数据采集与融合技术作业四
作业①
实验要求及结果
- 要求
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board - 代码
点击查看代码
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import mysql.connector
import time
class StockSpider:
def __init__(self):
chrome_options = Options()
chrome_options.add_argument("--headless")
chrome_options.add_argument("--disable-gpu")
self.driver = webdriver.Chrome(options=chrome_options)
# MySQL 连接
self.db = mysql.connector.connect(
host="127.0.0.1",
port="33068",
user="root",
password="160127ss",
database="spydercourse"
)
self.cursor = self.db.cursor()
def setup_db(self):
# 创建表格
self.cursor.execute("DROP TABLE IF EXISTS stock")
self.cursor.execute("""
CREATE TABLE stock (
id INT AUTO_INCREMENT PRIMARY KEY,
bStockNo VARCHAR(50),
stockname VARCHAR(255),
lastest_price DECIMAL(10, 2),
ddf DECIMAL(10, 2),
dde DECIMAL(10, 2),
cjl VARCHAR(64),
cje VARCHAR(64),
zhenfu DECIMAL(10, 2),
top DECIMAL(10, 2),
low DECIMAL(10, 2),
today DECIMAL(10, 2),
yestd DECIMAL(10, 2)
)
""")
def close(self):
self.db.commit()
self.cursor.close()
self.db.close()
self.driver.quit()
def insert_data(self, data):
# 插入数据
sql = """
INSERT INTO stock (bStockNo, stockname, lastest_price, ddf, dde, cjl, cje, zhenfu, top, low, today, yestd)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
self.cursor.execute(sql, data)
def fetch_data(self, url, page_limit=5, current_page=1):
if current_page > page_limit:
print(f"Reached page limit of {page_limit} pages for {url}.")
return # 达到页面限制后停止递归
self.driver.get(url)
WebDriverWait(self.driver, 10).until(
EC.presence_of_all_elements_located(
(By.XPATH, "//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr"))
)
rows = self.driver.find_elements(By.XPATH,
"//div[@class='listview full']/table[@id='table_wrapper-table']/tbody/tr")
for row in rows:
try:
bStockNo = row.find_element(By.XPATH, ".//td[2]/a").text
stockname = row.find_element(By.XPATH, ".//td[3]/a").text
lastest_price = float(row.find_element(By.XPATH, ".//td[5]/span").text)
# 去掉百分号并转换为 float
ddf = float(row.find_element(By.XPATH, ".//td[6]/span").text.replace('%', ''))
dde = float(row.find_element(By.XPATH, ".//td[7]/span").text.replace('%', ''))
cjl = row.find_element(By.XPATH, ".//td[8]").text
cje = row.find_element(By.XPATH, ".//td[9]").text
zhenfu = float(row.find_element(By.XPATH, ".//td[10]").text.replace('%', ''))
top = float(row.find_element(By.XPATH, ".//td[11]/span").text)
low = float(row.find_element(By.XPATH, ".//td[12]/span").text)
today = float(row.find_element(By.XPATH, ".//td[13]/span").text)
yestd = float(row.find_element(By.XPATH, ".//td[14]").text)
# 插入数据
self.insert_data(
(bStockNo, stockname, lastest_price, ddf, dde, cjl, cje, zhenfu, top, low, today, yestd))
except Exception as e:
print("Error fetching row data:", e)
continue
# 处理分页
try:
next_page = self.driver.find_element(By.XPATH, "//a[@class='next paginate_button']")
next_page.click()
time.sleep(2)
# 递归调用以抓取下一页数据,并将当前页数加1
self.fetch_data(url, page_limit, current_page + 1)
except:
print("No more pages to load.")
