


UE如何使用正则表达式
1 基本概念
元字符:
|
元字符 |
说明 |
|
. |
匹配除换行符以外的任意字符 |
|
\w |
匹配字母或数字或下划线或汉字 |
|
\s |
匹配任意的空白符() |
|
\d |
匹配数字 |
|
\b |
匹配单词的开始或结束 |
|
\W |
匹配任意不是字母,数字,下划线,汉字的字符 |
|
\S |
匹配任意不是空白符的字符 |
|
\D |
匹配任意非数字的字符 |
|
\B |
匹配不是单词开头或结束的位置 |
|
^ |
匹配行首 |
|
$ |
匹配行尾 |
字符转义
如果您想查找元字符本身的话,需要使用"\"来转意。例如"."代表除换行以外的任意字符,如果您想搜索"."这个字符的话,需要这样使用"\."。
重复
|
语法 |
说明 |
|
* |
重复零次或更多次 |
|
+ |
重复一次或更多次 |
|
? |
重复零次或一次 |
|
{n} |
重复n次 |
|
{n,} |
重复n次或更多次 |
|
{n,m} |
重复n到m次 |
字符集
若要匹配aeiou五个字符中的任意一个,可以表示成[aeiou]。再如[0-9]表示0到9之间的任意一个数字,它的含义和元字符中的\d实际上是一样的。
反意
如果要匹配非a则[^a],除aeiou五个字母之外的表示成[^aeiou],
贪婪与止贪
设有字符串dveadebcadefboipi,正则表达式a.*b,表达式的意思是匹配由a开始中间包含任意多个字符并以b结尾,这个表达式匹配出来的结果是adebcadefb,而不会是adeb,我们称这种匹配为贪婪匹配,因为它匹配了尽可能多的字符。要防止这种贪婪匹配,使用"?",把上面的表达式写成a.*?b的话,匹配出来的结果就是adeb了。
2 常用整个表达式
行首空格: ^\s+
行尾空格:\s+$
IP地址:[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}
正整数: ^[1-9]\d*$
负整数: ^-[1-9]\d*$
3 应用实例
例1 我想给一首诗的最后一行都加上逗号, ^p表示匹配一个换行符 (CR/LF) (段落) (DOS 文件),所以把"^p"替换成", ^p"就是说找到所有的换行符,替换成逗号+换行符,所以这样替换之后就成了除了最后一行(没有换行符)其他都加上了逗号.(注意在MAC和Linux中是^p 和^r)

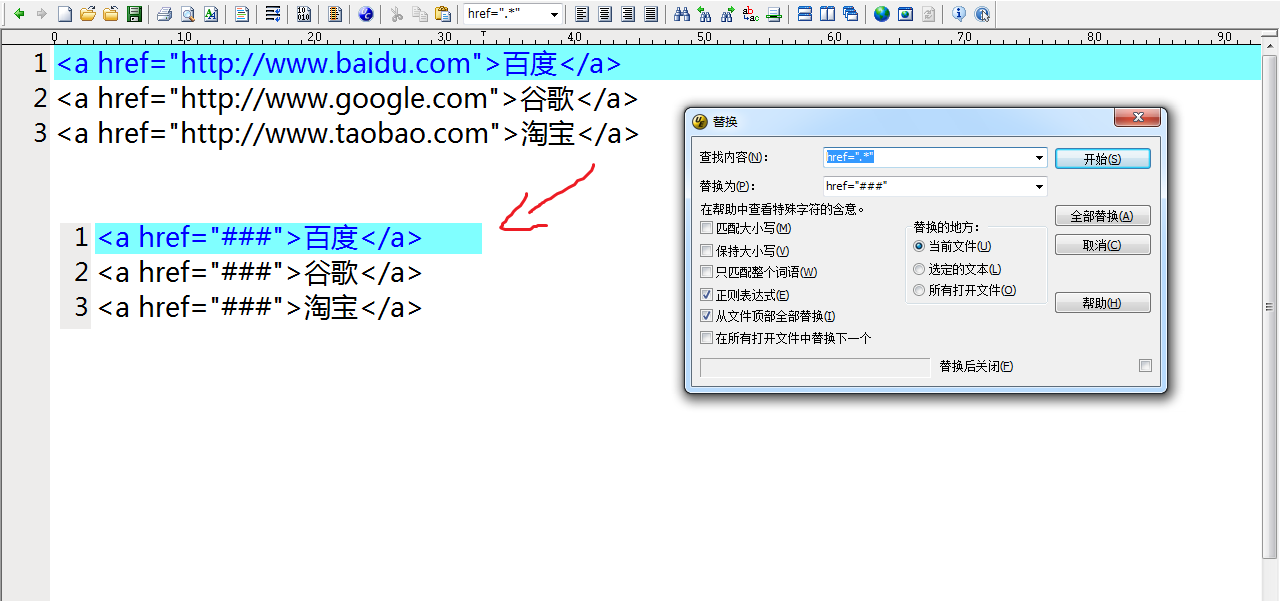
例2 我从网上拷贝的HTML源文件的超链接想要全部替换成href="###" 可以查找href=".*",别忘了.表示任意字符(除了换行符),*表示匹配任意次数,所以".*"就是不管双引号里面的是什么都匹配,所以得到了想要的结果
例3 我想在"第一章 第二章 第三章"这样的标题前面加上》》,需要用到分组,就是保护这么几个东西不替换,(当然你也可以把"第"字都替换成"》》第")
例4 我要提取一个文本文件的所有电话号码和电子邮件地址并保存到新的文件。

