字符编码那些事-2
各种编码方案的标准简介
ASCII 码
- 范围:0000 0000 - 0111 1111 (二进制) 使用7 位二进制数(剩下的1位二进制为0)来表示所有的大写和小写字母,数字0 到9、标点符号,以及在美式英语中使用的特殊控制字符
EASCII(Extended ASCII)字符编码方案 和 ISO/IEC 8859字符编码方案
- 范围:1000 0000 - 1111 1111(二进制) 在一个字节中上述范围 没有定义字符,随着计算机在欧洲的普及欧洲各国对这区间定义了各自的字符,因为各个国家互不相同,妨碍了交流,先后设计了两套统一的,既兼容ASCII码,又支持欧洲各国所使用的那些衍生字符的单字节编码方案:一个是EASCII(Extended ASCII)字符编码方案,另一个是ISO/IEC 8859字符编码方案
- 这样就在ASCII码的基础上,既保证了对ASCII码的兼容性,又补充扩展了新的字符,于是就称之为Extended ASCII(扩展ASCII)码,简称EASCII码
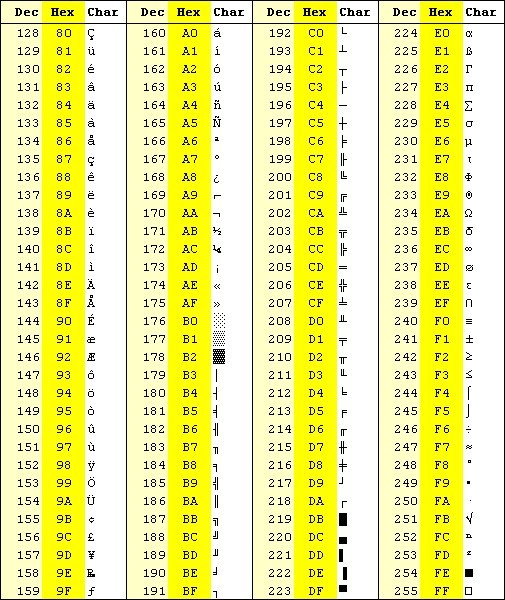
- 不过,EASCII码目前已经很少使用,常用的是ISO/IEC 8859字符编码方案,与ASCII、EASCII属于单个独立的字符集不同,ISO/IEC 8859是一组字符集的总称,其下共包含了15个字符集,即ISO/IEC 8859-n,n=1、2、3...15、16(其中12未定义,所以共15个)
ISO/IEC 8859-1往往简称为ISO 8859-1,而且还有一个称之为Latin-1(也写作Latin1)的别名。ISO/IEC 8859-1收录了西欧常用字符(包括德法两国的字母),目前使用得最为普遍。
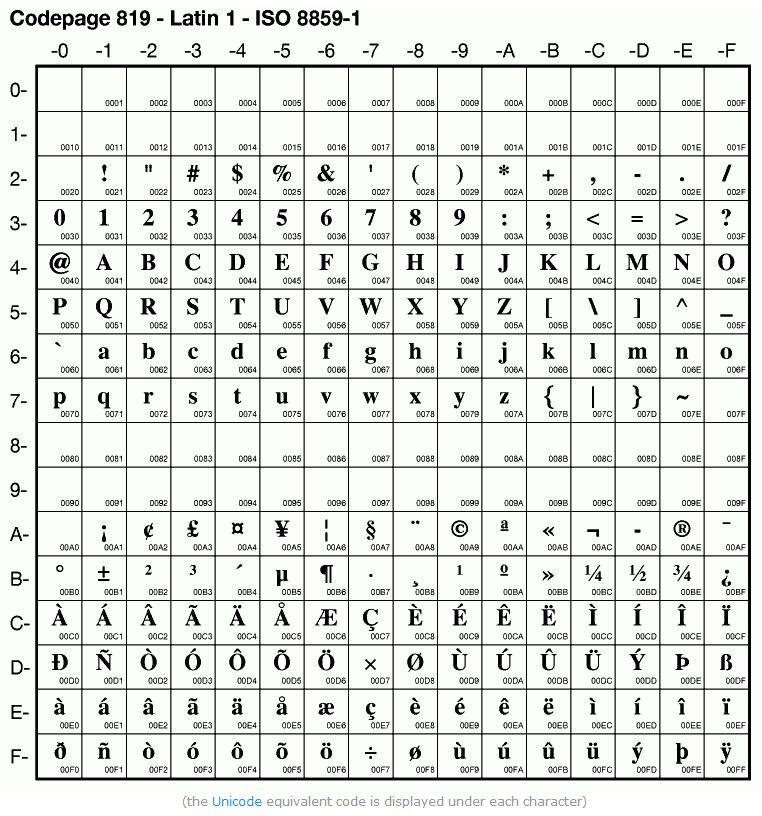
- ISO 8859-2字符集,也称为Latin-2,收录了东欧字符;
- ISO 8859-3字符集,也称为Latin-3,收录了南欧字符;
- ISO 8859-4字符集,也称为Latin-4,收录了北欧字符;
- ...