def scrape(self, urls):
self.setup_db()
for url in urls:
self.fetch_data(url)
self.close()
if __name__ == "__main__":
urls = [
"http://quote.eastmoney.com/center/gridlist.html#hs_a_board", # 沪深A股
"http://quote.eastmoney.com/center/gridlist.html#sh_a_board", # 上证A股
"http://quote.eastmoney.com/center/gridlist.html#sz_a_board" # 深证A股
]
spider = StockSpider()
spider.scrape(urls)
- 运行结果
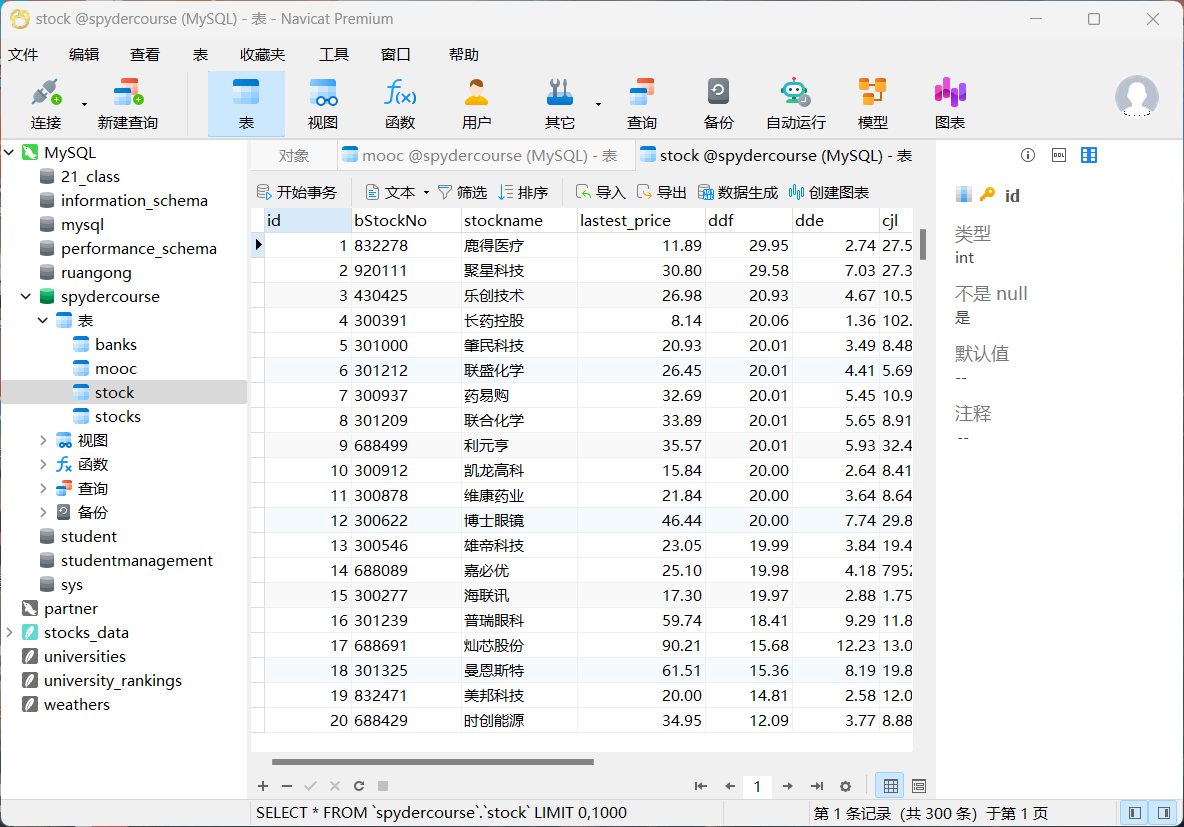
心得体会
一些网页内容是通过 JavaScript 动态加载的,导致页面加载完成后需要等待数据才能抓取。解决方案是通过 WebDriverWait 和 expected_conditions 等方法来确保元素已经加载并且可操作。
作业②
实验要求及结果
- 要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式 - 代码:
点击查看代码
from selenium.webdriver.common.by import By
