
sqlserver调优-索引
话题背景,前几天一个同事,碰到一个问题,说hangfire有个坑,丢任务。我当时很惊讶,就回了一句基本不会丢任务,除非hangfire退出服务或者任务非常多,并且hangfire数据库延时比较大的情况下才会发生。当时我在处理别的问题,也就没有跟他一起去看这个问题。待手上的任务完成之后,我就顺便过去跟他一起看了下代码(因为我也想看看到底是不是hangfire的锅),看了他的代码之后,我们通过简单的分析,把这个问题的源头定在了mysql数据库。可能说的有点无厘头,我简单描述下整个业务场景吧。这里简单分为四个角色,hangfire rabbitmq consumer mysql,而它们之间的关系是hangfire定时写任务到mq,mq推消息到consumer(mq为自动确认机制),consumer通过一系列的业务操作写入mysql。整个操作的源头是hangfire,所以自然很容易就想到hangfire是不是丢任务或者不执行了?其实这个问题,只要hangfire和mq不宕机,应该就是consumer的锅了,当时是测试同事在做压测,后面我们仔细看代码发现,consumer里面的业务处理还是比较复杂的,各种查、添和改操作,又因为mq自动确认,所以consumer由于处理数据过大导致数据库高延时而最终数据库性能急剧下降。
索引在MSSQL数据库里面有两种索引,聚集和非聚集两种,我们先看下聚集索引。
聚集索引聚集索引是指数据库表行中数据的物理顺序与键值的逻辑(索引)顺序相同。一个表只能有一个聚集索引,因为一个表的物理顺序只有一种情况,所以,对应的聚集索引只能有一个。如果某索引不是聚集索引,则表中的行物理顺序与索引顺序不匹配,与非聚集索引相比,聚集索引有着更快的检索速度(来源百度百科)。其实现方式是通过B+树结构实现,B+树这种数据结构,百度有很多,大家讨论的无非就两点,特点和增删改查。它就是一颗平衡多路搜索树,如果是刚接触它,你可以按二叉平衡树的方式去理解,更通俗一点的理解就是我们用的词典,拼音首字母就可以理解为聚集索引。注意B+树的数据是在叶子节点各叶子节点通过链表有序存放,而节点存储的是聚集索引列的值。
非聚集索引该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同(来源百度百科)。非聚集索引同样基于B树实现,非聚集索引的叶层不包含数据页。 相反,叶节点包含索引行。每个索引行包含非聚集键值以及一个或多个行定位器,这些行定位器指向有该键值的数据行(如果索引不唯一,则可能是多行)。下面我们通过实例来说吧。
我这边的实例就图个方便,用的是hangfire的表,数据是自己造的,三张关系表如下:
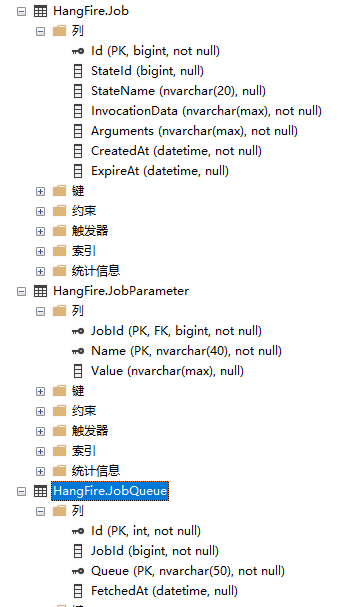
