

【数据挖掘】ISCX2012数据集分析
使用语言:R
背景介绍:
ISCX2012数据集是目前使用比较广泛的入侵检测数据集,较于KDD99,该数据集的内容更新,数据样本量更大。本次实验中,我们将使用数据挖掘课程中介绍的知识,对ISCX2012数据集进行分析。
题目说明:
1)已知ISCX数据集中,Jun14这天发生了DoS攻击,现要求使用决策树方法对该天的数据进行处理,并验证决策树模型的准确率、精度和召回率
由于XML文档不方便数据处理,将其导入为excel数据表
将该数据表导入到Rstudio中
1 install.packages("openxlsx") 2 library(openxlsx) 3 x<-read.xlsx("F:\\Testbed.xlsx")
得到结果

由于要处理的数据集中,只有totalSourceBytes,totalDestinationBytes,totalDestinationPackets,totalSourcePackets这四个列的对象为数据格式,因此把这四个数据作为分类标准,使用R语言中自带的决策树函数rpart对数据集进行分类,首先为了分类方便,将原数据集的上述属性列及label列提取出来到一个新矩阵s,对s进行操作:

1 library(rpart) 2 s_tree = rpart(V5 ~ ., data = s) 3 print(s_tree) 4 plot(s_tree) 5 text(s_tree)
所得结果如下:

