第一篇日志:用python简单提取网站信息【将lexico的一个页面中例句提取出来】
问题背景:
lexico中一个单词可能有100多个例句,由于页面设计的问题,我们直接从页面中复制例句有点费时间,所以就打算用python提取其中的例句,以用于之后的dependency parsing分析
个人背景:
非科班,业余选手,初学者,因为自己想搞搞nlp(每次打都出来“你老婆”,实际上是自然语言处理。。。)帮助自己做些学习应用,所以主要用python。所以内容可能过于简单,面向初学者,比较啰嗦,请谨慎观看。
问题解决步骤:
1.打开lexico.com,查找你想要的单词,将页面保存到本地(复制粘贴源码保存到txt文档并为html格式,或者直接右键下载页面改为html格式)


2.检查元素,寻找例句所在位置,发现都在<em><\em>这个标签里,有少量的<em><\em>标签里含有的是查找的单词
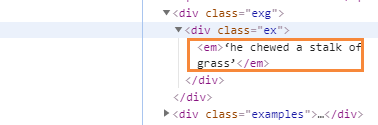
3.编写程序将em标签里的内容提取出来
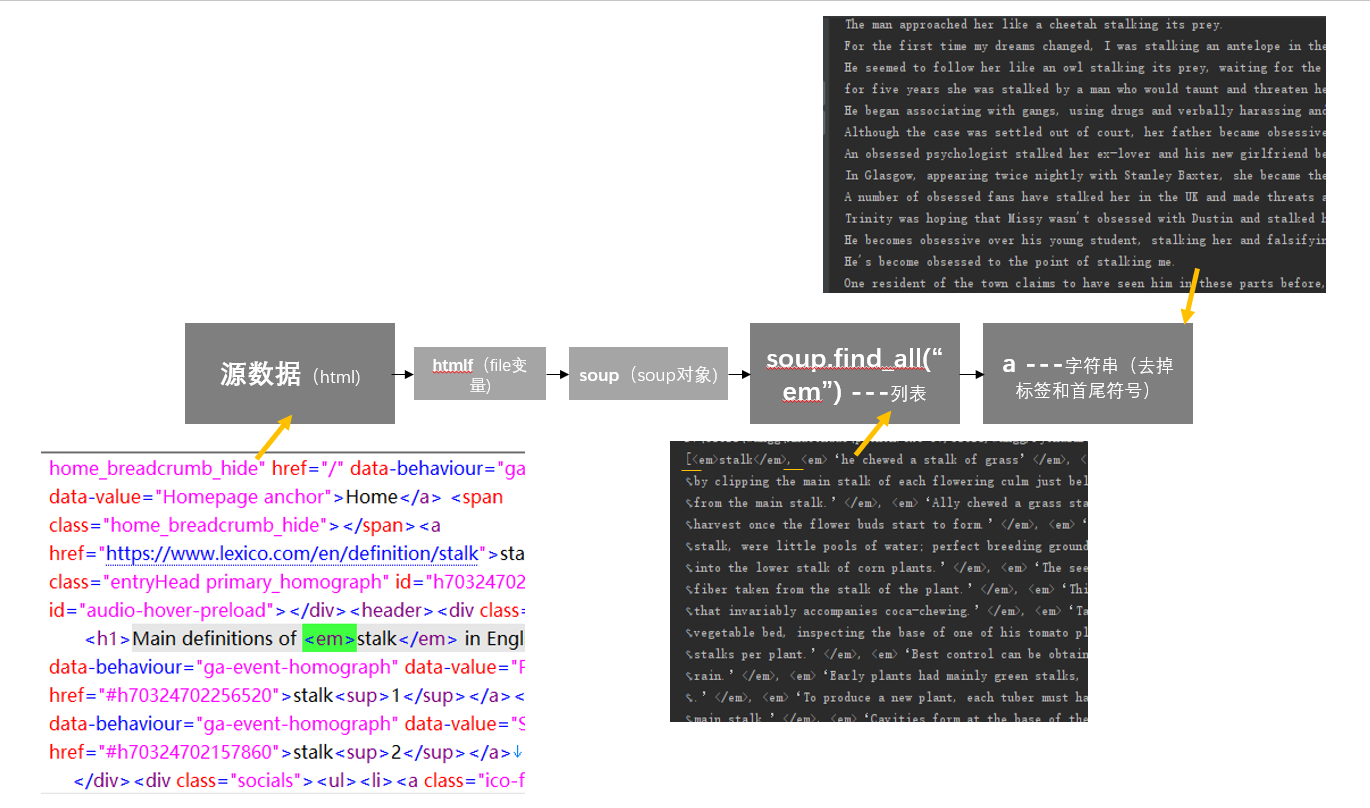
A.把源数据赋给一个变量

htlmf=open('stalk.html',encoding='utf-8')
这里open是一个函数,前一个变量为文件地址,后面是编码类型。输出是一个file对象,可以对其进行file的相关操作。
然后我们用beautifulsoup进行处理,建立一个soup对象。这样就可以用beautifulsoup其中的函数进行处理了
soup = BeautifulSoup(htmlf, 'html.parser')
htmlf是一个file对象,因为是html格式所以用html.parser,有时候需要处理xml文件(不过xml好像有被json取代的趋势?不太清楚)
因为我们引用了BeautifulSoup函数,我们需要在最前面声明
from bs4 import BeautifulSoup
B. 用beautifulsoup将标签提取出来很简单,只需一个soup.find_all("em")就可以了。
注释:
1.soup:是beautifulsoup的一种数据类型,可以理解成和python中的list(数组)、字典或者字符串(在其它语言里也有)之类的差不多。这里的soup是这种数据类型的变量名,
2..find_all("em"):.后面的是函数,对soup进行操作,实际上是一段以soup和em这两个参数为变量(广义变量)的一段函数。em表示寻找的标签,这个函数可以把soup中含有em标签的行给输出,他输出的是一个列表,类似与这样,[元素1, 元素2, 元素3, ...]
C. 去掉列表中的标签和其中的单引号

用bs中的get_text函数对列表中每一个元素进行处理:p=em.get_text(),然后利用字符串截取的方法把两边的单引号去掉:p[1:len(p)-1],去掉第一个字符和最后一个字符。。将得到的字符串串联在一起。


for em in soup.find_all("em"): p=em.get_text("") if(len(p)>15): a=a+"\n"+p[1:len(p)-1]
全部代码
from bs4 import BeautifulSoup htmlf=open('stalk.html',encoding='utf-8') soup = BeautifulSoup(htmlf, 'html.parser') a="" for em in soup.find_all("em"): p=em.get_text() if(len(p)>15): a=a+"\n"+p[1:len(p)-1] print(a)
大功告成,编程部分很简单,但讲解真是考验耐心,我也实际上屈服了,以后争取做得更好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号