如上就是三张关系表的基本接结构,字段不多,我们先从job表开始吧,这张表我已经把聚集和非聚集索引全部删除掉了,就只留下一个主键。我们先看下最简单的查询,没有where条件的,看看执行计划是什么样的。
单表查询
SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] FROM [Hangfire.Sample].[HangFire].[Job]
下面是查询结果和执行计划
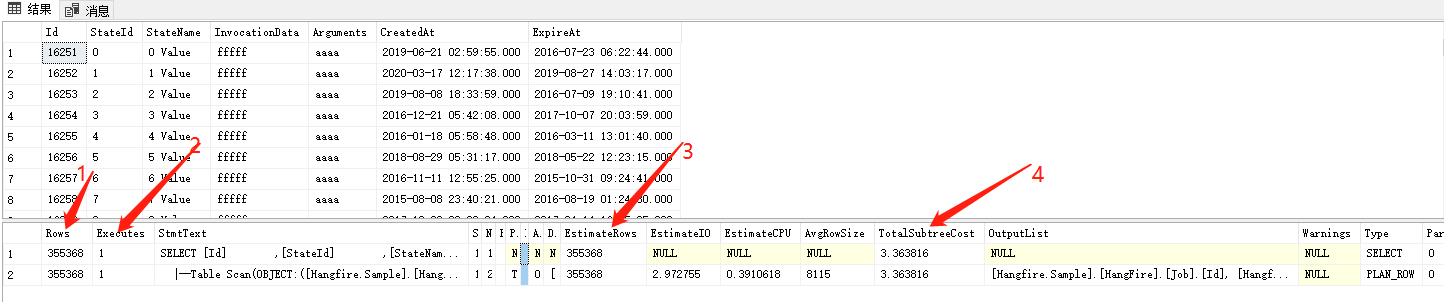
在执行计划这张表格里面比较重要的字段我有标注。
1.每个步骤实际返回的行数,2.是每个步骤实际执行的次数,3.是每个步骤预计返回的行数,4.根据io和cpu字段通过公式计算出来的cost总和(包括自己和下层步骤),这里还有一个最重要的字段stmtText,我没有标注,他就是我们的执行计划的具体内容。指标解析就到这吧,后续会细说这些指标以及跟统计信息的关系,因为它们的值直接受统计信息影响,而它们又直接影响查询性能。
我们现在把关注点放在执行计划内容里面吧,一个select * from 表,sqlserver直接通过表扫描查询,Table Scan。现在我们把这张表字段id添加聚集索引,再看执行计划。
1 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 2 FROM [Hangfire.Sample].[HangFire].[Job]

同样的sql查询语句,现在的执行计划内容变成了聚集索引扫描,clustered index scan,不要被index字样迷惑了,效率是一样的没有区别,唯一的区别是table scan表示数据表里面没有聚集索引。下面我们可以简单通过底层数据结构来看。
堆表这样展示更直观吧

聚集索引扫描

下面我们在where里面添加条件,条件字段为聚集索引字段,看看具体效果。
1 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 2 FROM [Hangfire.Sample].[HangFire].[Job] where id = 16251 3 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 4 FROM [Hangfire.Sample].[HangFire].[Job] where id in (16251,16252,16253)
两条查询语句,第一条是id=,第二条是id in,具体看计划
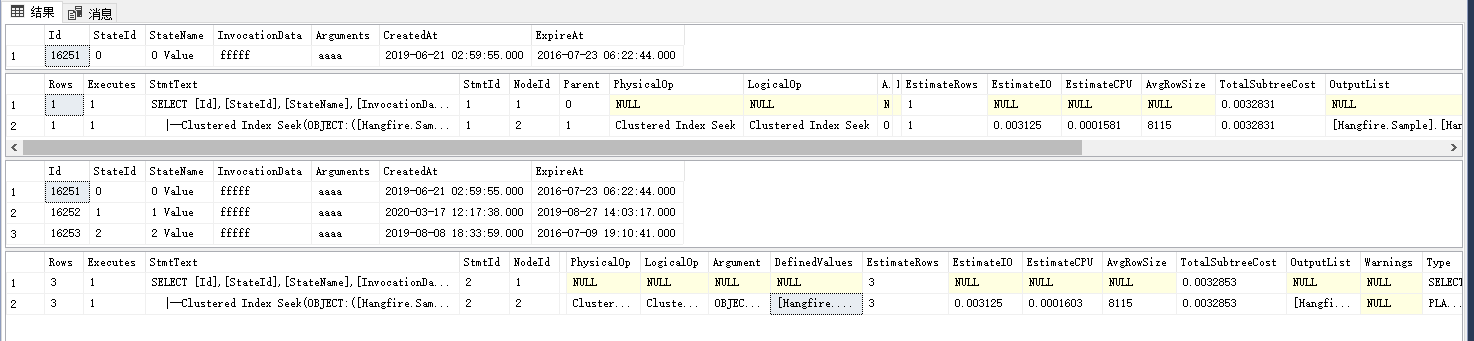
我们直接看计划内容,两条查询语句都使用了聚集索引seek查找,其实也很容易理解,就是通过B+树的查找实现,下面我们看下<>操作。