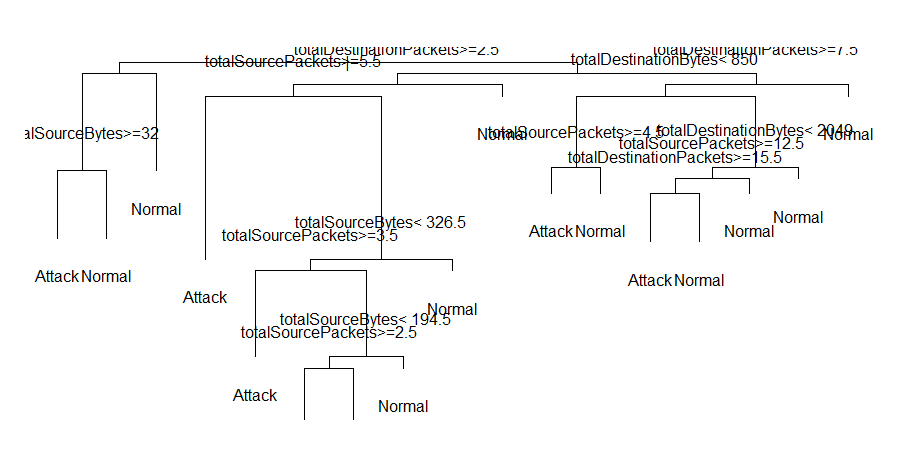
由于画出的树状图过于密集,我们对print产生的节点文本信息进行分析。产生的结果中,以405) totalSourcePackets< 2.5 204 19 Normal (0.0931372549 0.9068627451) *节点为例,totalSourcePackets< 2.5为分类标准,204为该节点的总数据量,19为该分类标准下判断错误的数据个数,Normal为决策树建模完成后该节点值被认为的label,(0.0931372549 0.9068627451)分别为误判率与准确率。下面计算该决策树模型的准率率,精度和召回率。以下计算中以Normal类为正类,由上述决策树模型获取数据TP(正类判断正确)=166765,TN(负类判断正确)=2862,FP(负类误判为正类)=914,FN(正类误判为负类)=839
根据准确率公式Accuracy=(TP+TN)/(TP+TN+FP+FN)计算准确率为98.977%
根据精度公式Precision=TP/(TP+FP)计算精度为99.455%
根据召回率公式Recall=TP/(TP+FN)计算召回率为99.500%
2)实际数据集中,由于其具有的样本量很大和高维特性,我们在处理时需要先对数据进行处理,现要求对于ISCX数据集中Jun14这一天的数据,使用数据预处理方法,达到该目的。需要明确使用方法前后数据体量的变化,并分析通过预处理后的数据在使用决策树方法进行训练时,对模型准确率的影响。
首先使用数据降维预处理方式对数据集进行处理。(以下使用PCR方法)
先对四个列做主成分分析:
1 s.pr<-princomp(~totalSourceBytes+totalDestinationPackets+totalDestinationBytes+totalSourcePackets, data=s, cor=T) 2 summary(s.pr, loadings=TRUE)
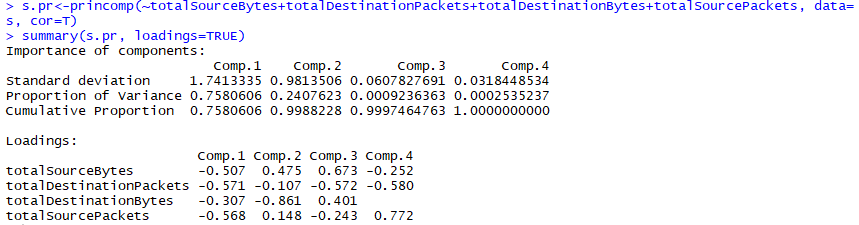
由于Comp.1+Comp.2对主成分的差异比例贡献超过99%,因此可以用Comp.1,Comp.2两个维度的数据来表示原始数据,可得公式
Comp.1=-0.507*totalSourceBytes-0.571*totalDestinationPackets-0.307*totalDestinationBytes-0.568*totalSourcePackets ①
Comp.2=0.475*totalSourceBytes-0.107*totalDestinationPackets-0.861*totalDestinationBytes+0.148* totalSourcePackets ②
将公式①,②带入原数据表,进行计算并生成新的数据表,原数据表的四维数据降维成二维数据,代码如下:
1 Comp.1=-0.507*s$totalSourceBytes-0.571*s$totalDestinationPackets-0.307*s$totalDestinationBytes-0.568*s$totalSourcePackets 2 Comp.2=0.475*s$totalSourceBytes-0.107*s$totalDestinationPackets-0.861*s$totalDestinationBytes+0.148*s$totalSourcePackets 3 q=s[,1:3] 4 q[,1]=Comp.1 5 q[,2]=Comp.2 6 q[,3]=s[,5] 7 colnames(q) <- c("Comp.1","Comp.2","Label")
生成新表
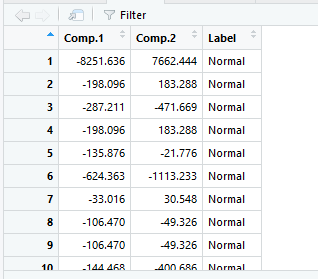
在数据降维后形成的数据表q上建立新的树模型:
1 q_tree = rpart(Label ~ ., data = q) 2 print(q_tree) 3 plot(q_tree) 4 text(q_tree)
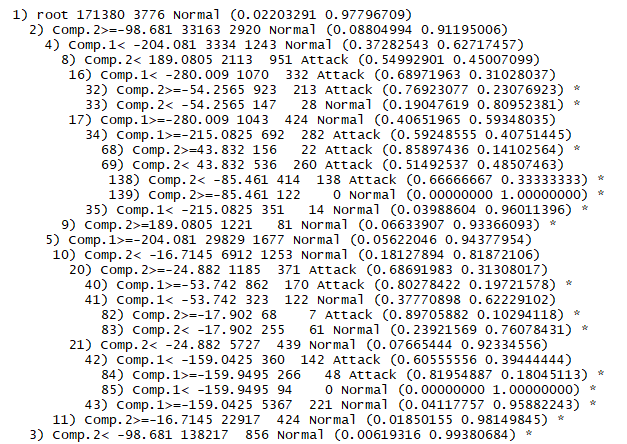
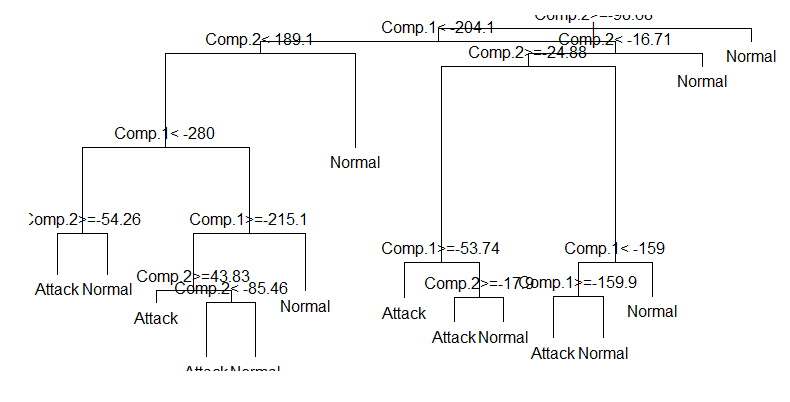
按照1中的方法,计算准确率,新的决策树模型中各参数指标为:
TP=167006,TN=2091,FP=1685,FN=598
根据准确率公式Accuracy=(TP+TN)/(TP+TN+FP+FN)计算准确率为98.668%
1中计算准确率为98.977%,本决策树模型中,在原始数据降维之后,准确率几乎没有影响。

