python大战机器学习——半监督学习
半监督学习:综合利用有类标的数据和没有类标的数据,来生成合适的分类函数。它是一类可以自动地利用未标记的数据来提升学习性能的算法
1、生成式半监督学习
优点:方法简单,容易实现。通常在有标记数据极少时,生成式半监督学习方法比其他方法性能更好
缺点:假设的生成式模型必须与真实数据分布吻合。如果不吻合则可能效果很差。而如何给出与真实数据分布吻合的生成式模型,这就需要对问题领域的充分了解
2、图半监督学习
(1)标记传播算法:
优点:概念清晰
缺点:存储开销大,难以直接处理大规模数据;而且对于新的样本加入,需要对原图重构并进行标记传播
(2)迭代式标记传播算法:
输入:有标记样本集Dl,未标记样本集Du,构图参数δ,折中参数α
输出:未标记样本的预测结果y
步骤:
1)计算W
2)基于W构造标记传播矩阵S
3)根据公式初始化F<0>
4)t=0
5)迭代,迭代终止条件是F收敛至F*:
F<t+1>=αSF<t>+(1-α)Y
t=t+1
6)构造未标记样本的预测结果yi
7)输出结果y
LabelPropagation实验代码:


1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import metrics 4 from sklearn import datasets 5 from sklearn.semi_supervised import LabelPropagation 6 7 def load_data(): 8 digits=datasets.load_digits() 9 rng=np.random.RandomState(0) 10 index=np.arange(len(digits.data)) 11 rng.shuffle(index) 12 X=digits.data[index] 13 Y=digits.target[index] 14 n_labeled_points=int(len(Y)/10) 15 unlabeled_index=np.arange(len(Y))[n_labeled_points:] 16 17 return X,Y,unlabeled_index 18 19 def test_LabelPropagation(*data): 20 X,Y,unlabeled_index=data 21 Y_train=np.copy(Y) 22 Y_train[unlabeled_index]=-1 23 cls=LabelPropagation(max_iter=100,kernel='rbf',gamma=0.1) 24 cls.fit(X,Y_train) 25 print("Accuracy:%f"%cls.score(X[unlabeled_index],Y[unlabeled_index])) 26 27 X,Y,unlabeled_index=load_data() 28 test_LabelPropagation(X,Y,unlabeled_index)
实验结果:
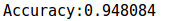 可见预测的准确率还是挺高的
可见预测的准确率还是挺高的
LabelSpreading实验代码:
1 import numpy as np 2 import matplotlib.pyplot as plt 3 from sklearn import metrics 4 from sklearn import datasets 5 from sklearn.semi_supervised import LabelPropagation,LabelSpreading 6 7 def load_data(): 8 digits=datasets.load_digits() 9 rng=np.random.RandomState(0) 10 index=np.arange(len(digits.data)) 11 rng.shuffle(index) 12 X=digits.data[index] 13 Y=digits.target[index] 14 n_labeled_points=int(len(Y)/10) 15 unlabeled_index=np.arange(len(Y))[n_labeled_points:] 16 17 return X,Y,unlabeled_index 18 19 def test_LabelPropagation(*data): 20 X,Y,unlabeled_index=data 21 Y_train=np.copy(Y) 22 Y_train[unlabeled_index]=-1 23 cls=LabelPropagation(max_iter=100,kernel='rbf',gamma=0.1) 24 cls.fit(X,Y_train) 25 print("Accuracy:%f"%cls.score(X[unlabeled_index],Y[unlabeled_index])) 26 27 def test_LabelSpreading(*data): 28 X,Y,unlabeled_index=data 29 Y_train=np.copy(Y) 30 Y_train[unlabeled_index]=-1 31 cls=LabelSpreading(max_iter=100,kernel='rbf',gamma=0.1) 32 cls.fit(X,Y_train) 33 predicted_labels=cls.transduction_[unlabeled_index] 34 true_labels=Y[unlabeled_index] 35 print("Accuracy:%f"%metrics.accuracy_score(true_labels,predicted_labels)) 36 37 X,Y,unlabeled_index=load_data() 38 #test_LabelPropagation(X,Y,unlabeled_index) 39 test_LabelSpreading(X,Y,unlabeled_index)
注:LabelSpreading类似于LabelPropagation,但是使用基于normalized graph Laplacian and soft clamping的距离矩阵
实验结果:
 预测效果也很不错
预测效果也很不错
3、总结
半监督学习在利用未标记样本后并非必然提升泛化性能,在有些情况下甚至会导致性能下降。对生成式方法,原因通常是模型假设不准确。因此需要依赖充分可靠的领域知识来设计模型。更一般的安全半监督学习仍然是未加解决的难题。安全是指:利用未标记样本后,能确保返回性能至少不差于仅利用有标记样本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号