数据采集实践第一次作业
作业①:定向爬取大学排名信息
实验要求及结果
- 要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020)的数据,屏幕打印爬取的大学排名信息。 - 代码
点击查看代码
import requests
from bs4 import BeautifulSoup
# 目标网址
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
# 使用 requests 发送请求
response = requests.get(url)
response.encoding = 'utf-8' # 设置编码,确保中文字符显示正确
# 使用 BeautifulSoup 解析网页
soup = BeautifulSoup(response.text, 'html.parser')
# 找到包含大学排名的表格
table = soup.find('table', {'class': 'rk-table'})
# 输出标题
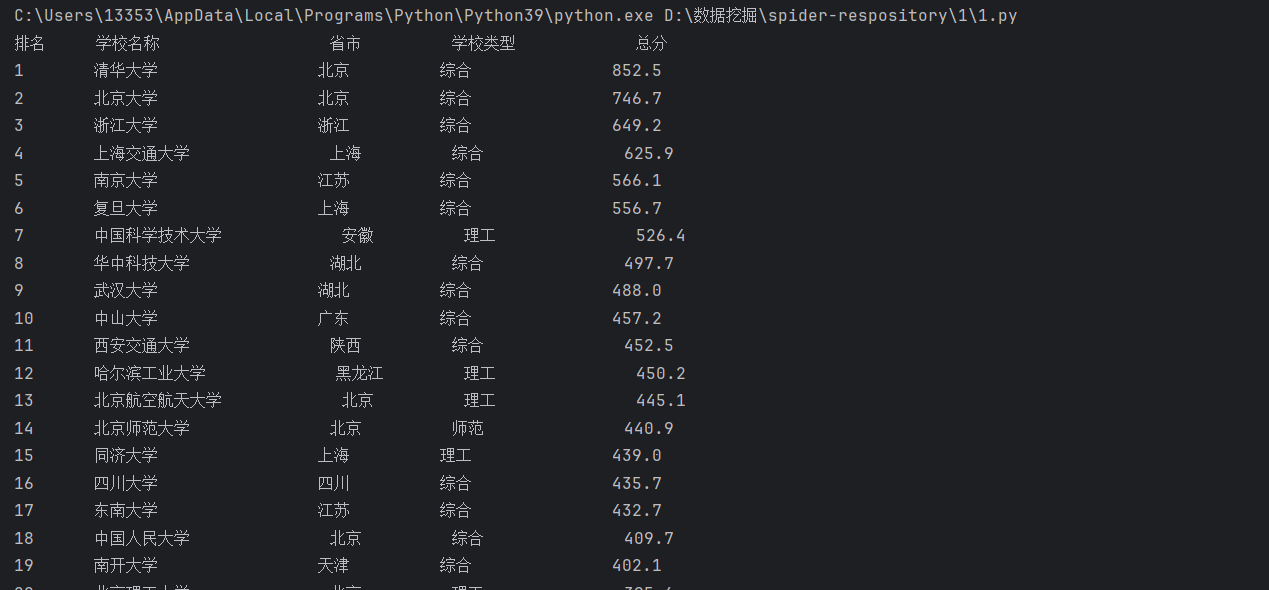
print(f"{'排名':<6} {'学校名称':<20} {'省市':<10} {'学校类型':<15} {'总分':<10}")
# 遍历表格中的每一行
for row in table.find('tbody').find_all('tr'):
cols = row.find_all('td')
# 提取每列数据
rank = cols[0].get_text().strip() # 排名
name = cols[1].get_text().split('\n')[0] # 学校名称,提取中文部分
province = cols[2].get_text().strip() # 省市
category = cols[3].get_text().strip() # 学校类型
score = cols[4].get_text().strip() # 总分
# 打印每一行数据
print(f"{rank:<6} {name:<20} {province:<10} {category:<15} {score:<10}")
- 运行结果
心得体会
-
HTML结构:
通过观察HTML结构,可以确定排名、学校名称、省份/城市等信息分别位于哪个标签内,准确地定位和提取所需的数据。 -
正则表达式:
在本例中,正则表达式用于匹配中文字符,但如果网页结构发生变化,可能需要调整正则表达式 -
输出对齐:
我么需要去除多余的空格以及将换行符替换掉,或者如上述代码,根据换行符分词仅保留中文部分。
作业②:商城商品比价定向爬虫
实验要求及结果
- 要求:
使用 requests 和 re 库方法设计某个商城(自选)商品比价定向爬虫,爬取该商城以关键词“书包”搜索页面的数据,包括商品名称和价格。 - 代码:
点击查看代码
# 用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
import urllib.parse
import random
import requests
import time
import re