from selenium import webdriver
import time
import pymysql
import mysql.connector
# MySQL数据库连接
conn = mysql.connector.connect(
host="127.0.0.1",
port="33068",
user="root",
password="160127ss",
database="spydercourse"
)
cursor = conn.cursor()
# 创建MOOC表格
cursor.execute("""
CREATE TABLE IF NOT EXISTS mooc (
Id VARCHAR(20),
cCourse VARCHAR(100),
cCollege VARCHAR(100),
cTeacher VARCHAR(100),
cTeam VARCHAR(200),
cCount INT,
cProcess VARCHAR(100),
cBrief TEXT
)
""")
conn.commit()
# 插入数据的SQL语句
sql = """
INSERT INTO mooc (Id, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
# 用户登录信息输入
n = 1
user_name = "18150061218"
password = "685332Ss"
# 启动浏览器并打开页面
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument("--headless")
driver = webdriver.Chrome(options=chrome_options)
driver.maximize_window()
driver.get("https://www.icourse163.org/")
# 点击同意隐私政策
load = driver.find_element(By.XPATH, '//*[@id="app"]/div/div/div[1]/div[3]/div[3]/div')
load.click()
time.sleep(3)
# 切换到登录 iframe
iframe = driver.find_element(By.XPATH, '/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
# 输入账号密码并登录
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[2]/div[2]/input').send_keys(user_name)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]').send_keys(password)
driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a').click()
# 等待页面加载完成
time.sleep(5)
