出租车轨迹挖掘——绕路分析
0x00 导言
在城市交通中,出租车出行占到相当一部分比例,出租车为城市的公共出行做出了许多贡献,但也随之带来许多问题。随着GPS设备的普及和设备本身精度的提高,大量出租车的GPS数据被传输、分类、收集,也由此对分析数据带来便利,能从海量数据中寻找出有用的信息。在本专题中,将着重探讨出租车绕路的问题。
出租车绕路是城市交通服务的顽疾,严重影响了乘客的乘坐体验和对城市的印象,扰乱了正常行驶的秩序。在乘客投诉后,出租车中心往往需要人工查看绕路单,耗时耗力;且有些乘客(以外地游客为主)不知道如何投诉出租车司机,更使得司机逃脱处罚,技术的缺失助长了错误行为的嚣张气焰。因此,对出租车轨迹的挖掘,进而发现和判定绕路行为对于监管部门非常重要。
0x01 绕路定义及特征
出租车的绕路行为五花八门,某些司机喜欢故意在高架上绕远路,某些司机并无明目张胆绕路,但小范围绕路也能获利匪浅。这些行为在时间和空间上呈现出不同的分布,给判定是否绕路带来了不小的麻烦。下面将以一个实际的投诉例子说明绕路问题的复杂性。
本绕路行为发生在杭州市区,乘客从火车东站上车,目的地为江干区某小区,正常行驶距离(最短路径)约为12公里,实际行驶距离15km。

图中将三个月内所有从起点到终点的出租车轨迹绘制在地图上,其中红圈标出为起点,蓝圈标出为终点。从图中可知,大多数出租车司机采用B路线到达目的地,即在艮秋立交上高架,在清江立交下高架抵达江边目的地,该路线在大部分情况下时间最短。但也有少数司机出于各种原因采用了不同的路线。例子中被投诉的出租车采取了A路线,即绕行石德立交上高架,该路线较正常B路线多行驶3-4公里,多收取乘客10元左右。也有少部分司机采取C路线,这条路线较正常路线近1-2公里。有部分司机走D路线抵达终点,这条路线与B路线距离大致相当,但由于地面道路红绿灯较多故采用的司机较少。综上可见,不同的司机会由于各自的原因采取不同的行驶习惯,使得绕路轨迹无法用单一的分类方法进行判定。
从分析中可知,绕路行为是轨迹异常的一种表现,但不完全等同于轨迹异常,它是一种特殊的轨迹异常。图中C、D路线也能判定为轨迹异常,但不属于绕路行为,因为在行驶距离上并无特殊之处。A路线的问题在于,它在局部产生大于正常行驶距离的轨迹,该路线有时会被导航软件推荐,但当时必然没有和乘客沟通,比正常收费多出25%左右,因此被乘客投诉毫不为过。我们应当将此类在图形上“异常”,且在局部产生非正常行驶距离的轨迹归为绕路轨迹。
0x02 异常轨迹判定
轨迹异常(Trajectory anomaly detection)是近年来轨迹分析中相当热门的一个话题,在许多社会问题与科学研究中得到广泛应用,例如野生动物的迁徙,恶劣天气的演变,交通整体态势等。
轨迹异常问题存在几个不易解决的难点,表现在:
1.轨迹异常的定义。如绕路问题中,什么是图形异常?非正常行驶距离的阈值应该取多少?这些都是应当被形式化定义的。换句话说,很多情况下轨迹异常取决于对实际问题的理解。
