
python scrapy爬取瓜子二手车网站二手车信息(二)
接上文 https://www.cnblogs.com/achangblog/p/13956140.html
第五步:编辑中间件文件middlewares.py并启用
在上一步破解js代码得到正确响应内容后,即可把破解方法复制进middlewares.py文件中,稍作修改即可:
import re
import execjs
import datetime
class GuaziDownloaderMiddleware:
def __init__(self):
self.f = open('guazi.js', 'r', encoding='utf-8')
self.content = self.f.read()
def process_response(self, request, response, spider):
html = response.text
if '正在打开中,请稍后' in html:
pattern = re.compile(r'value=anti\(\'(.*?)\',\'(.*?)\'\)')
string_ = pattern.search(html).group(1)
key = pattern.search(html).group(2)
js_compile = execjs.compile(self.content)
value = js_compile.call('anti', string_, key)
expire_time = datetime.datetime.utcnow() + datetime.timedelta(seconds=2592000)
expires = "; expires=" + expire_time.strftime('%a, %d %b %Y %H:%M:%S GMT')
cookie = {'antipas': value, 'expires': expires, 'path': '/'}
request.cookies = cookie
return request
elif response.status == 200:
return response
# elif '客官请求太频繁啦,请1分钟后重试' in html:
# print('!!! response.status是:{}'.format(response.status))
# print('request.url: {}'.format(request.url))
# print('请求频繁')
# return request
def close_spider(self):
self.f.close()
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
然后在settings.py文件开启该middleware:
DOWNLOADER_MIDDLEWARES = {
'guazi.middlewares.GuaziDownloaderMiddleware': 543,
}
第六步: 分析网页结构,初步编写爬虫文件guazi_spider.py
①.通过分析瓜子网站网页结构,我们可以从 https://www.guazi.com/www/buy 网页开始爬起,通过抓取不同城市url循环遍历每个城市的二手车信息;城市url信息隐藏在一个js函数中,可通过正则表达式获取。
②.再分析每个城市二手车信息的页面,发现每页展示40条二手车信息,最多展示50页,也就是最多展示2000条数据,无法完全展示城市所有二手车信息,因此,我们需要按品牌分类继续往下细分url。以城市安吉为例,点击品牌栏上的“大众”,得到的url为 https://www.guazi.com/anji/dazhong/,发现 “为您找到7802辆好车”,仍无法完全显示,则继续细分车系,如点击车系栏的“速腾”,得到的url为 https://www.guazi.com/anji/suteng/ ,页面展示 “为您找到890辆好车”,小于2000,可以完全展示,如此循环遍历每一个大的品牌,若发现车辆数大于2000,则继续细分车系,至此,url细分结束;
③.接下来就是翻页操作,通过分析网页结构可以发现,只要不是最后一页,都有下一页的按钮存在,据此,循环遍历可以获取所有url信息
④.有了每一页的url,即可得知每一页上的二手车详情页的url,根据二手车详情页url,即可获取到该二手车数据信息
通过以上分析,初步得到的guazi_spider.py文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
import re
import json
from guazi.items import GuaziItem
import pytesseract
import requests
from PIL import Image
from ..settings import DEFAULT_REQUEST_HEADERS
class GuaziSpiderSpider(scrapy.Spider):
name = 'guazi_spider'
allowed_domains = ['www.guazi.com']
start_urls = ['https://www.guazi.com/www/buy']
def parse(self, response):
pattern = re.compile(r'cityLeft = (.*?);')
city_left_dict = json.loads(pattern.search(response.text).group(1))
pattern = re.compile(r'cityRight = (.*?);')
city_right_dict = json.loads(pattern.search(response.text).group(1))
city_domain_and_name_list = []
for key, value in {**city_left_dict, **city_right_dict}.items():
for city_detail in value:
one_couple = {}
if 'domain' in city_detail:
one_couple['domain'] = city_detail['domain']
if 'name' in city_detail:
one_couple['name'] = city_detail['name']
city_domain_and_name_list.append(one_couple)
for city_domain_and_name in city_domain_and_name_list:
city_name = city_domain_and_name['name']
city_url = 'https://www.guazi.com/' + city_domain_and_name['domain'] + '/buy'
yield scrapy.Request(url=city_url, callback=self.parse_city_detail, meta={'city': city_name},
dont_filter=True)
# 处理每个城市,获取品牌url
def parse_city_detail(self, response):
brand_list = response.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]//ul//li/p//a')
for brand in brand_list:
brand_url = response.urljoin(brand.xpath('./@href').get())
yield scrapy.Request(url=brand_url, callback=self.parse_brand_detail, meta=response.meta, dont_filter=True)
# 处理品牌url及其车系(是否)分类
def parse_brand_detail(self, response):
car_count_pattern = re.compile(r'为您找到(.*)辆好车')
car_count = int(car_count_pattern.search(response.xpath('//p[@class="result-p3"]/text()').get()).group(1))
if 0 < car_count <= 2000:
yield scrapy.Request(url=response.url, callback=self.parse_car_list, meta=response.meta, dont_filter=True)
# elif car_count > 2000:
# brand_list = response.xpath('//div[@class="screen"]/dl[position()=2]//ul//li/p//a')
# for brand in brand_list:
# brand_url = response.urljoin(brand.xpath('./@href').get())
# print('brand_url: ' + brand_url)
# yield scrapy.Request(url=brand_url, callback=self.parse_brand_detail, meta=response.meta,
# dont_filter=True)
# else:
# pass
# 处理页面数据及翻页
def parse_car_list(self, response):
car_list = response.xpath('//ul[@class="carlist clearfix js-top"]//li/a')
for car in car_list:
car_url = response.urljoin(car.xpath('./@href').get())
yield scrapy.Request(car_url, callback=self.parse_car_detail, meta=response.meta, dont_filter=True)
# next_page_a_label = response.xpath('//ul[@class="pageLink clearfix"]//li[last()]/a')
# next_page_button = next_page_a_label.xpath('./span/text()').get()
# if next_page_button == '下一页':
# next_url = response.urljoin(next_page_a_label.xpath('./@href').get())
# yield scrapy.Request(next_url, callback=self.parse_car_list, meta=response.meta, dont_filter=True)
# 处理二手车数据详情
def parse_car_detail(self, response):
item = GuaziItem()
item['city'] = response.meta['city']
item['title'] = ''.join(response.xpath('//h1[@class="titlebox"]/text()').getall()).strip()
source_id_pattern = re.compile(r'车源号:(.*)')
source_id_str = response.xpath('//div[@class="right-carnumber"]/text()').get()
item['source_id'] = source_id_pattern.search(source_id_str).group(1).strip()
license_time_img_url = response.xpath('//ul[@class="assort clearfix"]/li[@class="one"]/span/img/@src').get()
# item['license_time'] = self.image_to_str(license_time_img_url)[0:7]
item['license_time'] = license_time_img_url
item['mileage'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="two"]/span/text()').get()
