图-用DFS求连通块- UVa 1103和用BFS求最短路-UVa816。
这道题目甚长, 代码也是甚长, 但是思路却不是太难。然而有好多代码实现的细节, 确是十分的巧妙。 对代码阅读能力, 代码理解能力, 代码实现能力, 代码实现技巧, DFS方法都大有裨益, 敬请有兴趣者耐心细读。(也许由于博主太弱, 才有此等感觉)。
题目: UVa 1103
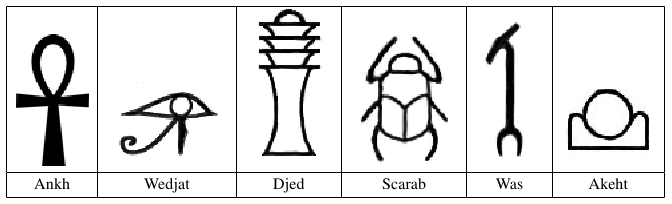
In order to understand early civilizations, archaeologists often study texts written in ancient languages. One such language, used in Egypt more than 3000 years ago, is based on characters called hieroglyphs. Figure C.1 shows six hieroglyphs and their names. In this problem, you will write a program to recognize these six characters.
Input
The input consists of several test cases, each of which describes an image containing one or more hieroglyphs chosen from among those shown in Figure C.1. The image is given in the form of a series of horizontal scan lines consisting of black pixels (represented by 1) and white pixels (represented by 0). In the input data, each scan line is encoded in hexadecimal notation. For example, the sequence of eight pixels 10011100 (one black pixel, followed by two white pixels, and so on) would be represented in hexadecimal notation as 9c. Only digits and lowercase letters a through f are used in the hexadecimal encoding. The first line of each test case contains two integers, H and W. H (0 < H![]() 200) is the number of scan lines in the image. W (0 < W
200) is the number of scan lines in the image. W (0 < W![]() 50) is the number of hexadecimal characters in each line. The next H lines contain the hexadecimal characters of the image, working from top to bottom. Input images conform to the following rules:
50) is the number of hexadecimal characters in each line. The next H lines contain the hexadecimal characters of the image, working from top to bottom. Input images conform to the following rules:
- The image contains only hieroglyphs shown in Figure C.1.
- Each image contains at least one valid hieroglyph.
- Each black pixel in the image is part of a valid hieroglyph.
- Each hieroglyph consists of a connected set of black pixels and each black pixel has at least one other black pixel on its top, bottom, left, or right side.
- The hieroglyphs do not touch and no hieroglyph is inside another hieroglyph.
- Two black pixels that touch diagonally will always have a common touching black pixel.
- The hieroglyphs may be distorted but each has a shape that is topologically equivalent to one of the symbols in Figure C.1. (Two figures are topologically equivalent if each can be transformed into the other by stretching without tearing.)
The last test case is followed by a line containing two zeros.
Output
For each test case, display its case number followed by a string containing one character for each hieroglyph recognized in the image, using the following code:
Ankh: A Wedjat: J Djed: D Scarab: S Was: W Akhet: K
In each output string, print the codes in alphabetic order. Follow the format of the sample output.
The sample input contains descriptions of test cases shown in Figures C.2 and C.3. Due to space constraints not all of the sample input can be shown on this page.