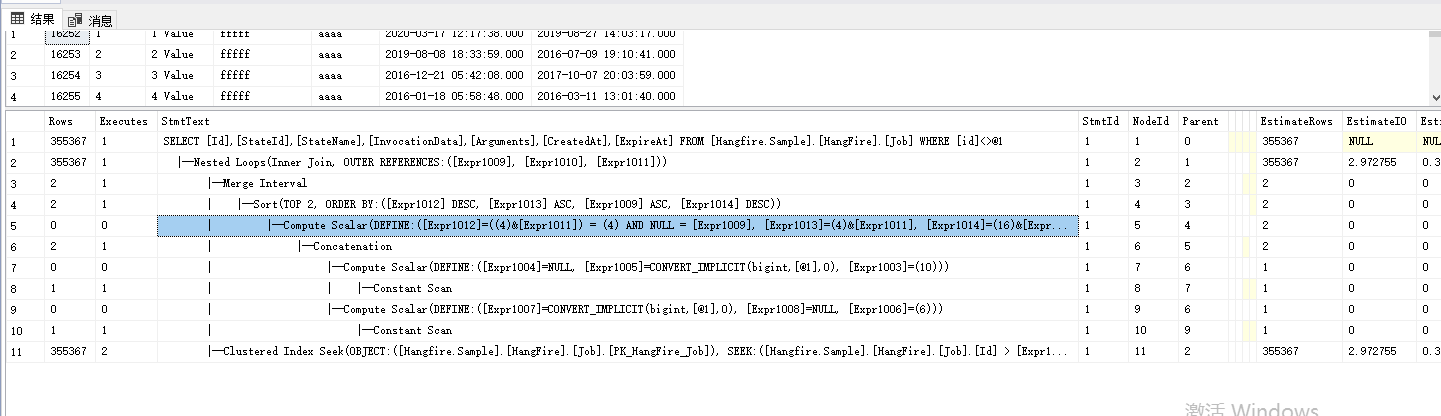
这个执行计划比上面的要稍微复杂点,我先简单说下怎么看这个执行计划。执行计划其实就是一颗树,执行的顺序是从里到外,同层次的节点是从上到下。在这个执行计划里面先是根据用户输入构造常量行列再合并-》再通过聚集索引查找seek数据,执行了两次,sqlserver很聪明,其实际就是把<>分为>和<执行,-》最后再nested loops并且把常量行作为outer,然后输出表格结果。整个计划的执行大概就是这样的,上面的查询计划里面有几个出现次数比较多的操作符,我大概简单介绍下。1.Constant Scan翻译过来为常量扫描运算符,其实际就是生成数据行但是当前没有列,2.Compute Scalar 标量计算操作符,它主要是计算表达式值(你可以看后面的define定义表达式)可以返回输出也可以提供给其他计划查询,10行和9行的意思就是先创建数据行然后通过计算表达式获得的值填充到这个行的列。3.Concatenation为串联操作符,可以理解union all,在这里就是和并下面的行。这里建议尽量少用<> not 等操作符。下面我们看下单表非聚集索引的执行计划。
我们为job表添加一个非聚集索引,字段stateName,下面我们通过它来查询,看看计划到底怎么样的。
1 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 2 FROM [Hangfire.Sample].[HangFire].[Job] where StateName='4 Value'
执行计划
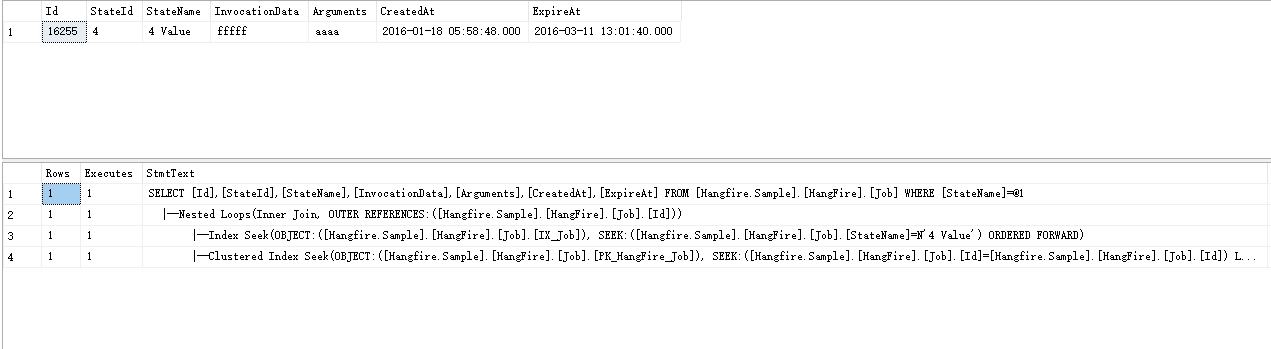
先通过非聚集索引seek到一条数据,这条数据有两个值statename和id(聚集索引字段,因为非聚集在建索引的时候做了映射),然后通过id在聚集索引上seek到一条数据,为什么要这样做?因为其他的检索列不在里面,所以其他的建索列需要到聚集索引上面的叶子节点里面获取,最后做了个loops,把两个结果集合并起来,可以通过图形执行计划看到两次seek的输出具体字段也可以看outputlist字段。
我们为job表再添加一条非聚集索引,索引字段为ExpireAt,该字段为时间类型,我们看下查询计划是什么样子的。
1 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 2 FROM [Hangfire.Sample].[HangFire].[Job] where ExpireAt > '2016-05-18 14:15:43.000' and ExpireAt<'2016-05-22 02:59:19.000'
执行计划

输出的行数是667行,还是通过索引seek,但是loops的代价有点大,做了667次。我们稍微改下查询条件,输出更多的行,看看计划又是什么样的。