item['displacement'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="three"]/span/text()').get()
item['gearbox_type'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="last"]/span/text()').get()
item['full_price'] = response.xpath('//span[@class="price-num"]/text()').get()
yield item
# 识别图片转为文字
# def image_to_str(self, img_url):
# response = requests.get(url=img_url, headers=DEFAULT_REQUEST_HEADERS)
# with open('image.jpg', 'wb') as f:
# f.write(response.content)
# image = Image.open('image.jpg')
# return pytesseract.image_to_string(image)
ps: 在获取“上牌时间”时,发现网页显示为一个小图片,而非文本数据,此时可以通过pytesseract模块,自动识别图片上的文字,即可获取正确的时间信息;或者直接保存“上牌时间”图片的url信息。
第七步:优化爬虫文件guazi_spider.py
由于上述代码每次运行都要解析一遍城市url数据,而城市url数据是固定不变的,所以,可以先把城市url解析出来存入mongodb数据库,在爬虫文件中直接使用即可。
首先需在items.py的同级目录下创建文件guazi_mongo.py
import pymongo
class GuaziMongo:
def __init__(self):
self.client = pymongo.MongoClient(host='localhost', port=27017)
self.guazi_db = self.client['guazi']
self.guazi_uncol = self.guazi_db['guazi_url_and_name']
self.guazi_item_col = self.guazi_db['guazi_item']
guaziMongo = GuaziMongo()
然后再在items.py的同级目录下创建文件guazi_get_city_url.py
# 获取所有瓜子二手车城市的url和名字,以字典的形式存入数据库 {'name': '北京', 'url': 'https://www.guazi.com/bj/buy'}
import requests
import re
import execjs
import datetime
import json
from guazi.guazi_mongo import guaziMongo
def get_city_name_and_url(response):
pattern = re.compile(r'cityLeft = (.*?);')
city_left_dict = json.loads(pattern.search(response.text).group(1))
pattern = re.compile(r'cityRight = (.*?);')
city_right_dict = json.loads(pattern.search(response.text).group(1))
city_domain_and_name_list = []
for key, value in {**city_left_dict, **city_right_dict}.items():
for city_detail in value:
one_couple = {}
if 'domain' in city_detail:
one_couple['domain'] = city_detail['domain']
if 'name' in city_detail:
one_couple['name'] = city_detail['name']
city_domain_and_name_list.append(one_couple)
city_name_and_url_list = []
for city_domain_and_name in city_domain_and_name_list:
city_name = city_domain_and_name['name']
city_url = 'https://www.guazi.com/' + city_domain_and_name['domain'] + '/buy'
city_name_and_url_list.append({'name': city_name, 'url': city_url})
return city_name_and_url_list
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
url = 'https://www.guazi.com/www/buy'
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
html = response.text
if '正在打开中,请稍后' in html:
pattern = re.compile(r'value=anti\(\'(.*?)\',\'(.*?)\'\)')
string_ = pattern.search(html).group(1)
key = pattern.search(html).group(2)
print('string_: {}, key: {}'.format(string_, key))
with open('guazi.js', 'r', encoding='utf-8') as f:
js_compile = execjs.compile(f.read())
value = js_compile.call('anti', string_, key)
name = 'antipas'
expire_time = datetime.datetime.utcnow() + datetime.timedelta(seconds=2592000)
expires = "; expires=" + expire_time.strftime('%a, %d %b %Y %H:%M:%S GMT')