Sample Input
100 25 0000000000000000000000000 0000000000000000000000000 ...(50 lines omitted)... 00001fe0000000000007c0000 00003fe0000000000007c0000 ...(44 lines omitted)... 0000000000000000000000000 0000000000000000000000000 150 38 00000000000000000000000000000000000000 00000000000000000000000000000000000000 ...(75 lines omitted)... 0000000003fffffffffffffffff00000000000 0000000003fffffffffffffffff00000000000 ...(69 lines omitted)... 00000000000000000000000000000000000000 00000000000000000000000000000000000000 0 0
Sample Output
Case 1: AKW Case 2: AAAAA
代码请细读(加了自己所理解的注释):


1 // we pad one empty line/column to the top/bottom/left/right border, so color 1 is always "background" white 2 #include<cstdio> 3 #include<cstring> 4 #include<algorithm> 5 #include<vector> 6 #include<set> 7 using namespace std; 8 9 char bin[256][5]; 10 11 const int maxh = 200 + 5; 12 const int maxw = 50 * 4 + 5; 13 14 int H, W, pic[maxh][maxw], color[maxh][maxw]; 15 char line[maxw]; 16 17 //把读入转化成 0, 1 的函数。 18 void decode(char ch, int row, int col) { 19 for(int i = 0; i < 4; i++) 20 pic[row][col+i] = bin[ch][i] - '0'; 21 } 22 23 const int dr[] = {-1, 1, 0, 0}; 24 const int dc[] = {0, 0, -1, 1}; 25 26 // dfs from (row, col) and paint color c 27 void dfs(int row, int col, int c) { 28 color[row][col] = c; 29 for(int i = 0; i < 4; i++) { 30 int row2 = row + dr[i]; 31 int col2 = col + dc[i]; 32 if(row2 >= 0 && row2 < H && col2 >= 0 && col2 < W && pic[row2][col2] == pic[row][col] && color[row2][col2] == 0) 33 dfs(row2, col2, c); 34 } 35 } 36 37 vector<set<int> > neighbors; 38 39 void check_neighbors(int row, int col) { 40 for(int i = 0; i < 4; i++) { 41 int row2 = row + dr[i]; 42 int col2 = col + dc[i]; 43 if(row2 >= 0 && row2 < H && col2 >= 0&& col2 < W && pic[row2][col2] == 0 && color[row2][col2] != 1) 44 neighbors[color[row][col]].insert(color[row2][col2]); 45 } 46 } 47 48 const char* code = "WAKJSD"; 49 //以容器长度来表示黑连通块旁的内白连通块数(即:象形文字内的白块数) 50 char recognize(int c) { 51 int cnt = neighbors[c].size(); 52 return code[cnt]; 53 } 54 55 // use this function to print the decoded picture 56 void print() { 57 for(int i = 0; i < H; i++) { 58 for(int j = 0; j < W; j++) printf("%d", pic[i][j]); 59 printf("\n"); 60 } 61 } 62 63 int main() { 64 strcpy(bin['0'], "0000");//用来转化成二进制, 此法甚妙 65 strcpy(bin['1'], "0001"); 66 strcpy(bin['2'], "0010"); 67 strcpy(bin['3'], "0011"); 68 strcpy(bin['4'], "0100"); 69 strcpy(bin['5'], "0101"); 70 strcpy(bin['6'], "0110"); 71 strcpy(bin['7'], "0111"); 72 strcpy(bin['8'], "1000"); 73 strcpy(bin['9'], "1001"); 74 strcpy(bin['a'], "1010"); 75 strcpy(bin['b'], "1011"); 76 strcpy(bin['c'], "1100"); 77 strcpy(bin['d'], "1101"); 78 strcpy(bin['e'], "1110"); 79 strcpy(bin['f'], "1111"); 80 81 int kase = 0; 82 while(scanf("%d%d", &H, &W) == 2 && H) { 83 memset(pic, 0, sizeof(pic)); 84 for(int i = 0; i < H; i++) { 85 scanf("%s", line); 86 for(int j = 0; j < W; j++) 87 decode(line[j], i+1, j*4+1);//把输入转发成二进制 存于数组pic[][]中 88 } 89 90 H += 2; 91 W = W * 4 + 2; 92 93 int cnt = 0; 94 vector<int> cc; // connected components of 1 95 memset(color, 0, sizeof(color));//标记数组。 96 for(int i = 0; i < H; i++) 97 for(int j = 0; j < W; j++) 98 if(!color[i][j]) { 99 dfs(i, j, ++cnt); 100 if(pic[i][j] == 1) cc.push_back(cnt);//扫描矩阵,且为所有连通块编号,并把黑连通块号存进cc容器中。 101 } 102 103 neighbors.clear(); 104 neighbors.resize(cnt+1);//设置容器大小, 不清楚的自行百度。嘿嘿! 105 for(int i = 0; i < H; i++) 106 for(int j = 0; j < W; j++) 107 if(pic[i][j] == 1) 108 check_neighbors(i, j);//扫描黑点,并把该点旁边有几个内连通白块存入neighbors容器。//其中下标为黑点对应的连通块编号。 109 110 vector<char> ans; 111 for(int i = 0; i < cc.size(); i++) 112 ans.push_back(recognize(cc[i]));//存目标值, 并排序。 113 sort(ans.begin(), ans.end()); 114 115 printf("Case %d: ", ++kase); 116 for(int i = 0; i < ans.size(); i++) printf("%c", ans[i]); 117 printf("\n"); 118 } 119 return 0; 120 }
刚刚的代码解释有误, 还望海涵!!!(现已更正, 欢迎批评指正!)。
在这里我来解释一下代码的细节过程(思路):
首先是读入数据(16进制的), 第一步, 将它转化成我们所需要的二进制数, 并存入矩阵。
第二步: 我们把矩阵从头到尾扫一下, 找到所有的连通块(包括黑连通块和白连通块)。并且对它们编号(注意: 由于我们从头扫的, 象形文字外部大白块标号为1)。(这样就把他们自己人联系起来啦!)。 不仅如此, 我们还悄悄地把黑连通块的标号存了起来!!