# 设置请求头,伪装成浏览器请求
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0',
'cookie' : '__jdu=17182719663141198906466; shshshfpa=937e652f-a425-de5a-c233-6df524418ad2-1718271970; shshshfpx=937e652f-a425-de5a-c233-6df524418ad2-1718271970; TrackID=1YNbU9FIZd00BWHMDtajlJDz4quPpa1lrPhRvcSiVgltmvXLoAIyPaOb8zXS3RQnjdU2jxdQLGi2-UWCHqdyW0fiLoKP_NXdJtYIm1qvAa0qcquV3fsvHQTEAfQYapPHW; thor=FC0DA1BB1CB59DA1B77A0DF3C3FA4632065CAC1BDA37A6C8D73ADD6607C01200908EAF9AD5A06D6065A64185A5CDB9FEC4A2F7A21D2533BB3DB822DEDDD01B6880B6830B4831088884FFFD1893245574E49EDB536C13A74F76E645224DA275C42453B4225496F2B1F428F61C6FA0767B3CAFB8781E4E009736A1BC05D3945645DB66F3D6BA8037DFADBC787B03BCCF2C24EAEA453E41FB8D0E004DDD8316D751; light_key=AASBKE7rOxgWQziEhC_QY6ya6gDvFukmW0NqWdW4cfuCVgpBy7NJVLYpr8DgG10YJc9-oZDb; pinId=c__mwLI5rc1OFi8nFqZWvw; pin=jd_PFdPlGuLMlzn; unick=jd_48giwwpv953xn4; _tp=UzQYIRktqRpEFW1%2BilHcTw%3D%3D; _pst=jd_PFdPlGuLMlzn; unpl=JF8EALNnNSttUExUUR4EG0USTQ5SWwgASx8AZzMEBFkITF0EHFUbQRl7XlVdWBRKHx9sZBRUVVNJUg4eAysSEXteU11bD00VB2xXVgQFDQ8WUUtBSUt-S1tXV1QOSh4AbGYDZG1bS2QFGjIbFBBCXlJeVQ9MFQNqZwVcVFBKUwAcBSsTIExtZG5bC0MRC19mNVVtGh8IDBIBGxcWBl1SXlQLTRcLaGAHVFhYS1wMEwMcFxdMbVVuXg; cn=0; jsavif=1; __jda=143920055.17182719663141198906466.1718271966.1727856159.1728974438.6; __jdc=143920055; __jdv=143920055|direct|-|none|-|1728974438017; 