GB2312 GBK GB18030
汉字就多达10多万个,一个字节只能表示256个字符,肯定是不够的,因此只能使用多个字节来表示一个字符,2字节可以编码的位置就有2^16=65536个
GB18030>GBK>GB2312>ASCII 依次向下兼容
- GB2312
GB2312编码为了避免与ASCII字符编码(0~127)相冲突,规定表示一个汉字的编码(即汉字内码)的字节其值必须大于127(即字节的最高位为1),并且必须是两个大于127的字节连在一起来共同表示一个汉字(GB2312为双字节编码),前一字节称为高字节,后一字节称为低字节;而一个字节的值若小于等于127(即字节的最高位为0),自然是仍表示一个原来的ASCII字符(ASCII为单字节编码)。
GB2312标准共收录6763个汉字,682个字符(这些字符是双字节 为了显示时的字符间对齐 包括常见全角字符,而原来的ASCII中的标点字符就成为半角字符) - GBK
GBK跟GB2312一样是双字节编码,但GBK只要求第一个字节即高字节大于127就固定表示这是一个汉字的开始(即GBK编码高字节的首位必须是1;0~127当然表示的还是ASCII字符),不再像GB2312一样要求第二个字节即低字节也必须大于127(即GBK编码低字节首位既可以是0,也可以是1) < 怎么和ASCII区分 ? >
共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一体,中文简体、中文繁体、日文假名,不支持韩国文字 - GB18030
GB18030-2000除保留全部GBK编码汉字之外,在第二字节再度进行扩展,增加了大约一百个汉字及四位元组编码空间
2005年,GB18030编码方案在GB18030-2000的基础上又进行了扩充,于是又有了GB18030-2005《信息技术中文编码字符集》
CJK中日韩统一表意文字
- CJK指的是中日韩统一表意文字(CJK Unified Ideographs),也称统一汉字(Unihan),目的是要把分别来自中文(包含壮文)、日文、韩文、越文中,起源相同、本义相同、形状一样或稍异的表意文字在Unicode标准及ISO/IEC 10646标准内赋予相同的码点值
Unicode编码和UCS
- 两个不同的组织机构发布的2种 全球统一的通用字符集
- 最初,由世界上多家多语言软件开发商组成了统一码联盟(The Unicode Consortium),接着于1991年发布了The Unicode Standard(统一码标准),定义了一个全球统一的通用字符集,习惯简称为Unicode字符集(Unicode常被称为统一码、万国码、单一码,严格来说,这些称呼不够严谨或不够准确,因为Unicode字符集只是一个编号字符集CCS,尚未经过字符编码方式CEF和字符编码模式CES进行编码)。
- 接着,ISO及IEC也于1993年联合发布了一个标准号为ISO/IEC 10646-1的全球统一的通用字符集,称之为Universal Multiple-Octet Coded Character Set(通用多八位组编号字符集,习惯翻译为“通用多八位编码字符集”,但这里将Coded翻译为“编码的”极易误导人),简称为Universal Character Set(即通用字符集,缩写为UCS)
ANSI编码和代码页
- 同样,日文、韩文以及其他世界各个国家和地区的文字都有它们各自的编码。所有这些各个国家和地区所独立制定的既兼容ASCII又互相之间不兼容的字符编码(准确地来说应该是既兼容ASCII又互相之间不完全兼容,因为这里所说的“不兼容”实际上指的是从整体中除开兼容ASCII之外的部分,下同,不再赘述),微软统称为ANSI编码
- ANSI的字面意思并非字符编码,而是美国的一个非营利组织——美国国家标准学会(American National Standards Institute)的缩写
ANSI这个组织做了很多标准制定工作,包括C语言规范ANSI C,还有与各国和地区既兼容ASCII又互相不兼容的字符编码相对应的“代码页(Code Page)”标准 - 代码页
代码页的英文为Code Page,往往简称为CP。代码页也称为“内码表”,是计算机中与特定字符集(准确地说是字符集的某个字符编码方式CEF)相对应的一张字符编码对照表(这里的字符编码实际上指的是字符编码模式CES,因此实际为“字符-字节”或“字符-字节序列”对照表
代码页是字符集在计算机中的具体编码(CES)实现;特别是从现代字符编码模型的角度而言,代码页可认为是字符集的某种字符编码方式CEF的具体字符编码模式CES在计算机中的具体实现,可以将其理解为一张“字符-字节”(或更准确地理解为“字符-字节序列”)映射表,计算机通过查表实现“字符-字节”之间的双向“翻译”
作用 代码页主要用于具体实现各编码方案中的字符在计算机系统中的物理存储和显示 当计算机读取了一个二进制字节,那这个字节到底属于哪个字符,就需要到存储在计算机中的某个代码页中查找,这个查找的过程就被称为查表 - 各个OEM生产厂商根据标准 自己建立这张 代码页 表