driver.switch_to.default_content() # 切换回默认页面
time.sleep(3)
# 同意隐私政策
driver.find_element(By.XPATH, '//*[@id="privacy-ok"]').click()
# 进入课程页面
driver.find_element(By.XPATH, '/html/body/div[4]/div[2]/div[1]/div/div/div[1]/div[1]/div[1]/span[1]/a').click()
driver.switch_to.window(driver.window_handles[-1])
# 分页循环获取课程数据
for _ in range(2):
for i in range(5):
try:
# 获取每个课程的基本信息
course_info = driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]/div/div[3]/div[1]').text.split("\n")
driver.find_element(By.XPATH, f'//*[@id="channel-course-list"]/div/div/div[2]/div[1]/div[{i+1}]').click()
# 切换到新打开的课程页面
driver.switch_to.window(driver.window_handles[-1])
# 获取团队成员
team = driver.find_elements(By.XPATH, '//*[@class="f-fc3"]')
team_list = [t.text for t in team]
course_info.append(','.join(team_list))
# 获取课程人数
try:
count = driver.find_element(By.XPATH, '//*[@class="count"]').text
except:
count = "已有0人参加"
course_info.append(count[2:-3]) # 处理人数字段
# 获取课程时间
try:
date = driver.find_element(By.XPATH, '//*[@id="course-enroll-info"]/div/div[1]/div[2]/div/span[2]').text
except:
date = "无"
course_info.append(date)
# 获取课程简介
brief = driver.find_element(By.XPATH, '//*[@id="j-rectxt2"]').text
course_info.append(brief)
# 插入数据库
values = (n, course_info[0], course_info[1], course_info[2], course_info[3], course_info[4], course_info[5], course_info[6])
cursor.execute(sql, values)
