4 2019-07-05 0 0 9.4 实施 2019-07-12
##5 2018-07-05 0 0 8.4 实施 2018-07-12
#####下略
分红 分红 分红
##1 股权登记日 红股上市日 查看详细
##2 股权登记日 转增(股) 派息(税前)(元)
##3 2020-07-09 -- 查看
##4 2019-07-11 -- 查看
##5 2018-07-11 -- 查看
#####下略
###配股
dividend_sinatable2<-dividend_sina%>%
html_nodes("#sharebonus_2")%>%
html_table(fill=T)
dividend_sinatable2
##[[1]]
## 配股 配股 配股 配股 配股 配股
##1 公告日期 配股方案(每10股配股股数) 配股价格(元) 基准股本(股) 除权日 股权登记日
##2 2013-08-23 1.74 9.29 17666100000 2013-09-05 2013-08-27
##3 2010-03-02 1.3 8.85 15658900000 2010-03-15 2010-03-04
## 配股 配股 配股 配股 配股
##1 缴款起始日 缴款终止日 配股上市日 募集资金合计(元) 查看详细
##2 2013-08-28 00:00:00 2013-09-03 2013-09-11 查看
##3 2010-03-05 00:00:00 2010-03-11 2010-03-19 查看图\
可见,在我们所取的时间区间内(2019-01-01到2020-09-30),招商银行只进行过两次分红。简单起见,我们只考虑最新一次分红所影响的复权问题,即考察2019-07-12到2020-07-09这个时间区间。
简单观察数据就可以发现,pedquant采取的是一种简单的前复权方法,即从除权除息日的前一天(2020-07-09)开始,每一天的原始价格都减去分红的金额1.2元:
##原始价格
pd163_original<-zsyh_pd163[[1]]%>%
filter(date>='2019-07-12'& date<='2020-07-09')
##前复权价格
pd163_adj<-zsyh_pd163_1[[1]]%>%
filter(date>='2019-07-12'& date<='2020-07-09')
##比较:
head(pd163_original$close-1.2,n=3)
##[1] 34.20 34.10 34.11
head(pd163_adj$close,n=3)
##[1] 34.20 34.10 34.11这样的好处是简单,有些交易软件也是采用的这样一种方法(比如通达信)。缺点是,使用这种复盘数据计算涨跌幅与实际交易日真实的涨跌幅是不同的)。md_stock()函数也给出了真实的涨跌幅change_pct,读者可自行验证。
为了保证前复权之后真实涨跌幅不变,我们考虑采用下面这种方法:
(i)除权除息日的前一日价格减去分红金额
(ii)更早的前复权价格采用迭代的方式计算:
第t日的前复权收盘价/第t-1日的前复权收盘价 = 1+第t日的真实涨跌幅:
l<-nrow(pd163_original)
adj_price<-rep(0,l)
adj_price[l]<-pd163_original[l,]$close-1.2
for(i in (l-1):1){
adj_price[i]=adj_price[i+1]/(1+0.01*pd163_original$change_pct[i+1]) 将得到的价格与聚宽的前复权价格进行比较,两者一致了:
head(adj_price)
##[1] 34.33577 34.23877 34.24846 34.15147 34.25816 35.27658
jq_adj<-zsyh_jq1%>%
filter(date>='2019-07-12'& date<='2020-07-09')
head(jq_adj$close)
##[1] 34.34 34.24 34.25 34.15 34.26 35.28实际上,聚宽或Tushare是采用了某种复权因子方法计算前复权价格的,这里不再做过多讨论。
4、网络抓取数据的几个例子
R语言提供了丰富的网络抓取工具,我们可以利用这些工具从财经网站提供的链接或数据接口抓取数据。上一小节对招商银行的分红信息进行了抓取,下面再介绍两个简单的例子。
(1) 获取分时K线
利用新浪接口http://money.finance.sina.com.cn/quotes_service/api/json_v2.php/CN_MarketData.getKLineData?symbol=[市场][股票代码]&scale=[周期]&ma=no&datalen=[长度]可以获取5、10、30、60分钟K线的JSON数据。这个接口最多可以获取1023个数据点。
R中有多个包可以获取和解析JSON数据,我们使用jsonlite包进行尝试:
library(jsonlite)
stock_price<-read_json(url)
###stock_price对象中有580个列表,其中每个列表是一个单行的数据框,使用bind_rows把这些数据框按行合并
stock_price_tbl<-bind_rows(stock_price)
stock_price_tbl[,2:6]<-apply(stock_price_tbl[,2:6],2,as.numeric)
head(stock_price_tbl)
# A tibble: 6 x 8
day open high low close volume ma_price5 ma_volume5
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
1 2020-03-04 10:30:00 34.7 34.8 34.5 34.6 18313218 NA NA
2 2020-03-04 11:30:00 34.6 34.7 34.4 34.5 13973189 NA NA
3 2020-03-04 14:00:00 34.5 34.7 34.5 34.6 10517151 NA NA
4 2020-03-04 15:00:00 34.6 34.8 34.5 34.8 13269148 NA NA
5 2020-03-05 10:30:00 35.0 35.2 34.8 35.2 24404082 34.7 16095358
6 2020-03-05 11:30:00 35.1 35.8 35.1 35.8 48720616 35.0 22176837我们将获取的60分钟K线数据整理成一个tibble数据框,可见其中包含了K线的OHLC信息,成交量以及一条均线。
这个数据的长度大约为半年。
(2)历史成交明细
网易链接:http://quotes.money.163.com/cjmx/[今年年份]/[日期]/[股票代码].xls提供了历史交易明细的xls文件,这是一个直接从网页下载的文件,可以使用download.file()进行读取:
url3<-'http://quotes.money.163.com/cjmx/2020/20200929/0600036.xls'
download.file(url3,destfile='600036.xls')参数destfile指定了下载的xls文件存储的路径和文件名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号