C++内存对齐
内存对齐:计算机中内存的地址空间是按照 byte 来划分的,从理论上讲对任何类型变量的访问可以从内存中的任意地址开始,但实际情况是:在访问特定类型变量的时候通常在特定的内存地址访问,这就需要对这些数据在内存中存放的位置进行限制,各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。编译器将程序中的每个 数据单元 的地址安排在机器字的整数倍的地址指向的内存之中。
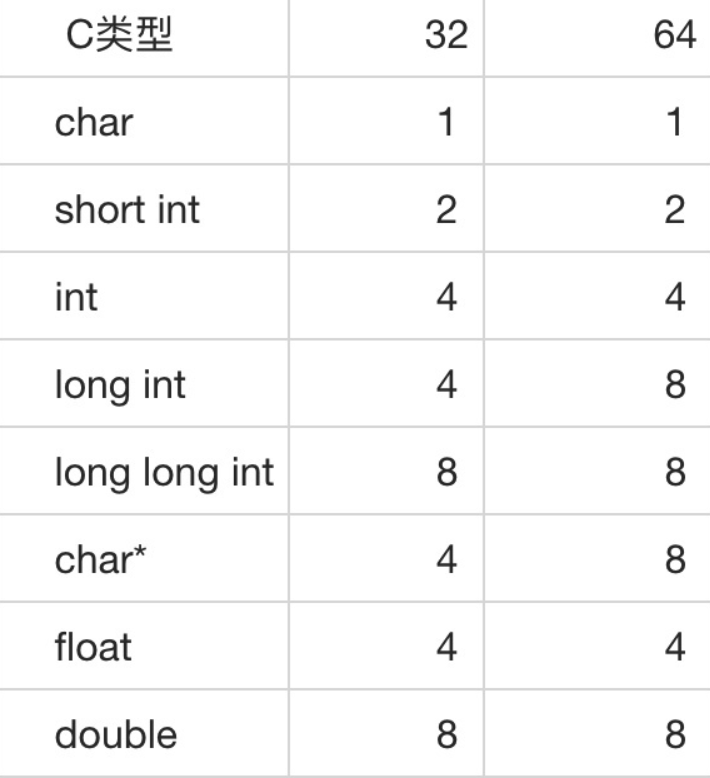
内存对齐的原因:主要是由于 CPU 的访问内存的特性决定,CPU 访问内存时并不是以字节为单位来读取内存,而是以机器字长为单位,实际机器字长由 CPU 数据总线宽度决定的。实际 CPU 运行时,每一次控制内存读写信号发生时,CPU 可以从内存中读取数据总线宽度的数据,并将其写入到 CPU 的通用寄存器中。比如 32 位 CPU,机器字长为 4 字节,数据总线宽度为 32 位,如果该 CPU 的地址总线宽度也是为 3232 位,则其可以访问的地址空间为 [0,0xffffffff]。内存对齐的主要目的是为了减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。
其他原因:
1.某些特定的硬件设备只能存取对齐数据,存取非对齐的数据可能会引发异常,比如对于 CPU 中 SIMD 指令,则必须要求内存严格对齐;
2.每次内存访问是原子的,如果变量的大小不超过字长,那么内存对齐后,对该变量的访问就是原子的。某些硬件设备不能保证在存取非对齐数据的时候的操作是原子操作,因此此时 CPU 需要可能需要读取多次内存,这样就破坏了变量的原子性;
3.相比于存取对齐的数据,存取非对齐的数据需要花费更多的时间,提高内存的访问效率,因为 CPU 在读取内存时,是一块一块的读取。
4.某些处理器虽然支持非对齐数据的访问,但会引发对齐陷阱
5.某些硬件设备只支持简单数据指令非对齐存取,不支持复杂数据指令的非对齐存取。
内存对齐原则:程序中的内存对齐大部分都是由编译器来处理,编译器会自动在内存之间填充字节。结构体中的变量对齐的基本规则如下:
- 结构体变量的首地址能够被其最宽的基本类型成员的长度和对齐基数二者中的较小者所整除;
-
结构体中的 static 成员变量不占用结构体的空间,由于静态成员变量在程序初始化时已经在静态存储区分配完成,所有该结构体实例中的静态成员都指向同一个内存区域;
-
结构体每个成员相对于结构体首地址的偏移量 (offset) 都是该成员大小与对齐基数中的较小者的整数倍,如有需要编译器会在成员之间加上填充字节 (internal padding);
-
结构体的总大小为结构体中最宽基本类型成员的长度与对齐基数二者中的较小者的整数倍,如有需要编译器会在最末尾的成员之后加上填充字节 (trailing padding);
指定程序对齐规则:可以指定结构体的对齐规则,在某些特定场景下我们需要指定结构体内存进行对齐,比如在发送特定网络协议报文、硬件协议控制、消息传递、硬件寄存器访问时,这时就就需要避免内存对齐,因为双方均按照预先定义的消息格式来进行交互,从而避免不同的硬件平台造成的差异,同时能够将双方传递的数据进行空间压缩,避免不必要的空间浪费。
programpack: 我们可以用 #progma pack(x) 指定结构体以 xx 为单位进行对齐。一般情况下我们可以使用如下:
内存对齐使得程序便于在不同的平台之间进行移植,因为有些硬件平台不能够支持任意地址的数据访问,只能在某些地址处取某些特定的数据,否则会抛出异常;另一方面提高内存的访问效率,因为 CPU 在读取内存时,是以块为单位进行读取。
内存对齐的对齐数取决于对齐系数和成员的字节数两者之中的较小值。对齐属性的有效性会受到链接器(linker)固有限制的限制,即如果你的链接器仅仅支持 8 字节对齐,即使你指定16字节对齐,那么它也仅仅提供 8 字节对齐。
内存对齐使得程序便于在不同的平台之间进行移植,因为有些硬件平台不能够支持任意地址的数据访问,只能在某些地址处取某些特定的数据,否则会抛出异常;另一方面提高内存的访问效率,因为 CPU 在读取内存时,是以块为单位进行读取。
对齐陷阱:
struct T
{
char ch;
int i ;
};
int在32位以及64位机中是4个字节,char是1个字节,所以T一共是5个字节。sizeof(T)=8,计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,,这就是所谓的 内存对齐,而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型S的对齐要求比T强(严格),而称T比S弱(宽 松)。
这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。比如这么一种处理器,它每次读写内存的时候都从某个8倍数 的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,那么读或写一个double类型数据就只需要一次 内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐要求的8字节内存块上。某些处理器在数据不满足对齐要 求的情况下可能会出错,但是Intel的IA32架构的处理器则不管数据是否对齐都能正确工作。
在GNU GCC编译器中,遵循的准则有些区别,在GCC中,对齐模数的准则是:对齐模数最大只能是 4,也就是说,即使结构体中有double类型,对齐模数还是4,所以对齐模数只能是1,2,4。
typedef struct
{
char c:2;
double i;
int c2:4;
}N3;
在GCC下占据的空间为16字节,在VC下占据的空间应该是24个字节。对于采用压缩方式的编译器来说,遵循不含位域结构体内存对齐准则第2 条,不同的是,如果填充的3个字节能容纳后面成员的位,则压缩到填充字节中,不能容纳,则要单独开辟空间,所以上面结构体N在GCC或者Dev-C++中 所占空间应该是4个字节。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号