conn.commit()
# 记录数据并关闭当前标签页
n += 1
driver.close()
driver.switch_to.window(driver.window_handles[-1]) # 切换回主标签页
except Exception as e:
print(f"错误:{e}")
driver.close()
driver.switch_to.window(driver.window_handles[-1])
# 点击下一页按钮
driver.find_element(By.XPATH, '//*[@id="channel-course-list"]/div/div/div[2]/div[2]/div/a[10]').click()
time.sleep(2)
# 关闭数据库连接
cursor.close()
conn.close()
- 截图
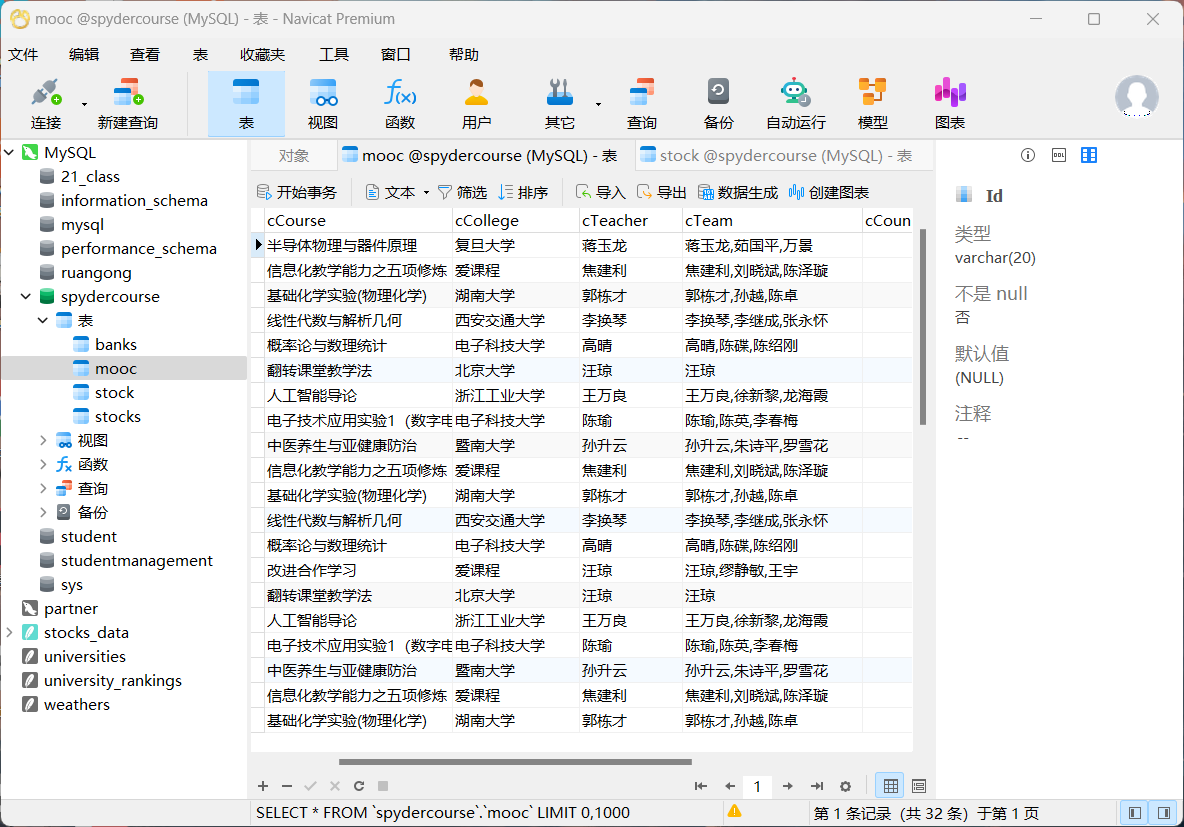
心得体会
一开始想要用搜索框输入课程关键词来实现,但是这种方法一直做不出来,就修改了一下,换成直接找课程来做,通过switch to frame来实现登录,然后回到主页加载课程来爬取,得到结果。
作业③
实验要求及结果
-
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
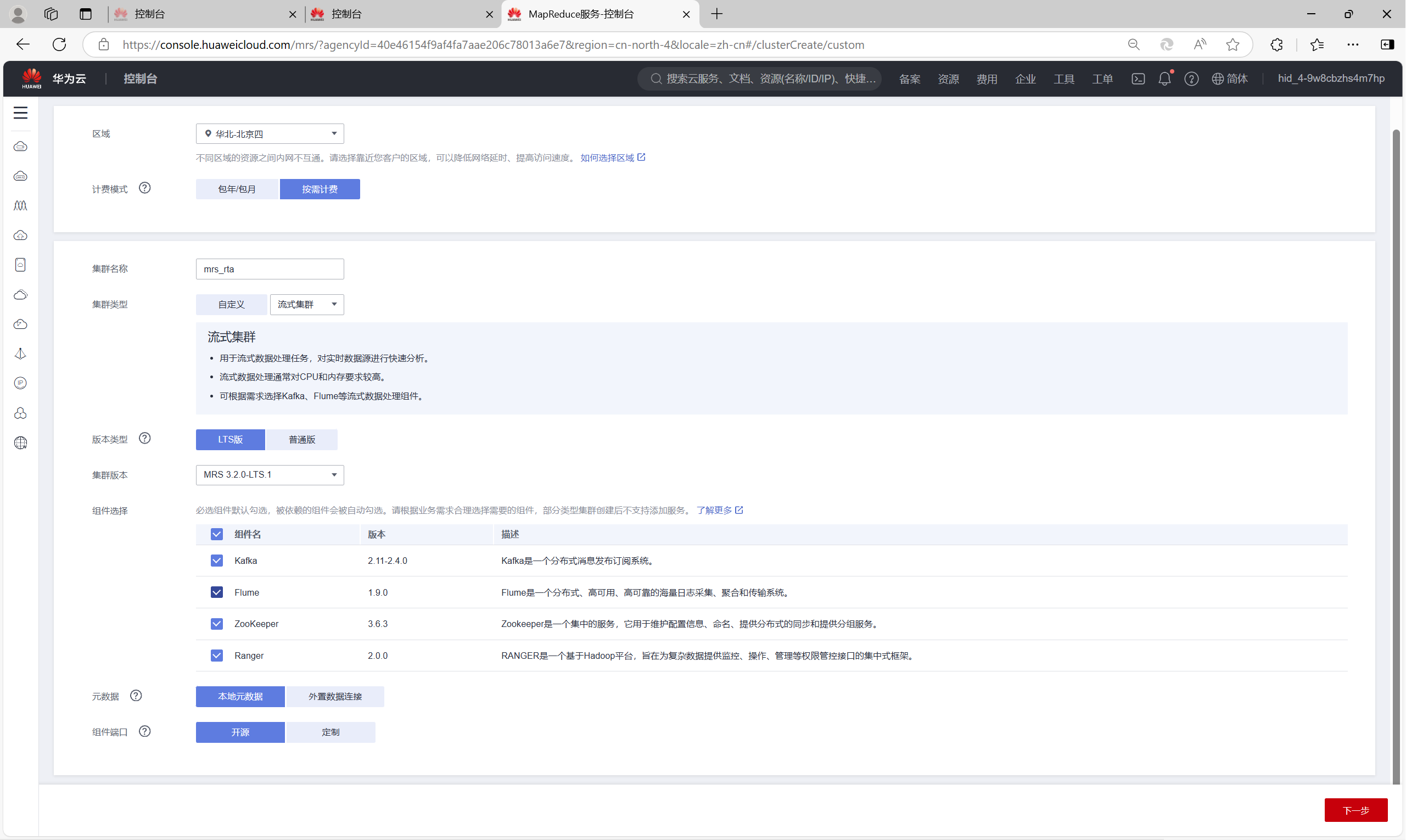
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据 -