2.传统的分析异常算法往往采取聚类方法,而基于密度的聚类是全局的,在轨迹相关的问题中,不同的轨迹密度相差非常大,使得基于密度的问题参数设置变得不可能。而若当采用分类方法,如何正确的分类也成为了难题。
3.GPS轨迹由于采样点、设备原因,本身存在数据不完整的情况,长距离的轨迹缺失需要纳入考虑。
轨迹异常挖掘一般的实现模式如下:
数据预处理 -- 提取数据特征 -- 异常检测 -- 数据可视化(可选)-- 得到结果
其中,数据预处理部分将接入的GPS数据根据不同的异常检测方案进行处理。例如网格化GPS数据,去掉不合理的轨迹点,对轨迹进行压缩。在得到轨迹数据集(MOD, Moving Object Database)后,将需要使用的数据特征提取出来,然后使用异常检测算法检查异常轨迹。最终将异常轨迹用地图的方式展现,或者根据检测算法得到异常轨迹的结果。
针对城市道路的情况,轨迹预处理中最有力的方案是地图匹配。它和网格化近似,是一种离散化的手段,但比网格化更为精准。关于地图匹配有许多成熟优秀的算法,例如HMM,ST-Matching等,且考虑到实际环境中性能影响,将在其他主题中展开,此处不再一一详述。
0x03 异常检测
先说个远的,异常定义本身就有各式各样的说法。Ng说:“异常点就是给定两个参数r k,当离某点距离小于等于r的点数量小于k时,该点被定义为异常点” 。是不是很绕?其实可以在点上画个圈(二维,三维就是画个球),圈内点太少就可视作异常点。这是针对数据集中单独的点的做法。轨迹相对处理起来也比较简单,因为只有二维(最多再加上时间维度),高维的异常检测才是考验算法的难点。现有的算法对于轨迹异常有许多不同的处理方法,自从Han小组在08年提出了TRAOD之后,这方面的算法如雨后春笋举不胜数,大致可以分为几种主要的类型:
1.基于距离的方法
如果某轨迹与其他轨迹的距离很远,应能视作为异常轨迹。这是Ng对点定义的扩展。因此,计算轨迹之间的距离即为问题关键点。在这个问题上有很多技巧,如两轨迹中间点的欧氏距离,两轨迹的Hausdorff距离,等等。
2.基于密度的方法
方法是聚类(DBSCAN类、K-MEAN类)。思路是稀疏即异常。缺点在上一章已经提过,上面两种方法其实思路是一致的,缺点也有相同的地方,参数需要先验知识,不同区域的参数取值不一致。
3.基于分类的方法
需要根据特征提出可靠的分类算法。缺点是特征提取需要“强悍”的技巧,且在某些维度上未必有简单的分类。
4.基于子轨迹Sub-Traj的方法
Han组的首创,将原始轨迹划分为子轨迹,对子轨迹聚类。这种解法还需要考虑全局对轨迹的影响。
顺便说个知乎大佬的看法:异常代表三个词:无监督、多分类、解释。无监督很好理解,也许在特征提取之后会采取一些监督下的分类策略。多分类就是多样化的异常情况,解释是最终的结果,即需要将分类结果转化为语义。
0x04 特征提取
特征提取决定了后续对两条轨迹是否判定为同类。最一般方式可以根据距离来计算相似度,不同的线段间两两提取出特征,从而进行相似度度量。