第三步:扫描矩阵, 把黑连通块所相邻的内部白连通块(即:象形文字内部的白块)存进以黑连通块标号为下标的vector<set<> >容器里。
第四部: 每个set《》里有几个不同的值就有几个不同标号的内部白连通块。 各个象形文字内部的白连通块各不相同, 于是输出相应的象形文字代号!!!
(看了好久才完全看懂, 好累哦!!!)
是不是看的好累? 什么? just so so!! 好吧!(我承认我很弱), 再来一道:
BFS求最短路。
UVa 816
| Abbott’s Revenge |
The 1999 World Finals Contest included a problem based on a “dice maze.” At the time the problem was written, the judges were unable to discover the original source of the dice maze concept. Shortly after the contest, however, Mr. Robert Abbott, the creator of numerous mazes and an author on the subject, contacted the contest judges and identified himself as the originator of dice mazes. We regret that we did not credit Mr. Abbott for his original concept in last year’s problem statement. But we are happy to report that Mr. Abbott has offered his expertise to this year’s contest with his original and unpublished “walk-through arrow mazes.”
As are most mazes, a walk-through arrow maze is traversed by moving from intersection to intersection until the goal intersection is reached. As each intersection is approached from a given direction, a sign near the entry to the intersection indicates in which directions the intersection can be exited. These directions are always left, forward or right, or any combination of these.
Figure 1 illustrates a walk-through arrow maze. The intersections are identified as “(row, column)” pairs, with the upper left being (1,1). The “Entrance” intersection for Figure 1 is (3,1), and the “Goal” intersection is (3,3). You begin the maze by moving north from (3,1). As you walk from (3,1) to (2,1), the sign at (2,1) indicates that as you approach (2,1) from the south (traveling north) you may continue to go only forward. Continuing forward takes you toward (1,1). The sign at (1,1) as you approach from the south indicates that you may exit (1,1) only by making a right. This turns you to the east now walking from (1,1) toward (1,2). So far there have been no choices to be made. This is also the case as you continue to move from (1,2) to (2,2) to (2,3) to (1,3). Now, however, as you move west from (1,3) toward (1,2), you have the option of continuing straight or turning left. Continuing straight would take you on toward (1,1), while turning left would take you south to (2,2). The actual (unique) solution to this maze is the following sequence of intersections: (3,1) (2,1) (1,1) (1,2) (2,2) (2,3) (1,3) (1,2) (1,1) (2,1) (2,2) (1,2) (1,3) (2,3) (3,3).
You must write a program to solve valid walk-through arrow mazes. Solving a maze means (if possible) finding a route through the maze that leaves the Entrance in the prescribed direction, and ends in the Goal. This route should not be longer than necessary, of course. But if there are several solutions which are equally long, you can chose any of them.
Input
The input file will consist of one or more arrow mazes. The first line of each maze description contains the name of the maze, which is an alphanumeric string of no more than 20 characters. The next line contains, in the following order, the starting row, the starting column, the starting direction, the goal row, and finally the goal column. All are delimited by a single space. The maximum dimensions of a maze for this problem are 9 by 9, so all row and column numbers are single digits from 1 to 9. The starting direction is one of the characters N, S, E or W, indicating north, south, east and west, respectively.
All remaining input lines for a maze have this format: two integers, one or more groups of characters, and a sentinel asterisk, again all delimited by a single space. The integers represent the row and column, respectively, of a maze intersection. Each character group represents a sign at that intersection. The first character in the group is N, S, E or W to indicate in what direction of travel the sign would be seen. For example, S indicates that this is the sign that is seen when travelling south. (This is the sign posted at the north entrance to the intersection.) Following this first direction character are one to three arrow characters. These can be L, F or R indicating left, forward, and right, respectively.
The list of intersections is concluded by a line containing a single zero in the first column. The next line of the input starts the next maze, and so on. The end of input is the word END on a single line by itself.