1 SELECT [Id],[StateId],[StateName],[InvocationData],[Arguments],[CreatedAt],[ExpireAt] 2 FROM [Hangfire.Sample].[HangFire].[Job] where ExpireAt > '2016-05-18 14:15:43.000'
执行计划
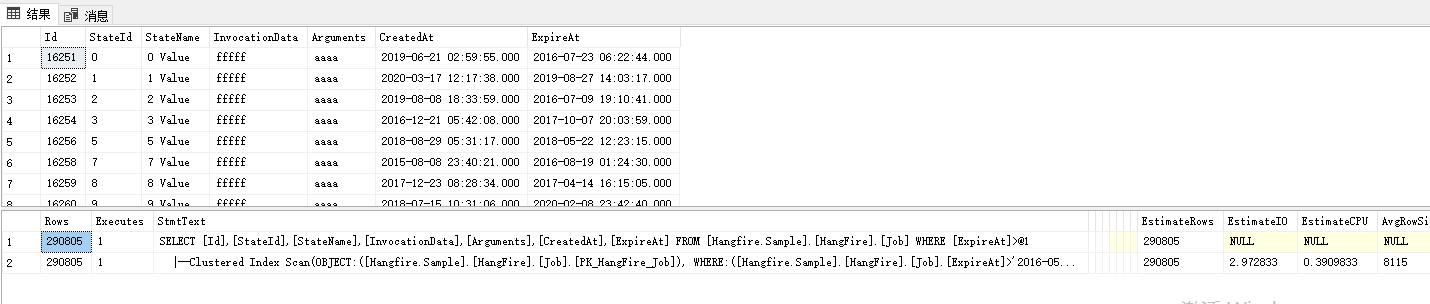
同样是用非聚集索引ExpireAt做where查询,这次的执行计划就完全不同了,聚集索引scan扫描,为什么我用了非聚集索引字段怎么还是scan呢?其实这个地方如果用索引seek性能更差,会发生290805次loop,所以sqlserver直接选择scan。为什么sqlserver会根据输出数据量使用不同的执行计划?这个问题就是我前面说的统计信息,这部分后面再说。还有个细节问题,如果检索字段包含在非聚集索引里面,查询语句会直接通过索引seek输出,当然取决于数据量,这部分就不演示,下面看看连表操作,又是什么样子。
多表联查
在说多表联查之前我们需要先了解执行计划的三种join运算符,分别为Nested loops、Merge、Hash这三种,这三种运算算法没有谁绝对的好,取决于输出数据量和硬件资源。我们分别简单介绍下这三种算法的逻辑。
loop:是一种逻辑最简单最基本的join方式,普遍被使用。它的算法是如果两张表,它会选择一张为outer table,另外一张为inner table,outer table它会通过筛选条件每查出一条数据都会join到inner table里面去匹配数据行,多少数据匹配了多少次,可以通过rows和executes字段查看。其算法复杂度两表筛选数据的乘积,由此可以看出此运算符不适合两表数据量比较大,sqlserver会根据统计信息决定是否用哪种运算符。
merge:从两边的筛选数据集里面各取一个值,比较,如果相等就把这两行连接起来返回,如果不相等就把小的值丢掉,比较的是关联字段。注意如果某张表关联字段是非聚集索引或者没有索引,sqlserver会对该表执行表扫描再排序再按上面的方法merge(说明merge需要字段先排序),当然还有很多情况,可以自己去看,我说的一般是按比较好的情况去说明。
Hash:hash连接就很好理解了,充分发挥它的查询优势,先以某张表做为基表(不是全部数据,筛选数据),第二张表也是筛选数据依次跟基表筛选集比较,符合条件的,返回两行数据的连接集。
先简单说下表结构,job和jobParamter两张关系表,关联字段是id和jobid,主表job有36w数据,子表有3.4w左右数据,id和jobid均为聚集索引。
loop:
1 select a.StateName, a.Id, a.ExpireAt, b.Name from HangFire.Job a inner join HangFire.JobParameter b 2 on a.Id = b.JobId 3 where a.Id >30943
执行计划

耗时

两张表均为聚集索引seek数据,首先outer table jobParameter表seek出来19056条数据,每条数据都要到inner table job表里面去匹配,这里是seek,执行了19056次,最终返回的数据也是19056条数据。下面我们执行同样的语句,看看效果怎么样。
1 select a.StateName, a.Id, a.ExpireAt, b.Name from HangFire.Job a inner join HangFire.JobParameter b 2 on a.Id = b.JobId 3 where a.Id >20943
执行计划

耗时

上面的sql语句我仅仅只是改了条件参数值,多返回了10000数据,总共返回了29056条数据,两次的执行计划就完全不同了。我们具体看下执行计划,两张表均通过聚集索引seek了29056条数据并且各执行了一次,最后做merge join操作。hash join这里就不尝试了,同样一句sql语句,sqlserver为什么会选择不同的执行计划执行?这就是统计信息。
统计信息
统计信息可以通过sql命令DBCC SHOW_STATISTICS('表名', '索引名')查看。
1 DBCC SHOW_STATISTICS('HangFire.Job', 'PK_HangFire_Job')
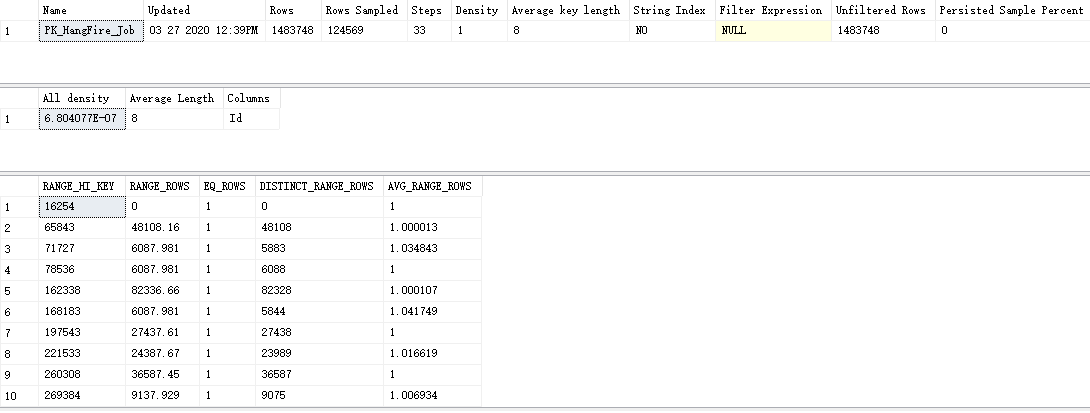
第一张表就是统计信息的基本信息,rows 代表表里面的实际行数。rows sampled代表取样信息数,如果跟rows不等表示没有对整表扫描取样,一般大数据表是抽样。steps表示数据被分成了多少组,按组统计。
第二张表是统计信息的选择评估信息表,all density表示该索引列的选择性,就是评估这个字段作为索引的匹配度,小于0.1表示比较好,选择性高,大于0.1反之。
第三张表表示统计信息的直方图信息表,range_hi_key表示每一组数据的最大值,steps不是把索引字段的所有数据分成33组。range_rows表示在一个闭区间里面的行数,不包括上限值,以第一二行来说,第一行1-16254这个闭区间里面没有数据行,第二行表示16255-65842这个闭区间有48108.16,这只是一个评估值,不是实际的。第三行eq_rows表示等于上限值的数据有多少。sqlserver结合这三张表的信息就能准确做出评估,选择什么样的执行计划来做查询,我们上面的计划也是由他来评估的。