运行结果:
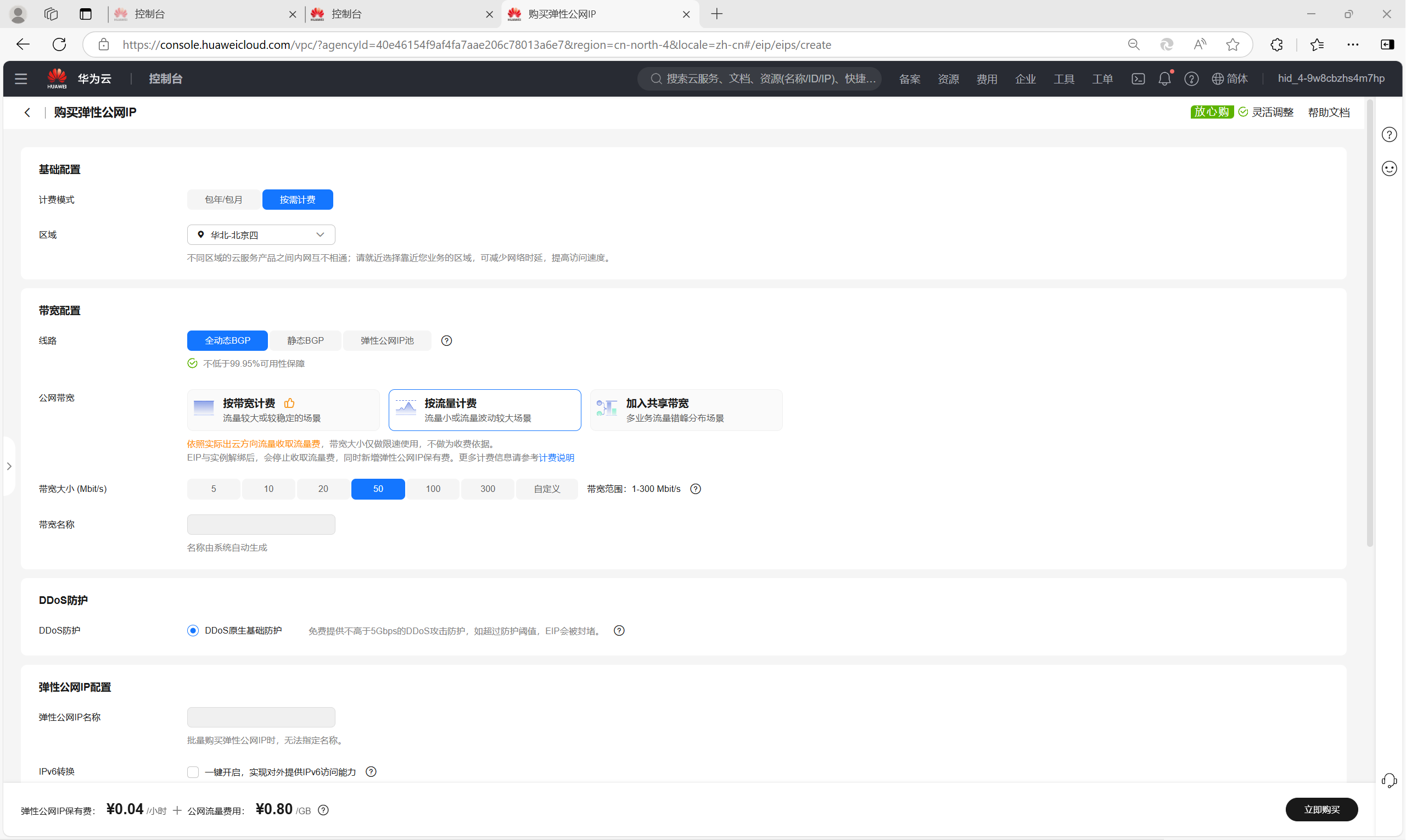
申请弹性公网IP
开通MapReduce服务
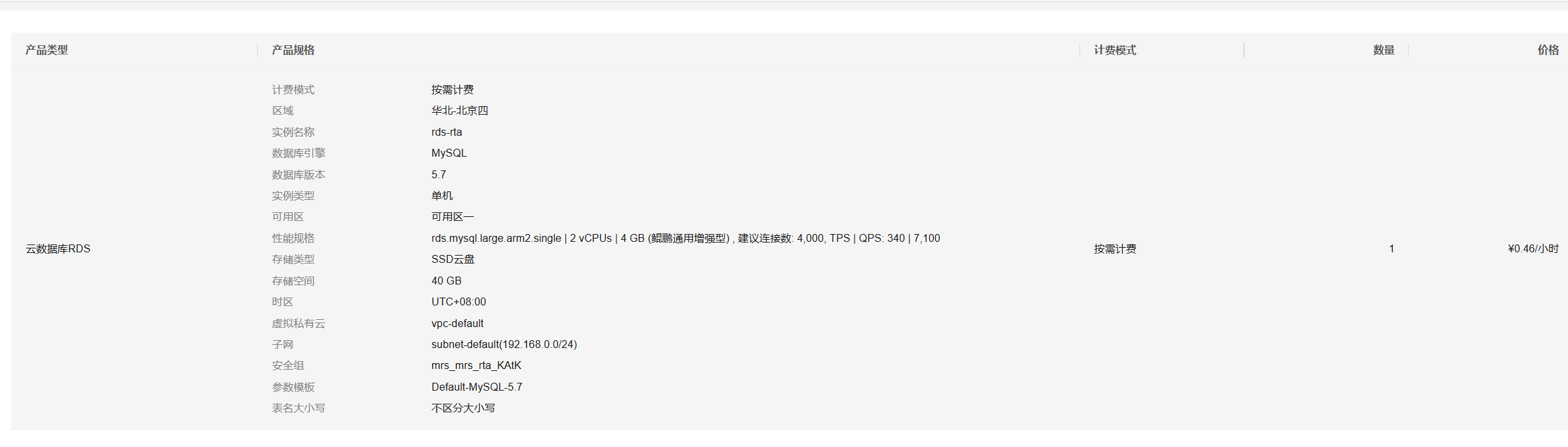
开通云数据库服务RDS
大数据实时分析开发实战
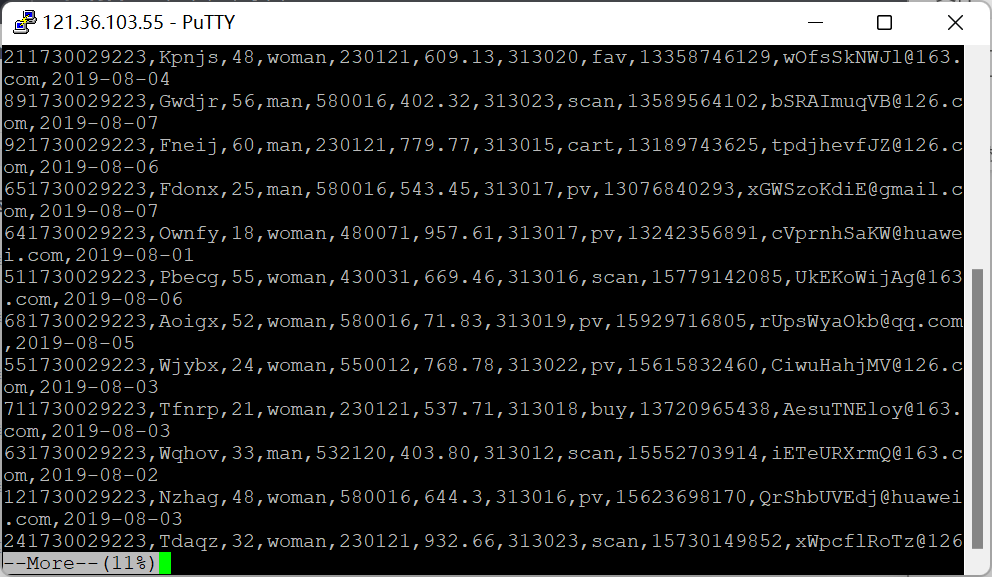
Python脚本生成测试数据
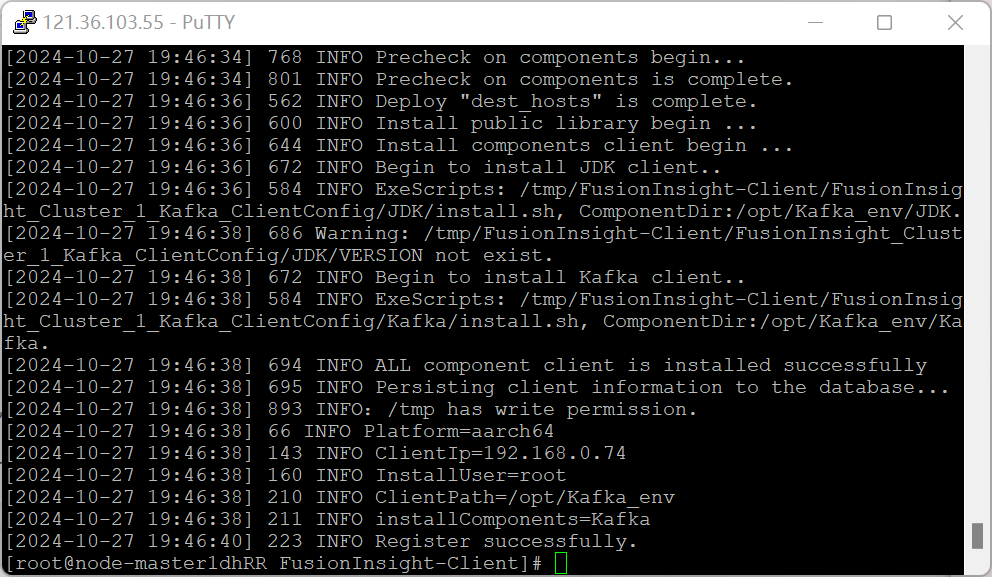
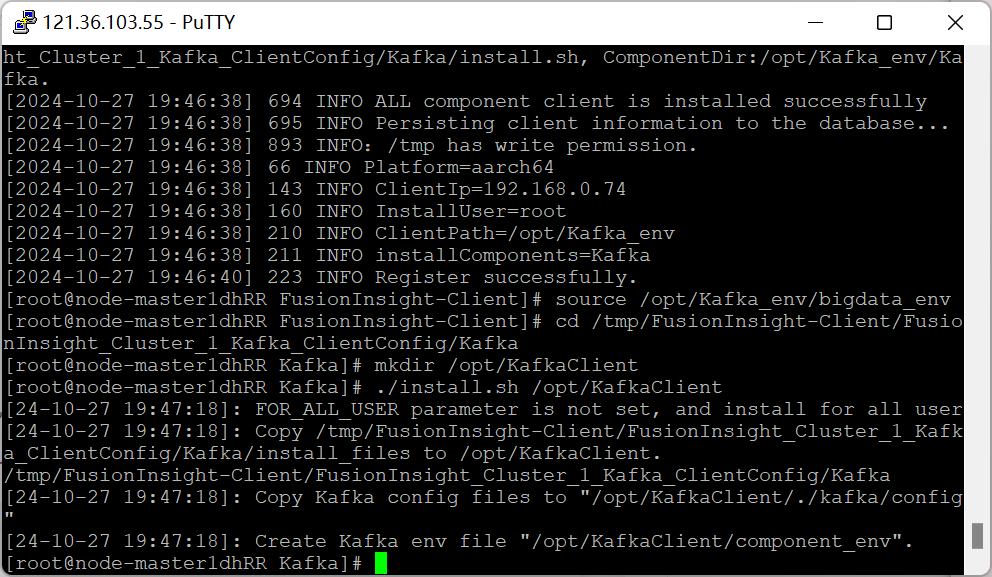
安装Kafka客户端
在kafka中创建topic


安装Flume客户端
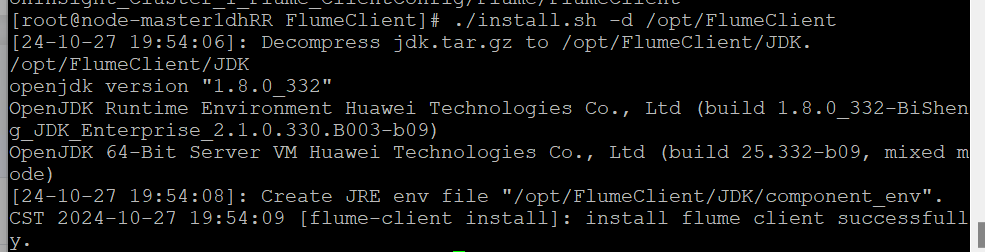
重启Flume服务
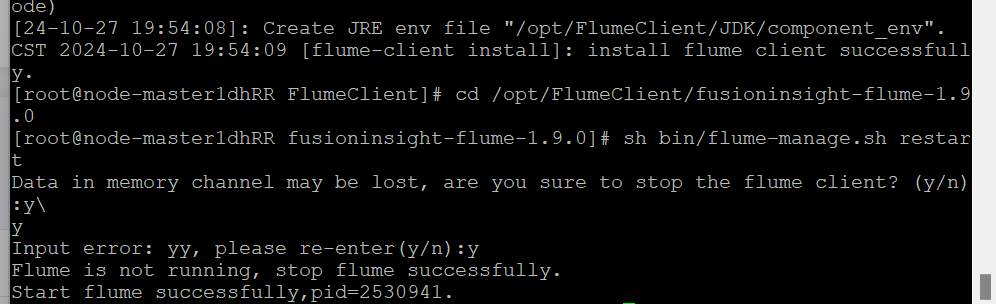
配置Flume采集数据
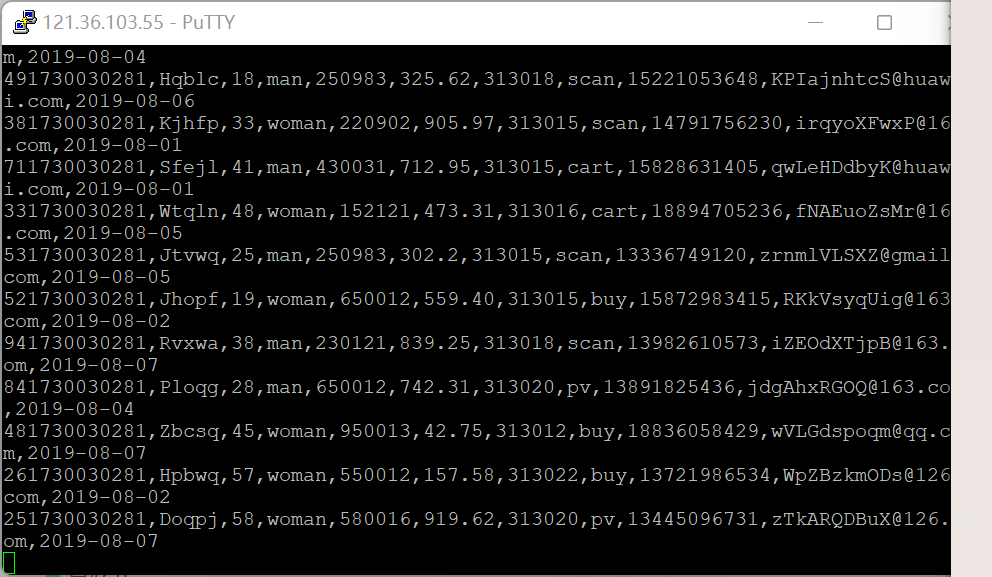
心得体会
通过这一系列实验,我不仅掌握了如何在云平台上配置和管理大数据服务,还深入理解了Kafka与Flume在大数据处理中的重要角色,特别是在实时数据流的采集、传输与分析方面。整个过程让我对大数据生态系统有了更加全面的认识,尤其是如何高效地利用现有工具和云平台资源,完成数据的实时处理和分析任务。在未来的工作中,我将继续探索和应用这些技术,以应对更加复杂的数据分析和处理任务。