Output
For each maze, the output file should contain a line with the name of the maze, followed by one or more lines with either a solution to the maze or the phrase “No Solution Possible”. Maze names should start in column 1, and all other lines should start in column 3, i.e., indented two spaces. Solutions should be output as a list of intersections in the format “(R,C)” in the order they are visited from the start to the goal, should be delimited by a single space, and all but the last line of the solution should contain exactly 10 intersections.
The first maze in the following sample input is the maze in Figure 1.
| Sample Input | Output for the Sample Input |
|---|---|
SAMPLE 3 1 N |
SAMPLE (3,1) (2,1) (1,1) (1,2) (2,2) (2,3) (1,3) (1,2) (1,1) (2,1) (2,2) (1,2) (1,3) (2,3) (3,3) |

Figure 1: An Example Walk-Through Arrow Maze
Figure 2: Robert Abbott’s Atlanta Maze
| Robert Abbott’s walk-through arrow mazes are actually intended for large-scale construction, not paper. Although his mazes are unpublished, some of them have actually been built. One of these is on display at an Atlanta museum. Others have been constructed by the American Maze Company over the past two summers. As their name suggests these mazes are intended to be walked through.
For the adventurous, Figure 2 is a graphic of Robert Abbott’s Atlanta maze. Solving it is quite difficult, even when you have an overview of the entire maze. Imagine trying to solve this by actually walking through the maze and only seeing one sign at a time! Robert Abbott himself indicated that the maze is too complex and most people give up before finishing. Among the people that did not give up was Donald Knuth: it took him about thirty minutes to solve the maze. |
ACM World Finals 2000, Problem A
题目很长, 意思很难懂是吧! 有“紫书”的请参考 165 页。 作者说这个题非常的重要,一定要弄懂。 然而我弄懂题意都费了老大的劲!!! (哎!弱渣是何等的悲哀!)。好吧,(为了给你们节省点时间去陪MM) 我还是强忍着嫉妒的心 简述一下题意吧:
有一个 9 * 9 的交叉点的迷宫。 输入起点, 离开起点时的朝向和终点, 求最短路(多解时任意一个输出即可)。进入一个交叉点的方向(用NEWS表示不同方向)不同时, 允许出去的方向也不相同。 例如:1 2 WLF NR ER * 表示如果 进去时朝W(左), 可以 左转(L)或直行(F), 如果 朝N只能右转(R) 如果朝E也只能右转。* 表示这个点的描述结束啦!
输入有: 起点的坐标, 朝向, 终点的坐标。然后是各个坐标,和各个坐标点的情况(进去方向和可以出去的方向) 以*号表示各个坐标点描述的结束。
题目分析:本题和普通的迷宫在本质上是一样的, 但是由于“朝向”也起了关键的作用, 所以需要一个三元组(r,c, dir)表示位于(r, c)面朝dir 的状态。 假设入口位置为(r0,c0)朝向为dir , 则初始状态并不是(r0, c0, dir), 而是(r1, c1, dir)因为开始时他别无选择, 只有一个规定的方向。 其中, (r1, c1)是沿着方向dir走一步之后的坐标, dir刚好是他进入该点时的朝向。 此处用d[r][c][dir]表示初始状态到(r, c, dir)的最短路长度, 并且用 p[r][c][dir]保存了状态(r, c, dir)在BFS树中的父结点。
规律:: 很多复杂的迷宫问题都可以转化成最短路问题, 然后用BFS求解。 在套用BFS框架之前, 需要先搞清楚图中的“结点”包含哪些内容。
加了我的注释的代码又来喽!!!---我在装逼, 不用理我。