注意如果统计信息过时,或者说没有及时发生更新,这样会导致sqlserver做出错误的预判,选择不合适的执行计划,性能会大打折扣,一般情况下,注意执行计划里面的三个字段rows executes estimaterows,estimate rows字段来源于统计信息,通过它来估算io和cpu最后计算出totalcost,sqlserver根据totalcost字段值选择合适的执行计划,下面我们看一个未建索引的字段,同时又包含在检索列里面,看看,下面看下聚合和排序等操作。
聚合&排序
聚合在sqlserver的执行计划里面分两种,stream和hash。stream聚合适合数据集是有序的(比如group by里面包含了聚集索引)或者groupby非聚集字段并且数据量不大,其他情况一般是hash聚合。看代码。
1 select a.Arguments,count(Id) from HangFire.Job a inner join HangFire.JobParameter b 2 on a.Id = b.JobId 3 where a.id >571678 and a.id < 580000 4 group by a.Arguments
执行计划

因为Arguments字段为非聚集字段,所以在stream聚合之前做了一个排序,排序完之后入有序队列再一行一行的数据输入去做匹配,如果匹配就更新标量值,否则开始新的group by匹配。同样的语句我们看看hash聚合的执行计划。
1 select a.Arguments,count(Id) from HangFire.Job a inner join HangFire.JobParameter b 2 on a.Id = b.JobId 3 where a.id >571678 and a.id < 680000 4 group by a.Arguments
执行计划

返回数据集有10w左右,sqlserver聚合操作选择hash聚合,因为它评估发现,输出的数据集有10w+数据,数据量比较大而且需要排序,所以它选择了hash聚合操作,hash操作不需要排序,从数据集里面匹配分组数据,匹配到了就更新聚合值,需要全部检索完。
一些建议
1. 尽量不要做多表联查,尤其是三表(含)以上联查操作,是否考虑其他设计,如冗余反范式表,倒排分片表;
2. 聚集索引列建议采用数值类型(字符串类型会导致索引重排,范围查找),如雪花id,redis-id,充分利用B+树检索优势;
3. 不要太纠结索引seek,有时候scan比seek性能更好,主要看output的行数,一般情况下数据库会通过统计信息选择最优的方案;
4. 其他关键字啥的,百度有很多。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?