cookie = name + "=" + value + expires + "; path=/"
headers['Cookie'] = cookie
response = requests.get(url, headers=headers)
data_col = guaziMongo.guazi_uncol
data = get_city_name_and_url(response)
print(data)
# data_col.delete_many({})
data_col.insert_many(data)
for data_ in data:
print(data_)
运行一遍guazi_get_city_url.py即可往数据库中插入一次所有城市url数据
爬虫文件guazi_spider.py可修改为如下:
# -*- coding: utf-8 -*-
import scrapy
import re
import json
from guazi.items import GuaziItem
from guazi.guazi_mongo import guaziMongo
import pytesseract
import requests
from PIL import Image
from ..settings import DEFAULT_REQUEST_HEADERS
class GuaziSpiderSpider(scrapy.Spider):
name = 'guazi_spider'
allowed_domains = ['www.guazi.com']
# start_urls = ['https://www.guazi.com/www/buy']
def start_requests(self):
while True:
city_url_and_name = guaziMongo.guazi_uncol.find_one_and_delete({})
if city_url_and_name:
city_url = city_url_and_name['url']
city_name = city_url_and_name['name']
yield scrapy.Request(url=city_url, callback=self.parse_city_detail, meta={'city': city_name},
dont_filter=True)
else:
break
# 处理每个城市,获取品牌url
def parse_city_detail(self, response):
brand_list = response.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]//ul//li/p//a')
for brand in brand_list:
brand_url = response.urljoin(brand.xpath('./@href').get())
yield scrapy.Request(url=brand_url, callback=self.parse_brand_detail, meta=response.meta, dont_filter=True)
# 处理品牌url及其车系(是否)分类
def parse_brand_detail(self, response):
car_count_pattern = re.compile(r'为您找到(.*)辆好车')
car_count = int(car_count_pattern.search(response.xpath('//p[@class="result-p3"]/text()').get()).group(1))
if 0 < car_count <= 2000:
yield scrapy.Request(url=response.url, callback=self.parse_car_list, meta=response.meta, dont_filter=True)
# elif car_count > 2000:
# brand_list = response.xpath('//div[@class="screen"]/dl[position()=2]//ul//li/p//a')
# for brand in brand_list:
# brand_url = response.urljoin(brand.xpath('./@href').get())
# print('brand_url: ' + brand_url)
# yield scrapy.Request(url=brand_url, callback=self.parse_brand_detail, meta=response.meta,
# dont_filter=True)
# else:
# pass
# 处理页面数据及翻页
def parse_car_list(self, response):
car_list = response.xpath('//ul[@class="carlist clearfix js-top"]//li/a')
for car in car_list:
car_url = response.urljoin(car.xpath('./@href').get())
yield scrapy.Request(car_url, callback=self.parse_car_detail, meta=response.meta, dont_filter=True)
# next_page_a_label = response.xpath('//ul[@class="pageLink clearfix"]//li[last()]/a')
# next_page_button = next_page_a_label.xpath('./span/text()').get()
# if next_page_button == '下一页':
# next_url = response.urljoin(next_page_a_label.xpath('./@href').get())
# yield scrapy.Request(next_url, callback=self.parse_car_list, meta=response.meta, dont_filter=True)
# 处理二手车数据详情
def parse_car_detail(self, response):