3AB9D23F7A4B3CSS=jdd032K7FJM4XCTA2C44ZZ753Y6AA5EDECIJU522H6UVHKKPWGHA5R4MXY27Z6AUWAQKUM57FZQBNIGN2T3I2NRVGIZ6PNUAAAAMSR3UEAGAAAAAADEJW5LRWMNY52MX; _gia_d=1; flash=3_ZlDdVjQe6D225JYOtB9b0pzG_EB3m2kmv2YDaca6mmIIgKGJk_rZcZCIl7nLLYhUtOe1exVlTzAP47tlC9tpGO3nWPJJ6bphrVcGm0yZ0A7Mag5WZsOqCg2Yog-f_rIfXJduGE-odM6jNYJkj0egbHbV1m0IX9vSUJSgBJZUZ_wwg4pQ_3cA; areaId=16; ipLoc-djd=16-1317-0-0; __jdb=143920055.2.17182719663141198906466|6.1728974438; shshshfpb=BApXSCsjgjfdAiMs_VmIw7nD6BIKfhzsIBlpmHl9q9xJ1MjnM8oC2; 3AB9D23F7A4B3C9B=2K7FJM4XCTA2C44ZZ753Y6AA5EDECIJU522H6UVHKKPWGHA5R4MXY27Z6AUWAQKUM57FZQBNIGN2T3I2NRVGIZ6PNU'
}
keyword = '书包'
encoded_keyword = urllib.parse.quote(keyword)
# 创建空的列表以存储商品信息
product_list = []
time.sleep(random.uniform(3, 5))
page = 1
# 设置搜索页面的URL
url = f'https://search.jd.com/Search?keyword={encoded_keyword}&page={page}'
print(url)
# 发送GET请求获取页面数据
response = requests.get(url, headers=headers)
time.sleep(random.uniform(1, 3))
# 检查响应状态
if response.status_code == 200:
# 将网页源码解码为utf-8格式
html_content = response.text
# 打印部分HTML内容以查看页面结构
# print(html_content)
# 进行正则匹配等后续处理
product_name_pattern = r'<div class="p-name.*?">.*?<a.*?>\s*<em>(.*?)</em>'
price_pattern = r'<div class="p-price">.*?<i.*?>([\d\.]+)</i>'
# 提取商品名称列表
product_names = re.findall(product_name_pattern, html_content, re.S)
# 提取商品价格列表
prices = re.findall(price_pattern, html_content, re.S)
# print(prices)
# 清洗数据,去掉HTML标签
clean_product_names = [re.sub(r'<.*?>', '', name).strip() for name in product_names]
# 输出信息,按照要求格式化输出
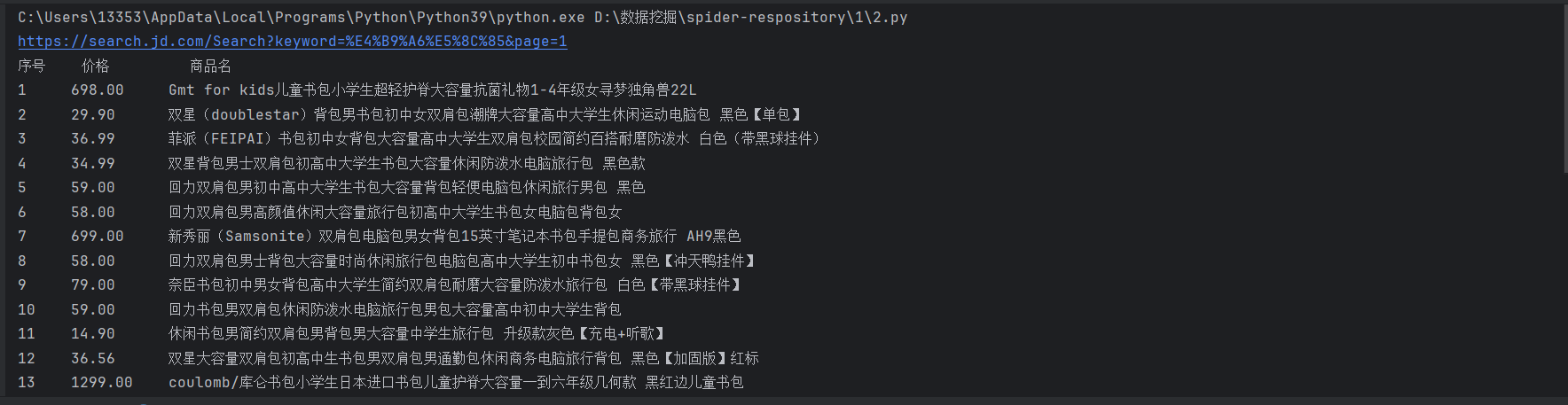