1 #include<cstdio> 2 #include<cstring> 3 #include<vector> 4 #include<queue> 5 using namespace std; 6 7 struct Node { 8 int r, c, dir; // 位于(r,c)朝向dir(0~3表示四个方向N, E, S, W) 9 Node(int r=0, int c=0, int dir=0):r(r),c(c),dir(dir) {} 10 }; 11 12 const int maxn = 10; 13 const char* dirs = "NESW"; // 顺时针旋转。 14 const char* turns = "FLR";//“三种转弯方式”。 15 16 int has_edge[maxn][maxn][4][3];// 表示当前状态(r,c,dir),是否可以沿着转弯方向[trun]行走。 17 int d[maxn][maxn][4]; //表示初始状态到(r,c,dir)的最短路长度。 18 Node p[maxn][maxn][4]; //同时用p[r][c][dir]保存了状态(r, c, dir)在BFS树中的父结点。 19 int r0, c0, dir, r1, c1, r2, c2; 20 21 //把四个方向和3种“转弯方式”编号0~3和0~2. 22 int dir_id(char c) { return strchr(dirs, c) - dirs; } 23 int turn_id(char c) { return strchr(turns, c) - turns; } 24 //用于转弯。 25 const int dr[] = {-1, 0, 1, 0}; 26 const int dc[] = {0, 1, 0, -1}; 27 28 Node walk(const Node& u, int turn) { 29 int dir = u.dir; //直行, 方向不变 30 if(turn == 1) dir = (dir + 3) % 4; // 逆时针 ,转向 31 if(turn == 2) dir = (dir + 1) % 4; // 顺时针 ,转向 32 return Node(u.r + dr[dir], u.c + dc[dir], dir);//下一步可能的状态 33 } 34 35 //判断是否出界 36 bool inside(int r, int c) { 37 return r >= 1 && r <= 9 && c >= 1 && c <= 9; 38 } 39 40 //读取r0,c0,dir,并计算出r1,c1, 然后读入has_edge数组。 41 bool read_case() { 42 char s[99], s2[99]; 43 if(scanf("%s%d%d%s%d%d", s, &r0, &c0, s2, &r2, &c2) != 6) return false; 44 printf("%s\n", s); 45 46 dir = dir_id(s2[0]); 47 r1 = r0 + dr[dir]; 48 c1 = c0 + dc[dir]; 49 50 memset(has_edge, 0, sizeof(has_edge)); 51 for(;;) { 52 int r, c; 53 scanf("%d", &r); 54 if(r == 0) break; 55 scanf("%d", &c); 56 while(scanf("%s", s) == 1 && s[0] != '*') { 57 for(int i = 1; i < strlen(s); i++) 58 has_edge[r][c][dir_id(s[0])][turn_id(s[i])] = 1; 59 } 60 } 61 return true; 62 } 63 64 void print_ans(Node u) { 65 // 从目标结点逆序追溯到初始结点。 66 vector<Node> nodes; 67 for(;;) { 68 nodes.push_back(u); 69 if(d[u.r][u.c][u.dir] == 0) break; 70 u = p[u.r][u.c][u.dir]; 71 } 72 nodes.push_back(Node(r0, c0, dir)); 73 74 //打印解, 每行 10 个。 75 int cnt = 0; 76 for(int i = nodes.size()-1; i >= 0; i--) { 77 if(cnt % 10 == 0) printf(" "); 78 printf(" (%d,%d)", nodes[i].r, nodes[i].c); 79 if(++cnt % 10 == 0) printf("\n"); 80 } 81 if(nodes.size() % 10 != 0) printf("\n"); 82 } 83 84 //BFS主过程。 85 void solve() { 86 queue<Node> q; 87 memset(d, -1, sizeof(d)); 88 Node u(r1, c1, dir); 89 d[u.r][u.c][u.dir] = 0; 90 q.push(u); 91 while(!q.empty()) { 92 Node u = q.front(); q.pop(); 93 if(u.r == r2 && u.c == c2) { print_ans(u); return; }//到达目的地 94 for(int i = 0; i < 3; i++) {//所有可能的转向,(直行,逆时针转, 顺时针转) 95 Node v = walk(u, i); //下一步的状态 96 if(has_edge[u.r][u.c][u.dir][i] && inside(v.r, v.c) && d[v.r][v.c][v.dir] < 0) {//分别判断 97 //从这一步是否可以达到下一步,下一步是否出界, 下一步是否被走过(同方向)。 98 d[v.r][v.c][v.dir] = d[u.r][u.c][u.dir] + 1;//最短长度加 1. 99 p[v.r][v.c][v.dir] = u;//记录父结点。 100 q.push(v); 101 } 102 } 103 } 104 printf(" No Solution Possible\n");//走了所有可以走的可能, 无法到达终点。 105 } 106 107 int main() { 108 while(read_case()) { 109 solve(); 110 } 111 return 0; 112 }
代码实现详细思路:
第一步是读入点的坐标和对该点的描述, 并处理该点, 用has_edge[r][c][dir][turn]来记录下一步可以往哪走。
第二步把第一个结点放入队列, 搜索周围各个方向, 并把可走的结点放入队列(同时该结点出队)即BFS。并用d[r][c][dir]记录下来长度, 用p[r][c][dir]记录下来父结点
第三步搜到目的结点时,结束搜索。
第四步从目的点追溯,到起点, 再把路径输出!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号