item = GuaziItem()
item['city'] = response.meta['city']
item['title'] = ''.join(response.xpath('//h1[@class="titlebox"]/text()').getall()).strip()
source_id_pattern = re.compile(r'车源号:(.*)')
source_id_str = response.xpath('//div[@class="right-carnumber"]/text()').get()
item['source_id'] = source_id_pattern.search(source_id_str).group(1).strip()
license_time_img_url = response.xpath('//ul[@class="assort clearfix"]/li[@class="one"]/span/img/@src').get()
# item['license_time'] = self.image_to_str(license_time_img_url)[0:7]
item['license_time'] = license_time_img_url
item['mileage'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="two"]/span/text()').get()
item['displacement'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="three"]/span/text()').get()
item['gearbox_type'] = response.xpath('//ul[@class="assort clearfix"]/li[@class="last"]/span/text()').get()
item['full_price'] = response.xpath('//span[@class="price-num"]/text()').get()
yield item
# def image_to_str(self, img_url):
# response = requests.get(url=img_url, headers=DEFAULT_REQUEST_HEADERS)
# with open('image.jpg', 'wb') as f:
# f.write(response.content)
# image = Image.open('image.jpg')
# return pytesseract.image_to_string(image)
第八步:配置pipelines.py,将数据写入mongdb数据库
from guazi.guazi_mongo import guaziMongo
class GuaziPipeline:
def process_item(self, item, spider):
item = dict(item)
source_id = item['source_id']
# 以车源号为去重指标,更新数据库内的数据(若有此车源号,更新数据,没有则插入数据)
guaziMongo.guazi_item_col.update_one({'source_id': source_id}, {'$set': item}, True)
return item
在settings.py中配置pipeline:
ITEM_PIPELINES = {
'guazi.pipelines.GuaziPipeline': 300,
}
第九步:设置ip代理
由于爬取过程中ip单一,可能还未爬取到真实数据即会返回203,请求频繁的提示,因此,可以在middlewares.py中设置ip代理(付费)
ip代理商有很多,可以去网络搜索,这里以“亿牛云”为例:
代码参考该网址:https://www.16yun.cn/help/ss_demo/#1python 下面有scrapy项目所需的代码,将代码复制到middlewares.py中,在settings.py中开启该中间件。
DOWNLOADER_MIDDLEWARES = {
'guazi.middlewares.GuaziDownloaderMiddleware': 543,
'guazi.middlewares.ProxyMiddleware': 500
}
配置完成后仍需修改settings.py文件,配置常用属性:
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 5
DOWNLOAD_DELAY = 0.2
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.75 Safari/537.36'
}
第十步:创建主文件,运行爬虫项目
在items.py的同级目录下创建guazi_main.py文件:
from scrapy import cmdline
cmdline.execute('scrapy crawl guazi_spider'.split(' '))
最终的项目目录层级如下图:
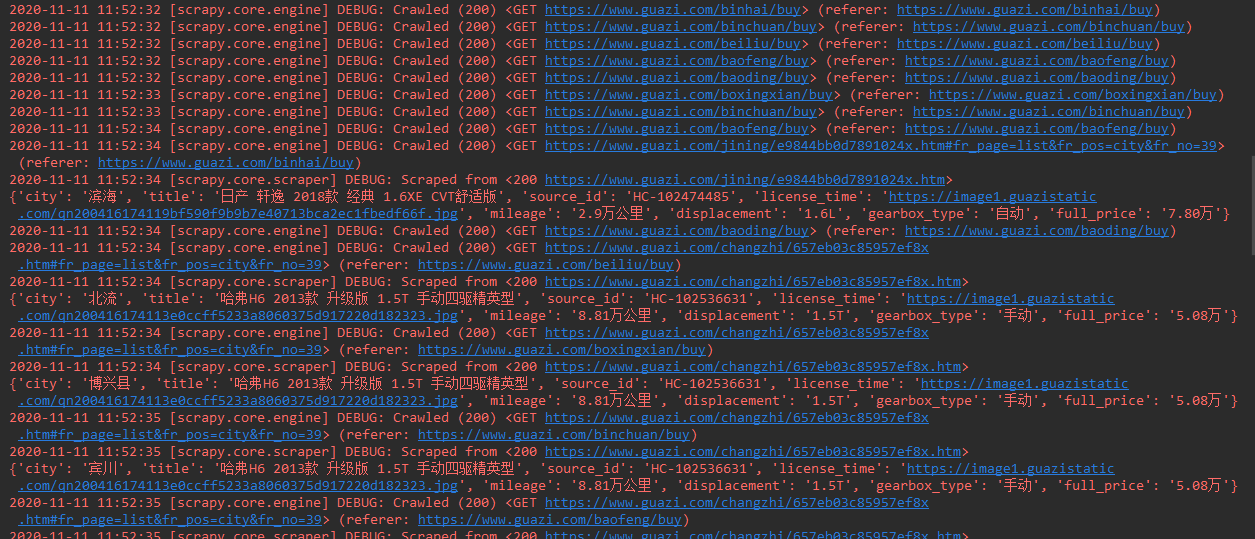
运行guazi_main.py文件,查看控制台输出及数据库数据(由于我没有付费ip代理,且为了测试的速度,该测试结果为未开启付费代理,且注释了解析品牌、翻页等内容后的结果):
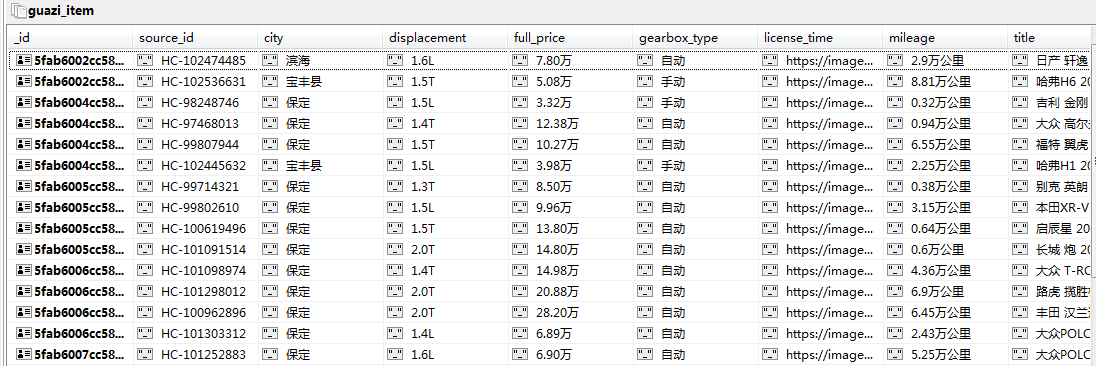
可以看到,成功抓取到了数据并存入了mongodb数据库。
项目到此结束。
后续可优化:
一:由于瓜子二手车网站二手车数据很多,为了提升抓取效率,可部署分布式爬虫(暂无结果,我调试了好几天,分布式也没有成功,问题可能出在了python版本的异同性上,后续有时间有机会了在重新尝试一下)
二:存入mongodb数据库的去重原则是通过数据库的update语句的特性来操作的,这种方式在数据量少的时候没有问题,但如果数据量很大,则查询就会很消耗时间,严重影响爬取效率,可能的解决方式:集成bloomfilter到scrapy-redis中,大大提升去重的效率(这种方式我暂时还不会,有待学习)


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】