文献Sub-trajectoryand Trajectory-Neighbor-based Outlier Detection over Trajectory Streams ,Zhu2018 中提出了两种特征提取的方式,如下图。
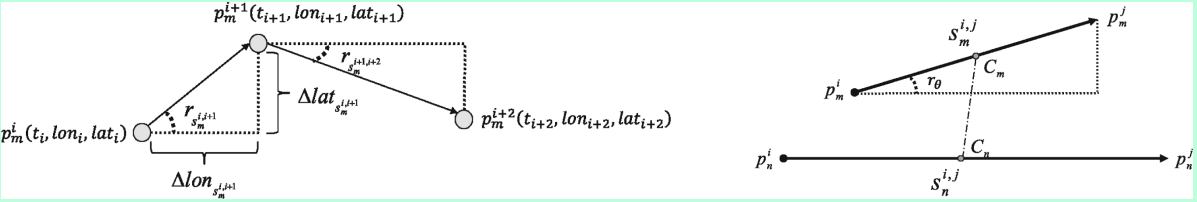
- intra
该提取方式体现了轨迹本身的特征:ΔX, ΔY, Δt,三个参数确定了轨迹本身的方向、速度等特征。 - inter
该提取方式用两轨迹中点的欧氏距离进行衡量,计算轨迹间的距离。此外,计算两条轨迹间的夹角。该特征用于衡量两条轨迹在空间上的相似程度。
0x05 iBAT
本小节将详细介绍一种工业界中极其实用的分类和异常检测算法,及在此基础上针对轨迹异常的离散化处理版本,由南大周志华组(就是西瓜书的作者)发表在2008年。这种称为iForest的方法比起基于距离、密度的方法更为巧妙,它直接刻画数据的“疏离”(isolation)程度。
关于iForest算法可阅读这篇blog:https://blog.csdn.net/Super_Json/article/details/84944707
简单的说,iForest是一种针对多维数据的随机决策树,通过随机选取某个维度将数据按值分成两棵子树,类似BST(划分出大的数据和小的数据),然后子树按相同规则递归划分,直到无法划分为止,此时所有的子树中的数据归于一类。
而iBAT就是一种建立在轨迹网格化基础上的决策树。用作者的话来说,轨迹可以分为两种,一种是正常的,一种是异常的,正常的轨迹“多且近似”,异常的轨迹“少且特殊”, 后者是我们要求的答案。相对于正常轨迹的复杂化和难以处理,异常轨迹比较容易被孤立,因此决策树用于解决异常轨迹有特别的好处。
iBAT的算法如下:
1.随机选某个网格
2.把轨迹集合按有无此网格分为两棵树
3.递归处理子树
4.得到完整的决策树
5.按iForest算法决定异常数据
在实际应用中,发现iBAT存在几个缺点:
1.需要选出OD对下的所有轨迹集合,在实际使用时往往某些异常轨迹OD对比较少,难以在统计上成立。当然,这个缺点对于所有的异常检测算法都或多或少存在。
2.本质上还是全局算法,缺乏对部分轨迹绕路的精确判断,如果轨迹绕路只是局部的(但在距离上很明显),由于大部分数据和正常轨迹相同,此时可能落在决策树的底层。
3.决策树的高层(即异常数据)也可能由于一个异常点的存在,首先选取了该异常点存在的网格,从而发生误判。
因此后面也有许多工作对iBAT提出了优化,其中几个思路都很清晰:
1.对异常数据和正常数据进行相似度判定,离正常数据相似度太低的才是异常数据。
2.计算局部轨迹距离,看是否有严重的超过正常距离的行为。
0x06 数理统计
个人比较偏爱这种方法。它有两个优点:
1.实现简单。当然iBAT代码也非常简洁,建立在树基础上的算法往往会体现一种简单的美感。但是有什么比统计处理异常更简单的呢?