print(f"{'序号':<5} {'价格':<10} {'商品名'}")
for index, (name, price) in enumerate(zip(clean_product_names, prices), 1):
print(f"{index:<5} {price:<10} {name}")
else:
print(f"请求失败,状态码: {response.status_code}")
- 截图
心得体会
- 正则表达式的灵活性:通过练习,我加深了对正则表达式的掌握,特别是在从复杂网页中提取关键数据时。
- 数据抓取的合规性:开发爬虫时,我认识到应遵守网站的爬取规则,尊重网站的版权及用户隐私,保持数据抓取的合法性。
作业③:爬取网页中的JPEG和JPG格式图片
实验要求及结果
- 要求:
爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件 - 代码:
点击查看代码
import os
import requests
from bs4 import BeautifulSoup
# 设置要爬取的网页URL
url = 'https://news.fzu.edu.cn/yxfd.htm'
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 创建保存图片的文件夹
folder_name = 'images' # 可以更改为你想要的文件夹名
os.makedirs(folder_name, exist_ok=True)
# 找到所有的<img>标签
img_tags = soup.find_all('img')
# 遍历所有的<img>标签
for img in img_tags:
img_url = img.get('src') # 获取图片的src属性
# 检查图片链接是否为JPEG或JPG格式
if img_url.endswith(('.jpg', '.jpeg')):
# 如果是相对路径,则转换为绝对路径
if img_url.startswith('/'):
img_url = f'https://news.fzu.edu.cn/{img_url}'
# 下载图片
img_data = requests.get(img_url).content
img_name = os.path.join(folder_name, os.path.basename(img_url))
# 保存图片
with open(img_name, 'wb') as f:
f.write(img_data)
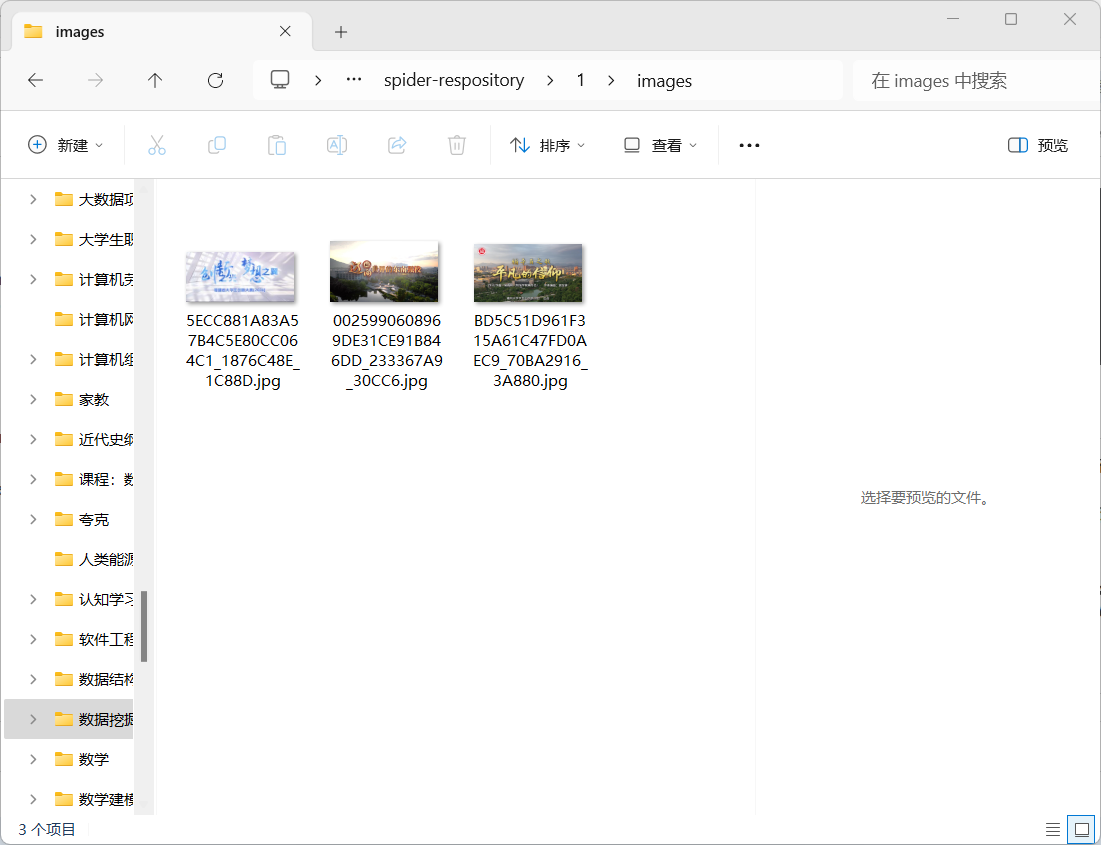
print(f'已保存图片: {img_name}')
else:
print(f'请求失败,状态码: {response.status_code}')
- 运行结果:
心得体会
- 请求与解析的结合:通过此次实验,我学会了如何结合 HTTP 请求和 HTML 解析,使爬虫程序的爬取能力和数据处理能力有机结合。
- 图片下载的实践:图片下载不仅涉及 URL 提取,还需要处理本地文件存储问题,这让我加深了对文件操作的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号