2.使用灵活。统计时可以加入时间、状态等等向量,判断异常的checkpoint也可以自定义。
关于统计方法,交大的Cheng小组提出了一种基于位移-距离和位移-时间判断的统计模式。他们将车辆行程的位移作为X轴,距离作为Y轴,将其绘制成为位移-距离曲线,并拟合出多项式方程,在正态分布的假设前提下得到每条轨迹(每条曲线)的分布概率,概率过小的即为异常数据。
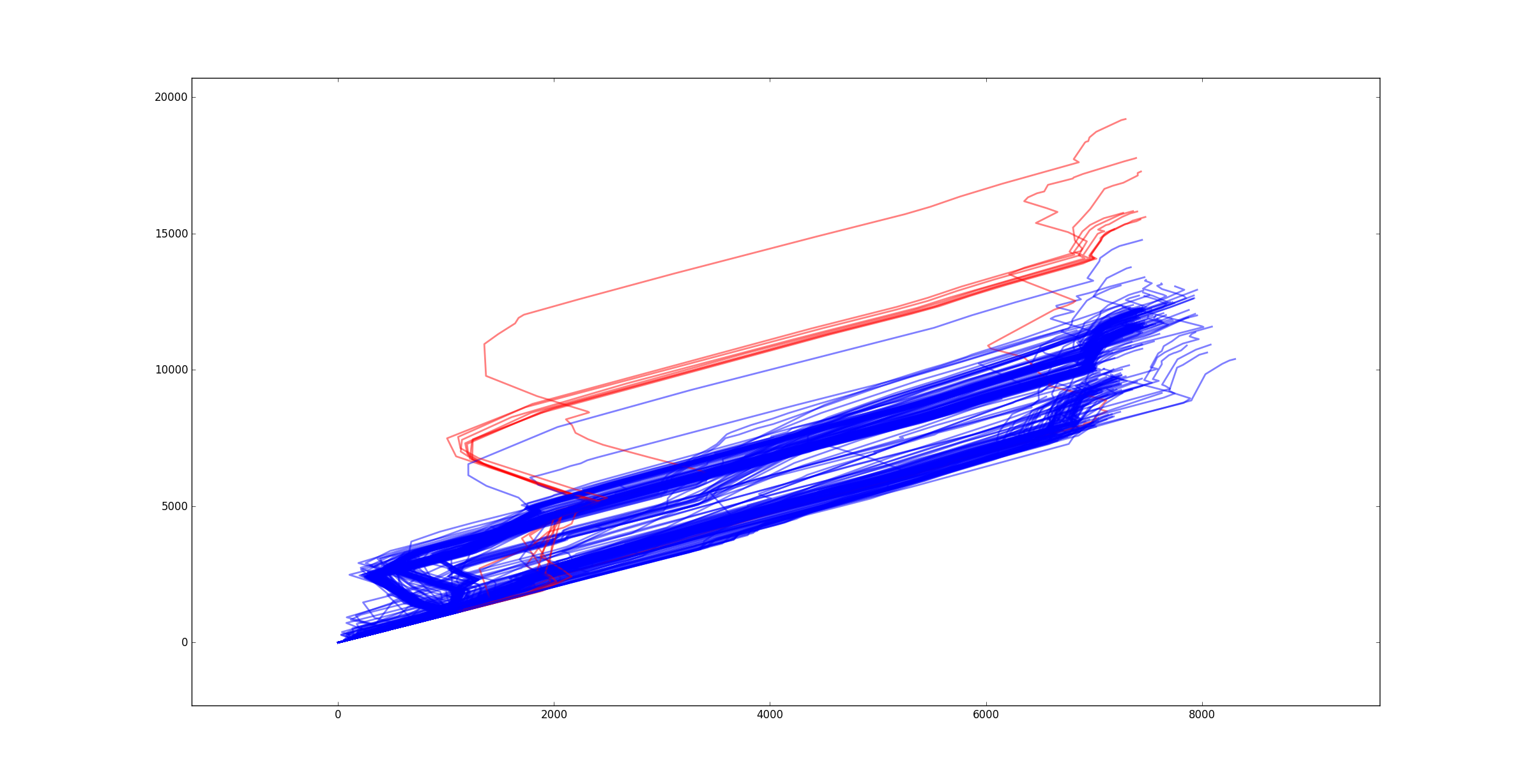
然而像图中这种情况,拟合未必是最佳方案。可以很清楚地从原图中看到,出租车常用两条路线,因而位移距离曲线的分布也聚集成两个cluster。此时用普通的判断异常值方法即可。有一种选择是对分布图进行DBSCAN,但我嫌它需要参数,就不选了。
最终得到图中所示红色曲线为异常轨迹,这些轨迹是原图中走A路线的出租车轨迹。
0x07 思路
0.建立轨迹库
1.分段做距离统计
2.整体用iBAT测试,取样正常轨迹
3.Edit Distance判定异常程度
回过头来看异常三要素:距离统计完成了无监督下的异常分析,iBAT完成了分类,相似度分析完成了解释。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号